[2026-02-10] P1-VL: 물리 올림피아드 정복을 위한 시각-논리 통합 인공지능의 탄생 (SOTA VLM 분석)

P1-VL: 물리 올림피아드 정복을 위한 시각-논리 통합 인공지능의 탄생
1. 핵심 요약 (Executive Summary)
인공지능의 발전 궤적에서 단순한 기호 조작(Symbolic Manipulation)을 넘어선 ‘과학적 등급의 추론(Science-grade Reasoning)’은 범용 인공지능(AGI)으로 가기 위한 마지막 관문 중 하나입니다. 특히 물리학은 우주의 법칙과 논리적 일관성을 유지해야 한다는 점에서 AI에게 가장 가혹한 테스트베드입니다.
최근 공개된 P1-VL(Physics 1 - Vision Language) 모델은 물리 올림피아드 수준의 복잡한 문제를 해결하기 위해 설계된 오픈소스 멀티모달 모델군입니다. 이 모델은 단순히 텍스트 정보를 처리하는 것을 넘어, 다이어그램에 포함된 필수적인 물리적 제약 조건(경계 조건, 공간적 대칭성 등)을 시각적으로 인지하고 이를 추론 과정에 통합합니다.
주요 성과:
- P1-VL-235B-A22B: HiPhO(High Physics Olympiad) 벤치마크에서 12개의 금메달을 획득하며 오픈소스 VLM 중 압도적 1위 기록.
- 에이전트 시스템: PhysicsMinions 프레임워크를 통해 글로벌 랭킹 2위(Gemini-3-Pro 바로 뒤) 달성.
- 기술적 혁신: 커리큘럼 강화학습(Curriculum RL)과 에이전틱 증강(Agentic Augmentation)을 통한 사후 학습 최적화.
이 분석 보고서에서는 P1-VL의 아키텍처, 데이터 파이프라인, 그리고 이것이 인공지능 산업에 시사하는 바를 심층적으로 다룹니다.
2. 연구 배경 및 문제 정의 (Introduction & Problem Statement)
기존의 대규모 언어 모델(LLM)은 수학적 계산이나 텍스트 기반의 논리 추론에서 괄목할 만한 성과를 거두었습니다. 그러나 물리적 현실(Physical Reality)과 결합된 추론에서는 여전히 취약함을 보입니다.
2.1. 왜 ‘물리’인가?
물리학은 추상적인 수학 모델을 구체적인 공간 및 시간적 맥락에 투영해야 합니다. 특히 올림피아드 수준의 물리 문제에서 그림(Diagram)은 단순한 보조 자료가 아닙니다. 그림 안에는 텍스트에 생략된 마찰력의 방향, 도르래의 연결 상태, 혹은 전자기장의 분포와 같은 핵심 기하학적 제약이 포함되어 있습니다.
2.2. Visual-Logical Gap
현재 대다수 VLM의 한계는 시각적 특징 추출과 논리적 추론이 분절되어 있다는 점입니다. 모델은 그림에서 ‘공(ball)’을 식별할 수 있지만, 그 공이 속한 좌표계의 경계 조건을 논리 체인에 올바르게 삽입하지 못합니다. P1-VL은 바로 이 ‘시각-논리 간극(Visual-Logical Gap)’을 메우기 위해 탄생했습니다.
3. 핵심 기술 및 아키텍처 심층 분석 (Core Methodology)
P1-VL의 성공은 단순한 파라미터 증설이 아닌, 물리 지식의 계층 구조를 반영한 학습 전략에 있습니다.
3.1. 커리큘럼 강화학습 (Curriculum Reinforcement Learning)
물리학은 기초 역학을 모르고 양자 역학을 이해할 수 없는 학문입니다. 연구진은 progressive difficulty expansion(점진적 난이도 확장) 기법을 RL에 도입했습니다. 처음에는 기본적인 힘의 평형 문제부터 시작하여 점차 다체 문제(Multi-body problems)와 복합 전자기학으로 난이도를 높여 모델의 포스트 트레이닝(Post-training)을 안정화했습니다.
