[2026-01-30] 비디오 생성의 고질병 '시간적 편향'을 도려내다: TokenTrim - 추론 시점 토큰 프루닝 기술 심층 분석

1. 핵심 요약 (Executive Summary)
최근 생성형 AI 분야에서 가장 도전적인 과제 중 하나는 ‘일관성 있는 긴 비디오(Long Video)의 생성’입니다. 오토리그레시브(Auto-regressive) 방식의 비디오 생성 모델은 이전 프레임을 조건으로 다음 프레임을 생성하며 이론적으로는 무한한 길이를 생성할 수 있지만, 실제로는 시간적 편향(Temporal Drift)이라는 치명적인 문제에 직면해 있습니다. 생성 과정에서 발생하는 미세한 오류가 누적되어 시간이 지날수록 색상이 변질되거나, 물체의 형상이 붕괴되고, 결국 비디오 전체의 의미적 맥락이 상실되는 현상입니다.
오늘 분석할 논문 “TokenTrim: Inference-Time Token Pruning for Autoregressive Long Video Generation”은 이 문제를 해결하기 위해 모델을 재학습시키거나 아키텍처를 변경하는 대신, 추론 시점(Inference-time)에서 오염된 잠재 토큰(Latent Tokens)을 식별하고 제거하는 지극히 실용적이면서도 강력한 기법을 제시합니다.
 그림 1: TokenTrim 적용 전후의 결과 비교. 시간 경과에 따른 품질 저하와 의미적 왜곡이 획기적으로 개선된 것을 확인할 수 있습니다.
그림 1: TokenTrim 적용 전후의 결과 비교. 시간 경과에 따른 품질 저하와 의미적 왜곡이 획기적으로 개선된 것을 확인할 수 있습니다.
본 분석에서는 TokenTrim의 핵심 가설인 ‘오염된 토큰의 재사용’ 문제를 파헤치고, 이들이 제안하는 적응형 프루닝(Adaptive Pruning) 메커니즘이 어떻게 긴 비디오 생성의 새로운 표준이 될 수 있는지 시니어 AI 사이언티스트의 시각에서 심층적으로 논의하겠습니다.
2. 연구 배경 및 문제 정의 (Introduction & Problem Statement)
2.1 오토리그레시브 비디오 생성의 딜레마
비디오 생성 모델(Sora, Runway Gen-3, Llama-Gen 등)은 대개 ‘이전 데이터(Context)를 바탕으로 미래를 예측’하는 방식을 취합니다. 하지만 이 과정은 본질적으로 ‘비가역적 오류의 축적’이라는 리스크를 안고 있습니다. 훈련 단계에서는 정답(Ground Truth) 프레임이 주어지지만, 추론 단계에서는 모델이 생성한 불완전한 프레임이 다시 입력(Conditioning)으로 들어가기 때문입니다.
2.2 시간적 편향(Temporal Drift)의 원인: 모델 용량인가, 오류 전파인가?
기존 연구들은 모델의 파라미터가 부족하거나 비디오 데이터셋의 복잡도를 충분히 학습하지 못해서 드리프트가 발생한다고 보았습니다. 그러나 본 논문의 저자들은 흥미로운 가설을 던집니다. “드리프트는 모델의 용량 문제가 아니라, 생성된 잠재 공간(Latent Space) 내에서 특정 토큰이 오염되고, 이 오염된 토큰이 반복적으로 참조되면서 발생하는 오류 전파의 결과물이다.”
저자들은 특히 ‘Corrupted Latent Tokens’에 주목했습니다. 비디오 생성 과정에서 특정 영역의 토큰이 이전 상태와 너무 큰 차이를 보이면, 이는 모델이 해당 영역을 처리하는 데 실패했음을 의미하며, 이 데이터가 다음 프레임의 KV Cache(Key-Value Cache)에 남게 되면 이후 모든 프레임 생성에 악영향을 끼칩니다.
