[2026-02-09] 비디오 이해의 새로운 지평: TimeChat-Captioner의 6차원 구조적 캡셔닝 기술 및 OmniDC 연구 심층 분석

1. Executive Summary (핵심 요약)
인공지능의 비디오 이해 기술은 단순한 ‘요약(Summarization)’을 넘어, 영상 내에서 발생하는 모든 사건과 환경적 요소를 시간 흐름에 따라 정밀하게 서술하는 ‘Omni Dense Captioning’ 단계로 진화하고 있습니다. 본 분석에서는 최신 논문 “TimeChat-Captioner: Scripting Multi-Scene Videos with Time-Aware and Structural Audio-Visual Captions”를 중심으로, 비디오를 마치 영화 시나리오처럼 정교하게 구조화하여 설명하는 기술적 방법론을 살펴봅니다.
주요 기여는 다음과 같습니다:
- Omni Dense Captioning 태스크 제안: 6개 차원(사건, 시각적 배경, 오디오, 대화, 카메라 상태, 샷 편집 스타일)의 구조적 스키마를 통해 비디오를 묘사.
- OmniDCBench & TimeChatCap-42K: 고품질 휴먼 데이터셋과 대규모 합성 데이터셋 구축.
- TimeChat-Captioner-7B: SFT(Supervised Fine-Tuning)와 GRPO(Group Relative Policy Optimization)를 결합하여 Gemini-2.5-Pro를 능가하는 성능 달성.
- SodaM 평가지표: 장면 경계의 모호성을 해결하고 시간 인지적 정밀도를 측정하는 새로운 지표 제안.
2. Introduction & Problem Statement (연구 배경 및 문제 정의)
기존의 비디오-언어 모델(VLM)들은 비디오 전체를 아우르는 짧은 요약이나 특정 질문에 대한 답변(VQA)에는 능숙하지만, 영상의 모든 세부 사항을 시간 순서대로 촘촘하게 설명하는 데에는 한계가 있었습니다. 특히 기존의 ‘Dense Video Captioning’은 주로 ‘무엇을 하는가’라는 동작 중심의 서술에 치우쳐 있어, 영상의 분위기, 음향 효과, 카메라의 움직임과 같은 영화적(Cinematographic) 요소들을 놓치는 경우가 많았습니다.
이러한 정보의 부재는 비디오 생성 AI의 검증, 시각 장애인을 위한 상세 화면 해설, 혹은 대규모 영상 데이터베이스의 정밀 검색 단계에서 병목 현상을 일으킵니다. 저자들은 이 문제를 해결하기 위해 ‘스크립트 형태의 구조적 캡셔닝’이라는 개념을 도입했습니다. 이는 비디오를 단순한 영상 신호가 아닌, 텍스트로 치밀하게 설계된 ‘디지털 시나리오’로 변환하는 과정입니다.
3. Core Methodology (핵심 기술 및 아키텍처 심층 분석)
3.1. 6차원 구조적 스키마 (Six-Dimensional Structural Schema)
TimeChat-Captioner는 비디오의 한 장면(Scene)을 설명할 때 다음 6가지 요소를 반드시 포함하도록 설계되었습니다.
- Detailed Events: 인물의 행동과 상호작용의 핵심.
- Visual Background: 장소, 조명, 기상 조건 등 시각적 맥락.
- Acoustics: 배경 음악, 환경 소음, 효과음.
- Dialogue: 대사의 내용과 화자의 감정 상태.
- Camera State: 앵글(Low/High), 무브먼트(Pan/Tilt/Zoom).
- Shot Editing Style: 컷 전환 방식 및 전반적인 편집 호흡.
3.2. 모델 아키텍처 및 훈련 전략
TimeChat-Captioner는 Qwen2.5-Omni를 백본으로 사용하며, 오디오와 비디오 토큰이 교차 배치(Interleaved)된 입력을 처리합니다.
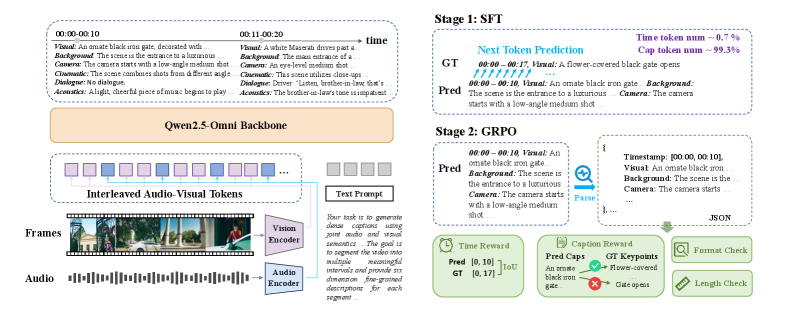 그림 1: TimeChat-Captioner 아키텍처 개요. Qwen2.5-Omni 기반의 멀티모달 입력 처리와 SFT/GRPO 2단계 훈련 과정을 보여줍니다.