3.2. 에이전틱 증강: PhysicsMinions
추론 단계에서 P1-VL은 단순한 일회성 답변에 그치지 않습니다. PhysicsMinions라 불리는 에이전트 프레임워크는 모델이 스스로 도출한 물리적 가정을 검증하고, 시각적 데이터와 수치적 결과 사이의 모순이 발견되면 이를 반복적으로 수정(Self-verification)합니다.
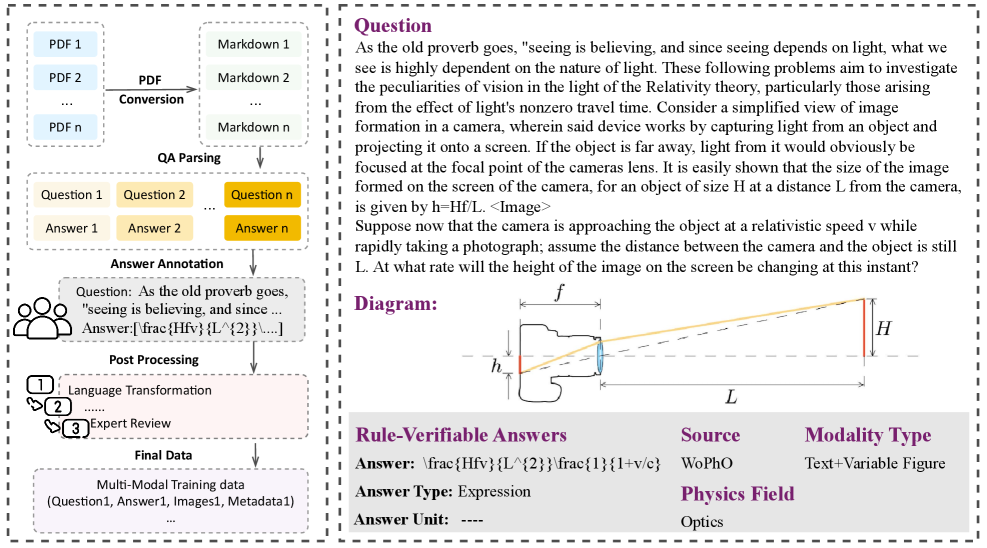 그림 4: 물리 데이터 수집 파이프라인. 고품질의 데이터 합성과 검증 과정을 통해 모델의 물리적 기초를 다지는 핵심 공정입니다.
그림 4: 물리 데이터 수집 파이프라인. 고품질의 데이터 합성과 검증 과정을 통해 모델의 물리적 기초를 다지는 핵심 공정입니다.
3.3. MoE (Mixture of Experts) 아키텍처
가장 강력한 모델인 P1-VL-235B-A22B는 MoE 구조를 채택하여 총 235B의 파라미터를 보유하면서도, 추론 시에는 22B의 활성 파라미터만을 사용하여 효율성을 극대화했습니다. 이는 복잡한 물리 추론에 특화된 ‘전문가(Expert)’ 레이어들이 상황에 맞춰 활성화되도록 설계되었음을 의미합니다.
4. 구현 및 실험 환경 (Implementation Details & Experiment Setup)
데이터는 AI의 근육입니다. P1-VL은 역대 최강의 물리 전용 멀티모달 데이터셋인 P1-Dataset을 기반으로 합니다.
4.1. 데이터셋 통계 및 분포
연구팀은 1.2M 개 이상의 고품질 물리 문제와 설명 데이터를 구축했습니다. 단순히 정답만 맞추는 것이 아니라, 왜 이 물리 법칙이 적용되어야 하는지에 대한 ‘사고 과정(Chain-of-Thought)’을 데이터에 녹여냈습니다.