3. 핵심 기술 및 아키텍처 심층 분석 (Core Methodology)
TokenTrim의 알고리즘은 매우 우아합니다. 복잡한 신경망 추가 없이, 단지 ‘이상치 토큰’을 걸러내는 것만으로 성능을 극대화합니다.
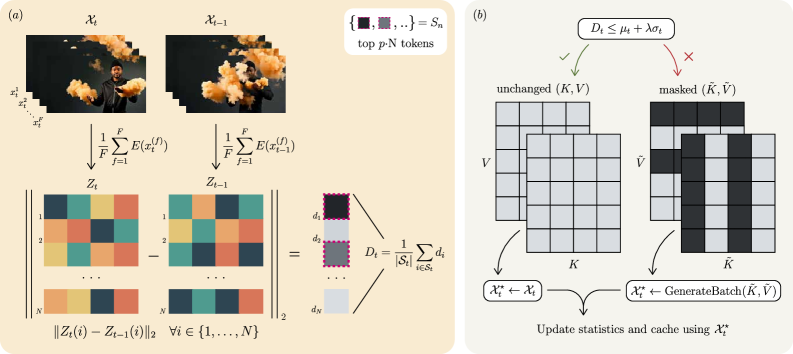 그림 2: TokenTrim의 전체 프로세스. (a) 이전 배치와 현재 후보 배치의 잠재 요약을 비교하여 드리프트 $d_i$를 계산하고, (b) 적응형 임계값에 따라 오염된 토큰을 마스킹한 후 다시 생성합니다.
그림 2: TokenTrim의 전체 프로세스. (a) 이전 배치와 현재 후보 배치의 잠재 요약을 비교하여 드리프트 $d_i$를 계산하고, (b) 적응형 임계값에 따라 오염된 토큰을 마스킹한 후 다시 생성합니다.
3.1 단계별 프로세스 분석
잠재 요약 생성 (Latent Summarization): 현재 생성 중인 후보 배치 $\mathcal{X}t$와 직전 단계의 배치 $\mathcal{X}{t-1}$을 인코딩하여 잠재 토큰 $Z_t, Z_{t-1}$을 얻습니다. 이때 계산 효율을 위해 프레임 차원을 평균(Averaging)하여 공간적 해상도를 유지한 요약본을 만듭니다.
토큰별 드리프트 계산 (Per-token Drift Calculation): 각 공간 위치 $i$에 대해 두 잠재 요약 간의 $L_2$ 거리를 측정합니다: $d_i = |Z_t(i) - Z_{t-1}(i)|_2$. 이 거리가 클수록 해당 위치의 토큰이 급격하게 변했거나 오염되었을 가능성이 큽니다.
불안정 토큰 집합 추출 (Identifying Unstable Tokens): 전체 토큰 중 드리프트가 가장 큰 상위 $p\%$의 토큰들을 ‘불안정 세트($S_t$)’로 규정합니다. 그리고 이 세트의 평균 드리프트를 ‘배치 드리프트 심각도($D_t$)’로 정의합니다.
적응형 임계값 기반 조건부 프루닝 (Adaptive Pruning): $D_t$가 사전에 정의된 적응형 임계값($\mu_t + \lambda \sigma_t$)을 초과하는지 확인합니다.
- 정상 범위: 그대로 승인하고 다음 단계로 진행.
- 비정상 범위: 불안정 세트($S_t$)에 해당하는 토큰들을 KV Cache에서 마스킹(Masking)하거나 제거합니다. 이후, 깨끗한(Pruned) 컨텍스트를 기반으로 현재 배치를 다시 생성(Regenerate)합니다.
3.2 왜 ‘Pruning’인가?