그림 1: TimeChat-Captioner 아키텍처 개요. Qwen2.5-Omni 기반의 멀티모달 입력 처리와 SFT/GRPO 2단계 훈련 과정을 보여줍니다.
훈련 과정은 두 단계로 나뉩니다.
- SFT (Supervised Fine-Tuning): 모델이 제안된 6차원 구조와 타임스탬프 형식을 학습하도록 유도합니다.
- GRPO (Group Relative Policy Optimization): DeepSeek-V3 등에서 각광받은 강화학습 기법을 적용했습니다. 여기서 모델은 단순히 정답을 복제하는 것이 아니라, 출력의 형식(Format), 길이(Length), 타임스탬프의 정확도(Timestamp Accuracy), 그리고 설명의 풍부함(Fine-grained Quality)에 대한 보상(Reward)을 기반으로 스스로 최적화됩니다.
4. Implementation Details & Experiment Setup (구현 및 실험 환경)
4.1. 데이터셋 구축 (OmniDCBench & TimeChatCap-42K)
성능 평가와 훈련을 위해 연구진은 두 가지 핵심 데이터셋을 구축했습니다.
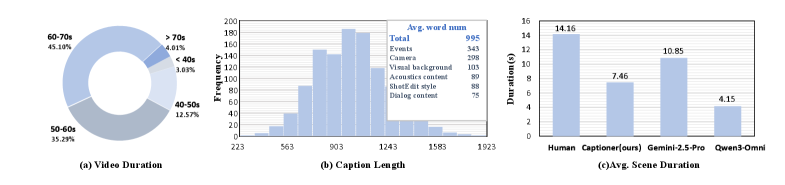 그림 2: OmniDCBench 통계. 영상당 평균 995단어에 달하는 방대한 인간 주석 데이터를 포함하고 있습니다.
그림 2: OmniDCBench 통계. 영상당 평균 995단어에 달하는 방대한 인간 주석 데이터를 포함하고 있습니다.
- OmniDCBench: 1,000개 이상의 영상에 대해 인간이 직접 6차원 캡션을 작성한 벤치마크입니다. 위 그림에서 보듯, 인간의 주석은 모델 생성 결과보다 훨씬 세밀한 장면 분할(Scene Segmentation) 성능을 보입니다.
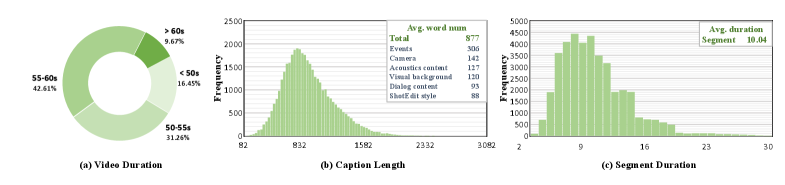 그림 3: TimeChatCap-42K 통계. 약 4.2만 개의 영상에 대해 평균 877단어의 상세 설명을 포함합니다.
그림 3: TimeChatCap-42K 통계. 약 4.2만 개의 영상에 대해 평균 877단어의 상세 설명을 포함합니다.
- TimeChatCap-42K: 대규모 훈련을 위해 구축된 합성 데이터셋입니다. 저자들은 GPT-4o와 같은 강력한 모델을 활용하여 초기 캡션을 생성하고, 이를 정제하는 파이프라인(Figure 6 참고)을 구축했습니다.
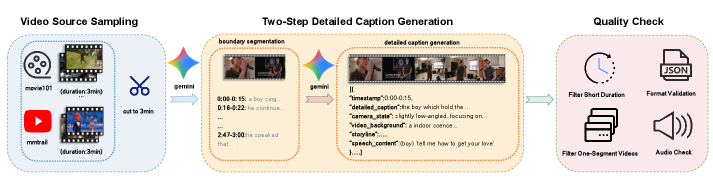 그림 4: 합성 데이터 생성 파이프라인. 원본 영상에서 메타데이터를 추출하고 구조적 캡션으로 변환하는 과정을 보여줍니다.
그림 4: 합성 데이터 생성 파이프라인. 원본 영상에서 메타데이터를 추출하고 구조적 캡션으로 변환하는 과정을 보여줍니다.
5. Comparative Analysis (성능 평가 및 비교)
본 연구에서 가장 놀라운 점은 7B 규모의 모델이 Gemini-2.5-Pro와 같은 초대형 상용 모델을 압도했다는 점입니다.
 그림 5: 정성적 비교 분석. Gemini-2.5-Pro는 남성 운전자를 여성으로 오인하는 환각(Hallucination)을 보인 반면, TimeChat-Captioner는 정확한 캐릭터 인식과 6차원 묘사를 수행합니다.
그림 5: 정성적 비교 분석. Gemini-2.5-Pro는 남성 운전자를 여성으로 오인하는 환각(Hallucination)을 보인 반면, TimeChat-Captioner는 정확한 캐릭터 인식과 6차원 묘사를 수행합니다.