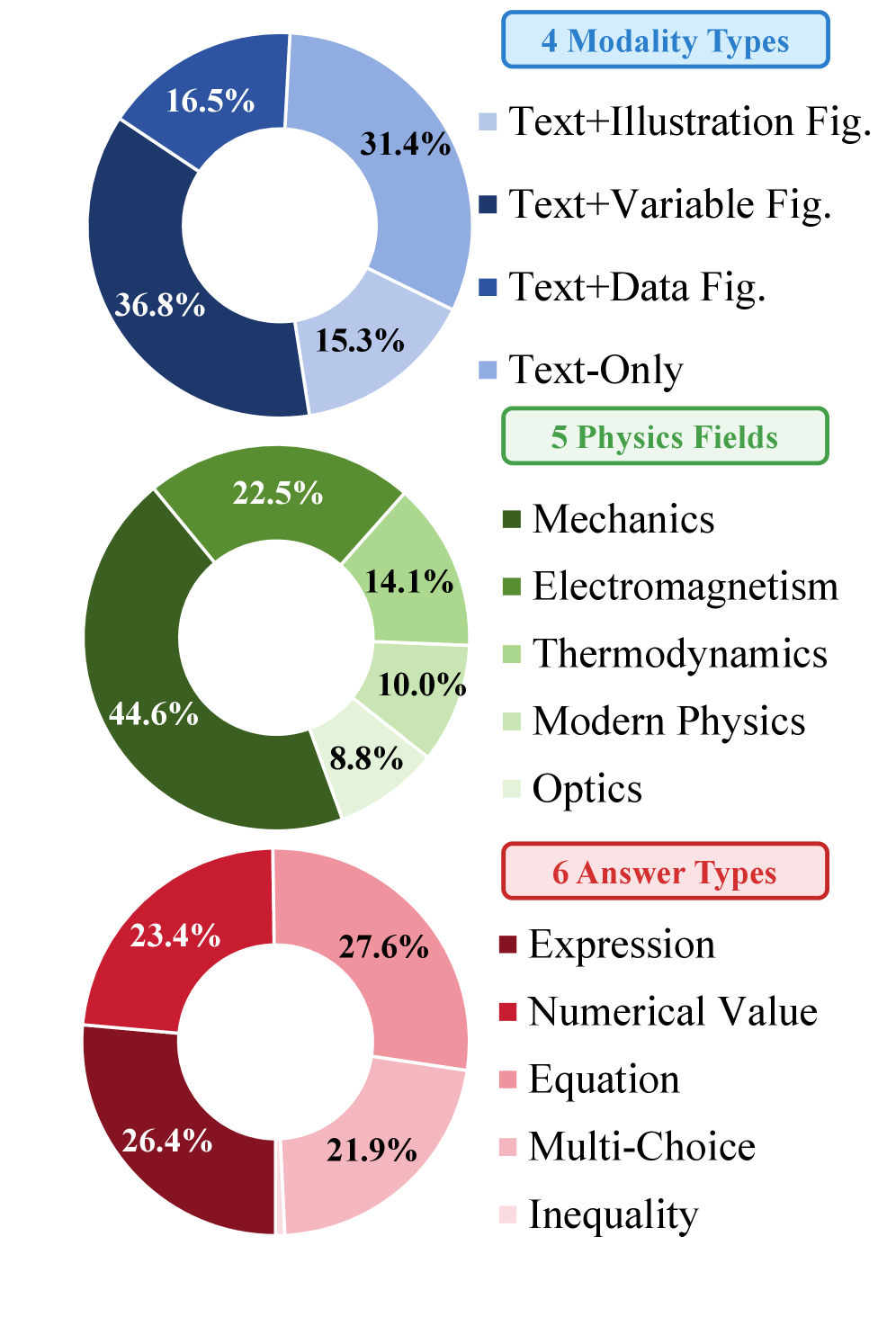 표 1: 학습에 사용된 멀티모달 데이터 통계. 텍스트와 이미지가 결합된 방대한 물리 데이터셋의 규모를 보여줍니다.