기존의 드리프트 완화 기술들은 프레임 전체를 다시 생성하거나 공간적인 영역을 통째로 잘라내는 투박한 방식을 썼습니다. 반면, TokenTrim은 잠재 공간 상의 토큰 단위로 접근합니다. 이는 비디오의 중요한 정보는 유지하면서, 오염된 노이즈만 선택적으로 제거할 수 있게 해줍니다. 이것이 바로 시니어 엔지니어들이 추구하는 ‘수술적 정밀도’입니다.
4. 구현 및 실험 환경 (Implementation Details & Experiment Setup)
저자들은 TokenTrim의 범용성을 입증하기 위해 다음과 같은 최첨단 비디오 생성 프레임워크에 이를 결합했습니다.
- Rolling Forcing & Self Forcing: 최근 비디오 생성의 SOTA(State-of-the-Art) 기법들로, 긴 시퀀스를 관리하기 위한 특수한 샘플링 전략을 가집니다.
- Llama-Gen & FlowMo: Transformer 기반의 비디오 토큰 생성기 및 Flow-matching 기반 모델들을 활용했습니다.
주요 하이퍼파라미터:
- $p$: 제거할 토큰의 비율. 실험 결과 $p=0.1$ (10%) 정도가 가장 효율적이었습니다.
- $\lambda$: 드리프트 허용치를 조절하는 계수. 이 값이 낮을수록 더 엄격하게 토큰을 제거합니다.
5. 성능 평가 및 비교 (Comparative Analysis)
5.1 정성적 평가 (Qualitative Results)
 그림 3: 질적 결과 비교. TokenTrim은 색상 전이(Color shift), 아티팩트(Artifacts), 그리고 비자연스러운 움직임을 효과적으로 억제합니다.
그림 3: 질적 결과 비교. TokenTrim은 색상 전이(Color shift), 아티팩트(Artifacts), 그리고 비자연스러운 움직임을 효과적으로 억제합니다.
그림 3에서 볼 수 있듯이, 기존 모델들은 약 100프레임 이후 배경색이 급격히 변하거나(c, d), 피카츄의 형태가 뭉개지는(a) 현상이 발생합니다. TokenTrim은 이러한 ‘누적 오염’의 고리를 끊어냄으로써 비디오의 끝까지 초기 스타일과 형태를 유지합니다.
 그림 4: FlowMo 모델에 적용했을 때의 결과. 모델의 아키텍처와 상관없이 TokenTrim이 일관되게 품질을 향상시킴을 보여줍니다.
그림 4: FlowMo 모델에 적용했을 때의 결과. 모델의 아키텍처와 상관없이 TokenTrim이 일관되게 품질을 향상시킴을 보여줍니다.
5.2 정량적 및 인간 선호도 조사 (Quantitative & Human Study)
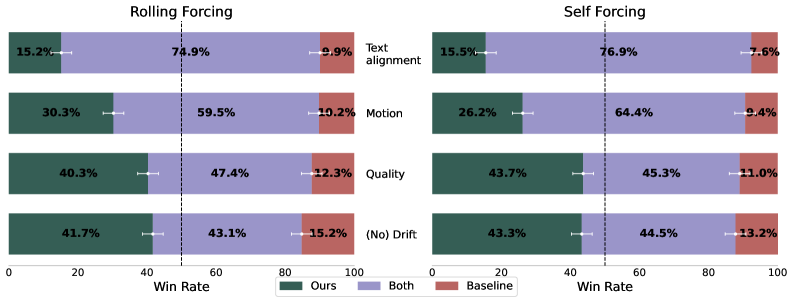 그림 5: 인간 선호도 조사 결과. 드리프트 감소, 움직임 품질, 전반적 시각 품질 모든 지표에서 압도적인 우위를 점하고 있습니다.
그림 5: 인간 선호도 조사 결과. 드리프트 감소, 움직임 품질, 전반적 시각 품질 모든 지표에서 압도적인 우위를 점하고 있습니다.
