Xception MobileNet 톺아보기
수행능력을 향상시키기 위한 최고의 방법 : 모델의 깊이를 늘린다.
- parameter가 늘어남에 따라서 overfitting이 발생할수 있다.
- 계산량이 매우 많이 늘어난다.
Xception
` stack of depthwise separable convolution with residual connections`
Xception은 Inception에 기초를 두고 있고 sparse하게 네트워크의 구조를 생각하는데 중점을 둔다. 일반적인 convolution은 3차원 필터를 사용해 모든 correlation을 파악하려고 한다. 그래서 이를 sparse하게 해서 correlation을 더 잘 학습시키려는 것이다.
Inception Module
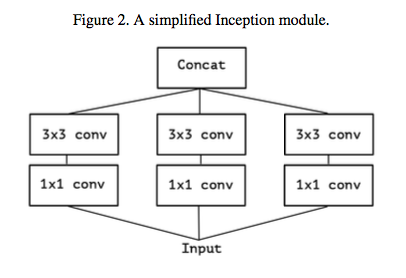
위와 아래는 같다.
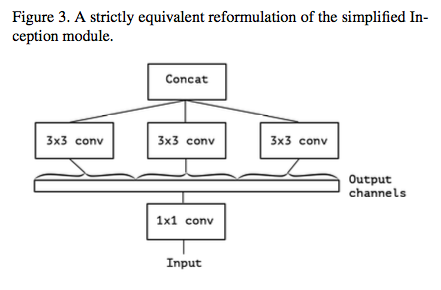
1x1 conv: 채널 간의 상관관계- 차원 축소 (Dimension reduction)
- 표현력이 증가(Increase the representational power)
3x3 conv: 공간, 방향 상관관계
Strong Inception Module
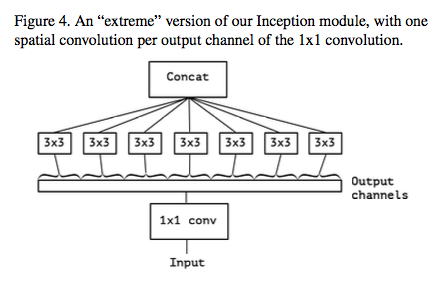
각 output channel 마다 spatial convolution을 적용했는데 이게 마치 depthwise separable convolution와 유사하다.
depthwise separable convolution
위와 같이 강력하게 만든 module과 depthwise separable convolution의 차이점은
- layer의 순서 : depthwise :
3x3 -> 1x1xception1x1 -> 3x3 - Non-linear : 활성화 함수를 취하지 않는다.
skip connection
resnet에서 사용되는 지름길을 만들어주는 기술이라고 생각하면 된다. 네트워크의 입력과 출력을 더해서 그 다음 layer에 입력으로 사용하는 것인데, 학습이 잘되고 속도가 향상되는 장점이 있다.
모델
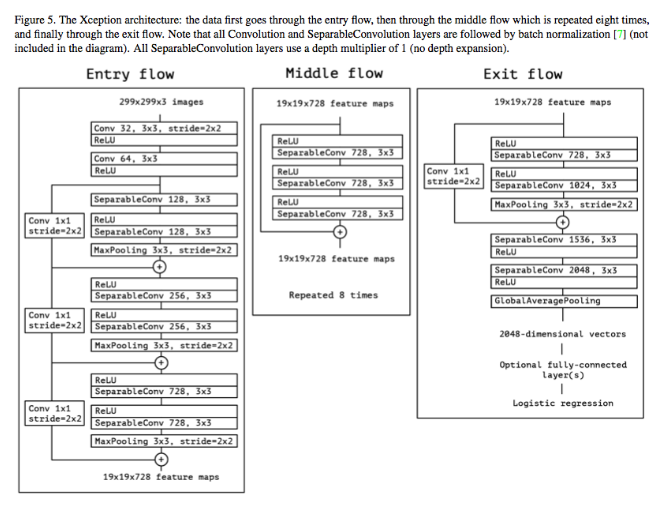
결론
depthwise separable convolution과 유사한 Strong Inception module을 만들었으며 그에 따라서 Inception v3 보다 성능이 좋아졌다.
모바일 환경에서 조건
모바일
- 안전에 치명적이다.(드론, 자동차)
- 저전력이어야 한다.
- 실시간이 요구된다.
네트워크
- 상당히 높은 정확성을 가져야 한다.
- 계산 복잡성이 낮아야한다.
- 모델 크기가 작아야한다.
Small Deep learning
- Fully Connected Layer를 제거한다.
- 커널을 줄인다.(3x3 -> 1x1) [squeezenet]
- 채널을 줄인다.
- Downsampling을 골고루 퍼지게 한다.(maxpooling)
- Depthwise Separable Convolution
- shuffle operation
- distillation and compression
MobileNet
모바일 환경에서 동작하게 하기 위해 모델의 사이즈를 줄이기 위함이 아니라 속도를 향상시키기 위해 만들어진 네트워크
key : depthwise separable convolution
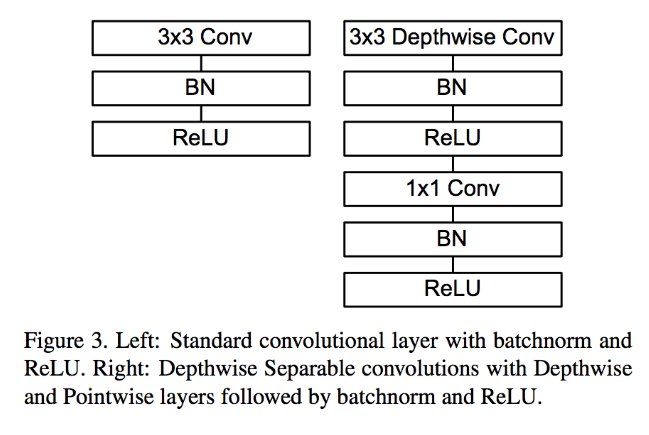
depthwise separable convolution = depthwise convolution + pointwise convolution
normal conv
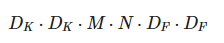
depthwise separable conv
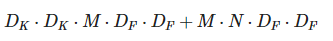
계산량 약 8~9배 줄어든다고 한다.
결론
계산량이 9배정도 줄어들고 accuracy는 약 1% 밖에 떨어지지 않았다.
VGG
3x3 필터만 사용한다. 3x3 필터만 사용해도 5x5 7x7과 같은 receptive field를 가질 수 있고 더욱더 non-linear 하기 때문에 효과적이다.
참조
Xception
- https://www.youtube.com/watch?v=V0dLhyg5_Dw
- https://norman3.github.io/papers/docs/google_inception.html
- https://gamer691.blogspot.com/2019/02/paper-review-xception-deep-learning.html
MobileNet
Inception