표 1: 학습에 사용된 멀티모달 데이터 통계. 텍스트와 이미지가 결합된 방대한 물리 데이터셋의 규모를 보여줍니다.
그림 3: 학습 데이터의 분포. 역학, 전자기학, 열역학 등 물리학 전반을 아우르는 균형 잡힌 데이터 구성이 돋보입니다.
4.2. 훈련 파이프라인
- Pre-training: 대규모 과학 텍스트 및 이미지-텍스트 쌍 학습.
- SFT (Supervised Fine-Tuning): 물리 올림피아드 기출 및 해설 데이터 학습.
- RL (Reinforcement Learning): 물리적 일관성과 정확성을 보상 함수(Reward Function)로 설정한 커리큘럼 기반 학습.
5. 성능 평가 및 비교 (Comparative Analysis)
P1-VL은 HiPhO(Higher Physics Olympiad) 벤치마크에서 그 위력을 증명했습니다. HiPhO는 2024년에서 2025년 사이에 출제된 최신 고난도 문제들로 구성되어 데이터 오염(Data Contamination) 가능성을 최소화한 리트머스 시험지입니다.
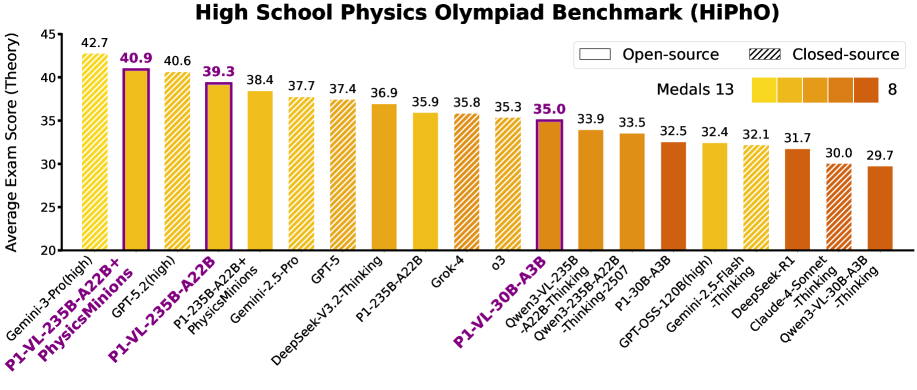 그림 1: HiPhO 벤치마크에서의 성능 비교. P1-VL은 오픈소스 모델 중 압도적 1위이며, 에이전트 시스템 결합 시 세계 2위를 차지합니다.
그림 1: HiPhO 벤치마크에서의 성능 비교. P1-VL은 오픈소스 모델 중 압도적 1위이며, 에이전트 시스템 결합 시 세계 2위를 차지합니다.
5.1. 주요 대조군과의 비교
- vs. Gemini-3-Pro: 현존 최강의 상용 모델인 Gemini-3-Pro에 이어 전체 2위를 기록했습니다. 이는 오픈소스 모델이 클로즈드 모델의 성능을 턱밑까지 추격했음을 보여주는 사건입니다.
- vs. DeepSeek-V3.2-Thinking: 강력한 추론 능력을 가진 DeepSeek 모델보다 물리적 시각 인지 능력에서 우위를 점하며 더 높은 평균 점수를 획득했습니다.
5.2. 실제 문제 해결 사례 (IPhO 2025)
실제 2025년 국제 물리 올림피아드(IPhO) 문제를 풀이하는 과정을 보면 P1-VL의 정교함을 알 수 있습니다. 단순 픽셀 인식을 넘어, 거품의 반경을 측정하고 속도를 추정하는 등의 정량적 시각 분석을 수행합니다.
 그림 2: IPhO 2025 문제 풀이 예시. 복잡한 이미지 내의 기하학적 요소를 정밀하게 분석해야 하는 고난도 태스크입니다.
