[2026-02-10] Code2World: 렌더링 가능한 코드 생성을 통한 차세대 GUI 월드 모델의 도래와 기술적 심층 분석

Code2World: 렌더링 가능한 코드 생성을 통한 차세대 GUI 월드 모델의 도래와 기술적 심층 분석
1. Executive Summary (핵심 요약)
인공지능 에이전트가 디지털 환경과 상호작용하는 방식은 이제 단순한 명령 수행을 넘어, 자신의 행동이 가져올 결과를 예측하는 ‘예지력(Foresight)’의 단계로 진화하고 있습니다. 본 보고서에서 분석할 Code2World는 GUI(Graphic User Interface) 환경을 위한 혁신적인 월드 모델(World Model)로, 단순히 다음 화면의 픽셀을 예측하는 것이 아니라 ‘렌더링 가능한 코드(HTML)’를 생성함으로써 물리적 세계의 법칙을 디지털 공간에서 재현합니다.
Code2World의 핵심은 데이터 부족 문제를 해결하기 위한 AndroidCode 데이터셋 구축과, 생성된 코드의 시각적/논리적 일관성을 확보하기 위한 Render-Aware Reinforcement Learning (RARL) 기법에 있습니다. 실험 결과, Code2World-8B 모델은 GPT-4o 및 Gemini-1.5 Pro와 같은 초대형 모델과 대등하거나 이를 능가하는 UI 예측 능력을 보여주었으며, 기존 GUI 에이전트의 내비게이션 성공률을 최대 9.5%까지 향상시키는 ‘시뮬레이션 샌드박스’로서의 가치를 입증했습니다.
2. Introduction & Problem Statement (연구 배경 및 문제 정의)
최근 대형 언어 모델(LLM)과 멀티모달 모델(LMM)의 발전으로 자율형 GUI 에이전트 연구가 활발히 진행되고 있습니다. 하지만 기존 에이전트들은 주로 ‘현재 상태 관찰 -> 행동 결정’이라는 단선적인 구조에 의존하며, 자신의 행동이 시스템 상태에 어떤 변화를 일으킬지에 대한 깊은 이해가 부족했습니다.
이러한 문제를 해결하기 위해 등장한 개념이 바로 GUI 월드 모델입니다. 월드 모델은 에이전트가 특정 행동을 취했을 때의 미래 상태를 예측하여, 에이전트가 가상의 시뮬레이션 안에서 최적의 경로를 탐색할 수 있게 돕습니다. 그러나 기존의 접근 방식은 극명한 한계점을 가지고 있었습니다.
- 텍스트 기반 접근 (Text-based): HTML이나 XML 트리 구조만을 예측하는 방식은 레이아웃의 구조적 정보는 담을 수 있으나, 렌더링된 실제 시각적 정보와 세부적인 디자인 요소를 놓치기 쉽습니다.
- 픽셀 기반 접근 (Pixel-based/Diffusion): 비디오 생성 모델이나 확산 모델을 이용해 다음 화면의 이미지를 생성하는 방식은 시각적으로는 화려할 수 있으나, 버튼의 정확한 위치나 텍스트의 가독성 등 ‘제어 가능성(Controllability)’과 ‘정밀도(Precision)’ 측면에서 심각한 결함을 보입니다.
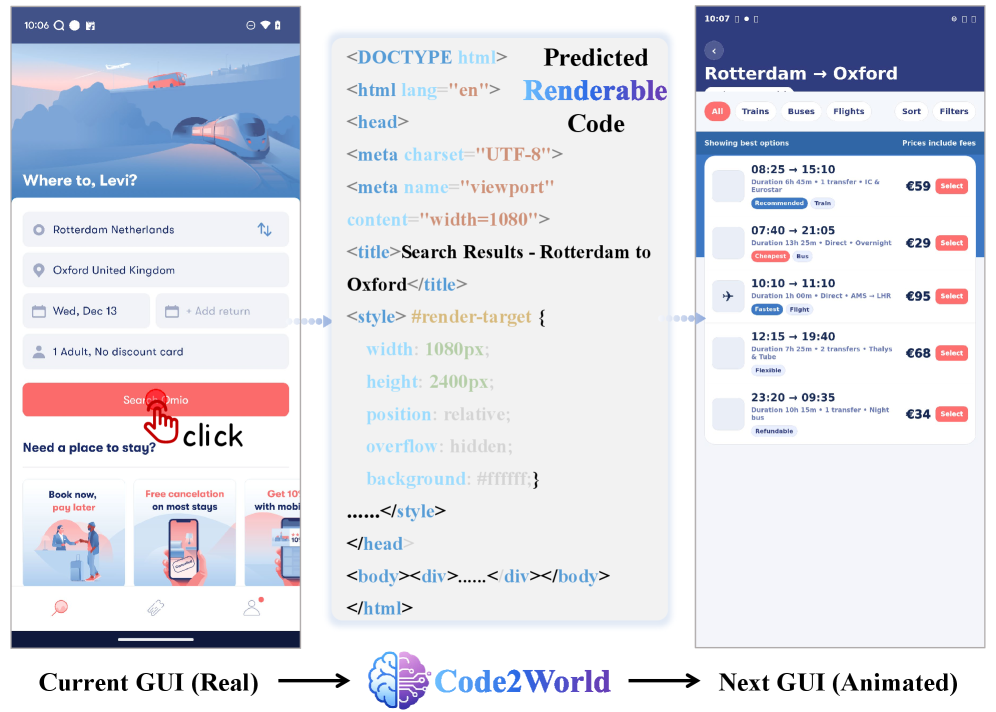 그림 1: Code2World의 개요. 현재 GUI 관찰 상태와 행동이 주어지면, 모델은 렌더링 가능한 코드를 생성하여 다음 스크린샷을 예측합니다.