그림 5의 사례를 보면, Gemini-2.5-Pro는 시각적 맥락을 오해하여 심각한 환각을 일으키고, Qwen-3-Omni는 배경 요소에 집착하느라 핵심 사건(대화)을 놓칩니다. 반면 TimeChat-Captioner는 사건, 배경, 오디오, 대화, 카메라, 편집 스타일을 모두 정확하게 잡아냅니다. 이는 강화학습(GRPO)을 통해 ‘무엇이 좋은 캡션인가’에 대한 명확한 가이드라인을 학습했기 때문으로 분석됩니다.
또한, 새로운 평가지표인 SodaM은 기존의 정적인 텍스트 매칭 지표와 달리, 장면 경계가 조금 어긋나더라도 내용의 일치도를 유연하게 평가함으로써 밀집형 캡셔닝(Dense Captioning)의 실제 유용성을 더 잘 반영합니다.
6. Real-World Application & Impact (실제 적용 분야 및 글로벌 파급력)
TimeChat-Captioner의 기술은 단순히 연구실 수준에 머물지 않고 산업 전반에 큰 파급력을 가집니다.
- AI 기반 영상 편집 및 Post-production: 영화 편집자는 수천 시간의 푸티지(Footage) 중 “클로즈업 샷이며, 배경음악이 긴장감을 고조시키고, 비 내리는 소리가 들리는 장면”을 텍스트 검색만으로 찾아낼 수 있습니다.
- 시각 장애인을 위한 배리어 프리(Barrier-free) 서비스: 현재의 화면 해설은 사람이 직접 작성하여 비용과 시간이 많이 소요됩니다. 본 기술은 영상의 세세한 분위기와 카메라 무브먼트까지 음성으로 설명해 줄 수 있어 시각 장애인의 정보 접근성을 획기적으로 높입니다.
- 비디오 생성 AI의 피드백 루프: Sora나 Runway와 같은 비디오 생성 모델이 만든 결과물을 TimeChat-Captioner로 역분석하여, 프롬프트와 결과물 사이의 정렬(Alignment) 상태를 정밀하게 진단하고 개선하는 데 활용할 수 있습니다.
- 보안 및 관제 시스템: 이상 상황 발생 시 “누가 무엇을 했다”는 요약뿐만 아니라, 주변 환경의 소리, 카메라의 시점 변화 등을 기록하여 법적 증거로서의 효력을 강화할 수 있습니다.
7. Discussion: Limitations & Critical Critique (한계점 및 기술적 비평)
전문가적 시각에서 본 논문은 몇 가지 도전적인 과제를 남기고 있습니다.
첫째, 연산 비용의 문제입니다. 영상 하나당 약 1,000단어에 달하는 6차원 캡션을 생성하는 것은 추론(Inference) 단계에서 상당한 토큰을 소비합니다. 실시간 스트리밍 영상에 적용하기에는 현재의 7B 모델도 무거울 수 있으며, 이를 경량화하면서 정보 밀도를 유지하는 연구가 필요합니다.
둘째, 합성 데이터 의존도입니다. TimeChatCap-42K는 GPT-4o 기반의 파이프라인으로 생성되었습니다. 만약 교사 모델(GPT-4o)이 가진 편향이나 비디오 이해의 근본적 한계가 있다면, 이를 학습한 TimeChat-Captioner 역시 해당 한계 내에 갇힐 위험이 있습니다. 그림 4에서는 Gemini보다 우수함을 보여주었으나, 더 복잡한 추상적 은유나 문화적 맥락이 포함된 영상에서의 성능은 검증이 더 필요합니다.
셋째, GRPO의 수렴 안정성입니다. 텍스트 RLHF보다 멀티모달 환경에서의 RL은 보상 함수 설계가 훨씬 까다롭습니다. 타임스탬프의 정확도와 텍스트의 질을 동시에 보상하는 과정에서 발생할 수 있는 ‘보상 해킹(Reward Hacking)’을 어떻게 완벽히 차단했는지에 대한 더 심도 있는 분석이 요구됩니다.
8. Conclusion (결론 및 인사이트)
TimeChat-Captioner는 비디오를 ‘보는 것’에서 ‘읽어내는 것’으로 패러다임을 전환했습니다. 단순히 무엇이 찍혔는지를 나열하는 수준을 넘어, 감독의 의도(카메라, 편집)와 환경적 요소(오디오, 배경)를 융합한 구조적 데이터로 변환하는 능력은 진정한 의미의 ‘멀티모달 이해’에 한 걸음 더 다가선 결과입니다.
특히 오픈 소스 기반의 7B 모델이 독점적 상용 AI(Gemini-2.5-Pro)를 특정 태스크에서 압도했다는 사실은, 데이터의 구조화와 세밀한 강화학습 전략이 모델의 파라미터 크기보다 더 중요할 수 있음을 시사합니다. 향후 이 기술은 비디오 검색, 생성 AI 제어, 자율 주행 등 시각 정보의 정밀한 텍스트화가 필요한 모든 분야의 기반 기술이 될 것입니다.
핵심 한 줄 평: “비디오를 데이터 시트로 바꾸는 연금술, TimeChat-Captioner는 미래의 영상 분석 표준이 될 것이다.”