VideoJAM-bench를 활용한 실험에서 TokenTrim은 기존의 Baseline 대비 거의 모든 지표에서 우수한 성적을 거두었습니다. 특히 텍스트-비디오 정렬(Text-Video Alignment)을 해치지 않으면서도 시간적 일관성을 높였다는 점이 고무적입니다.
6. 실제 적용 분야 및 글로벌 파급력 (Real-World Application & Impact)
이 기술은 단순한 연구 성과를 넘어 실무적으로 거대한 파급력을 가집니다.
- 장편 영화 및 애니메이션 생성: 현재 AI 비디오 생성의 최대 약점은 10초 이상의 긴 컷을 만들 때 일관성이 깨진다는 것입니다. TokenTrim은 수 분 단위의 일관된 컷 생성을 가능케 하여 제작 비용을 혁신적으로 낮출 수 있습니다.
- 게임 내 컷신 및 인터랙티브 미디어: 실시간성이 중요한 게임 엔진에서 추론 시점에 간단한 연산만으로 퀄리티를 보정할 수 있다는 것은 큰 장점입니다.
- 가상 시뮬레이션 환경 구축: 자율주행이나 로봇 학습을 위한 긴 주행 영상 시뮬레이션에서 ‘물리적 타당성’을 유지하는 데 핵심적인 역할을 할 수 있습니다.
AI Scientist의 시각: “TokenTrim은 ‘학습’에 목매던 기존 패러다임에서 벗어나 ‘제어(Control)’와 ‘정화(Refinement)’의 중요성을 일깨워준 연구입니다. 특히 리소스가 부족한 스타트업에게 재학습 비용 없이 품질을 높일 수 있는 최고의 솔루션이 될 것입니다.”
7. 기술적 비평 및 한계점 (Discussion: Limitations & Critical Critique)
냉정하게 분석하자면, 본 논문에도 몇 가지 개선이 필요한 지점이 있습니다.
- 추론 시간의 증가 (Inference Overhead): ‘재생성(Regeneration)’ 단계가 포함되므로, 드리프트가 심한 경우 실제 생성 시간은 Baseline보다 1.5배~2배까지 늘어날 수 있습니다. 실시간 서비스에서는 이 오버헤드가 치명적일 수 있습니다.
- L2 Metric의 단순함: 토큰 간의 거리를 단순히 $L_2$ 노름으로 계산하는 것이 의미적(Semantic) 드리프트를 완벽히 대변하는지에 대해서는 의문이 남습니다. CLIP 임베딩이나 더 고차원적인 특징 공간에서의 거리 측정이 대안이 될 수 있습니다.
- Threshold Lambda의 민감도: 실험 결과 $\lambda$ 값에 따라 성능 편차가 큽니다. 비디오의 내용(정적인 풍경 vs 역동적인 스포츠)에 따라 최적의 임계값이 달라져야 하는데, 이를 수동으로 설정해야 한다는 한계가 있습니다.
8. 결론 및 인사이트 (Conclusion)
TokenTrim은 오토리그레시브 비디오 생성의 근본적인 문제인 시간적 편향을 ‘추론 시점의 지능적 가지치기’라는 방법으로 정면 돌파했습니다. 모델을 새로 학습시키지 않고도 기존 모델의 잠재력을 200% 끌어올릴 수 있다는 점에서 매우 경제적이고 효율적인 기술입니다.
미래의 비디오 생성 모델은 아마도 이러한 ‘자기 정화(Self-correction)’ 메커니즘을 내재화하는 방향으로 발전할 것입니다. TokenTrim이 제시한 ‘불안정 토큰 마스킹’ 전략은 향후 Diffusion Transformer(DiT)나 초대형 멀티모달 모델의 추론 최적화 전략에 있어 필수적인 참고 문헌이 될 것입니다.
긴 영상 제작에 어려움을 겪고 있는 AI 엔지니어라면, 지금 당장 여러분의 파이프라인에 TokenTrim을 도입해 보시길 강력히 권장합니다.