그림 2: IPhO 2025 문제 풀이 예시. 복잡한 이미지 내의 기하학적 요소를 정밀하게 분석해야 하는 고난도 태스크입니다.
6. 실제 적용 분야 및 글로벌 파급력 (Real-World Application & Impact)
P1-VL은 단순한 ‘시험용 AI’가 아닙니다. 이 모델의 시각-논리 통합 능력은 산업계 전반에 혁신을 가져올 수 있습니다.
- 자율 연구 에이전트 (AI Scientist): 복잡한 실험 논문의 도표와 물리적 현상을 결합 분석하여 가설을 세우고 시뮬레이션 환경을 설계할 수 있습니다.
- 정밀 제조 및 로보틱스: 카메라로 촬영된 공장의 기계 작동 상태를 보고 물리적 결함(마찰, 불균형, 유격 등)을 논리적으로 추론하여 예지 보전을 수행할 수 있습니다.
- 에듀테크 (Advanced STEM Education): 학생들의 복잡한 풀이 과정을 시각적으로 확인하고, 어느 물리 법칙에서 오개념이 발생했는지 정교하게 피드백하는 개인형 물리 튜터가 가능해집니다.
- 우주 항공 및 엔지니어링: 실시간 센서 데이터와 설계도를 대조하여 물리적 무결성을 검토하는 보조 엔지니어 역할을 수행할 수 있습니다.
7. 한계점 및 기술적 비평 (Discussion: Limitations & Critical Critique)
필자의 전문가적 시각에서 볼 때, P1-VL은 위대한 도약이지만 몇 가지 비판적 검토가 필요합니다.
- 물리 법칙의 암기 vs. 원리적 이해: 모델이 정말로 뉴턴 역학의 본질을 깨닫고 있는가, 아니면 수많은 올림피아드 족보를 통해 ‘정형화된 풀이 패턴’을 시각적으로 매칭하는 것인가에 대한 논란이 있을 수 있습니다. 학습 데이터에 존재하지 않는 ‘완전히 새로운 물리적 상수나 법칙’이 적용된 가상 세계관에서의 추론 능력은 아직 검증되지 않았습니다.
- 컴퓨팅 비용: 235B 규모의 MoE 모델은 오픈소스라고 해도 일반적인 연구소나 기업이 운용하기에 상당한 컴퓨팅 자원을 요구합니다. 30B 모델이 훌륭한 대안이 될 수 있지만, 상위 모델과의 성능 격차는 여전히 존재합니다.
- 환각 현상(Hallucination)의 위험성: 물리적 추론에서 단 하나의 숫자가 틀리거나 부호(+/-)가 바뀌는 것은 치명적입니다. 에이전트 시스템이 이를 보완한다고 하지만, 극단적인 경계 상황에서의 신뢰도 문제는 여전히 남아있습니다.
8. 결론 및 인사이트 (Conclusion)
P1-VL은 인공지능이 ‘언어의 섬’을 벗어나 ‘물리적 실재’로 나아가는 중요한 이정표입니다. 다이어그램의 선 하나, 화살표 하나의 의미를 물리 법칙과 연결할 수 있는 능력은 단순한 멀티모달 학습 그 이상의 성취입니다.
이 모델의 오픈소스화는 과학 연구의 민주화를 가속화할 것이며, 특히 물리적 지능(Physical Intelligence)을 필요로 하는 로보틱스 및 제조 산업 분야의 AI 개발자들에게 강력한 기반 모델(Foundation Model)을 제공할 것입니다. 우리는 이제 텍스트로만 세상을 배우는 AI를 넘어, 눈으로 물리적 법칙을 보고 이해하는 AI의 시대를 맞이하고 있습니다.
관련 연구를 지속적으로 추적하고 싶은 개발자라면, P1-VL의 에이전트 프레임워크인 PhysicsMinions의 워크플로우를 분석하여 본인의 도메인에 적용해 보길 강력히 권장합니다.