그림 1: Code2World의 개요. 현재 GUI 관찰 상태와 행동이 주어지면, 모델은 렌더링 가능한 코드를 생성하여 다음 스크린샷을 예측합니다.
Code2World는 이러한 ‘시각적 충실도(Visual Fidelity)’와 ‘구조적 제어 가능성(Structural Controllability)’ 사이의 트레이드오프를 ‘코드 생성 기반의 렌더링’이라는 가교를 통해 해결하고자 합니다.
3. Core Methodology (핵심 기술 및 아키텍처 심층 분석)
Code2World의 성공은 크게 세 가지 축으로 지탱됩니다: (1) 고품질 데이터의 합성, (2) 코드 생성 최적화 전략, (3) 렌더링 결과를 피드백으로 사용하는 강화학습입니다.
3.1. AndroidCode: 시각적 피드백 기반의 데이터 합성
GUI 월드 모델 학습을 위해서는 ‘현재 화면 - 행동 - 다음 화면’의 트리플렛(Triplet) 데이터가 대량으로 필요합니다. 하지만 실제 안드로이드 환경에서 고품질의 HTML 코드를 추출하는 것은 매우 어렵습니다. 연구진은 이를 해결하기 위해 AndroidCode라는 데이터셋을 구축했습니다.
이 과정에서 주목할 점은 Visual-Feedback Revision Loop입니다. 단순히 LLM에게 HTML을 짜라고 시키는 것이 아니라, 생성된 코드를 실제 브라우저 엔진으로 렌더링한 후, 원본 스크린샷과의 시각적 유사도(SigLIP Score)를 측정합니다. 만약 유사도가 기준치(예: 0.9) 미만이라면, 에러 메시지와 시각적 차이점을 피드백으로 주어 코드를 수정하게 합니다. 이 프로세스를 통해 8만 개 이상의 정교한 화면-행동 쌍을 확보했습니다.
3.2. Two-stage Model Optimization
모델 학습은 크게 SFT(Supervised Fine-Tuning)와 RARL(Render-Aware Reinforcement Learning)의 두 단계로 나뉩니다.
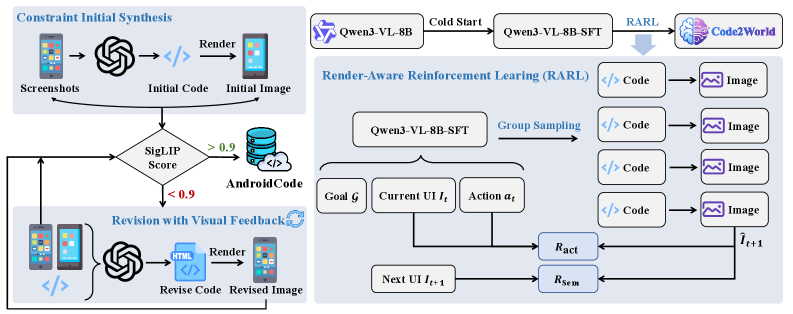 그림 2: 데이터 합성 과정(좌) 및 2단계 모델 최적화 파이프라인(우). GRPO를 활용한 강화학습이 핵심입니다.
그림 2: 데이터 합성 과정(좌) 및 2단계 모델 최적화 파이프라인(우). GRPO를 활용한 강화학습이 핵심입니다.
- SFT (Cold Start): 모델이 기본적인 HTML 문법과 GUI 레이아웃 구조를 이해하도록 AndroidCode 데이터셋으로 사전 학습을 진행합니다.
- RARL (Render-Aware Reinforcement Learning): 모델이 단순히 코드를 복사하는 것을 넘어, ‘렌더링된 결과’가 얼마나 정확한지를 스스로 인지하게 만드는 단계입니다. 여기서 연구진은 DeepSeek-V3에서 제안된 GRPO(Group Relative Policy Optimization) 알고리즘을 사용했습니다.
RARL의 보상 함수(Reward Function) 설계
RARL은 두 가지 핵심 보상을 통해 모델을 가이드합니다.
- 시각적 세부 보상 ($R_{sem}$): 렌더링된 예측 화면과 실제 화면 사이의 CLIP/SigLIP 임베딩 유사도를 측정합니다. 이는 색상, 아이콘 스타일 등 비정형적 시각 정보를 보존합니다.
- 행동 일관성 보상 ($R_{act}$): 행동이 수행된 위치(예: 클릭한 버튼)가 실제 렌더링된 코드 내에서 올바른 요소로 존재하는지, 그리고 그 주변의 변화가 논리적인지를 체크합니다.
4. Implementation Details & Experiment Setup (구현 및 실험 환경)
Code2World는 Qwen2-VL-7B를 베이스 모델로 사용하며, 총 8B 파라미터 규모로 구축되었습니다. 학습을 위해 8대의 NVIDIA H800 GPU가 동원되었으며, GRPO 단계에서는 그룹 크기(G)를 8로 설정하여 정책의 안정성을 도모했습니다.
평가는 안드로이드 환경의 대표적 벤치마크인 AndroidWorld와 자체 구축한 테스트셋에서 진행되었습니다. 비교군으로는 GPT-4o, Gemini-1.5 Pro와 같은 상용 폐쇄형 모델뿐만 아니라, 단순 픽셀 예측을 수행하는 최신 Diffusion 기반 모델들이 포함되었습니다.
5. Comparative Analysis (성능 평가 및 비교)
Code2World의 성능은 단순히 ‘그림을 잘 그리는가’를 넘어 ‘에이전트의 의사결정에 얼마나 도움을 주는가’로 평가됩니다.
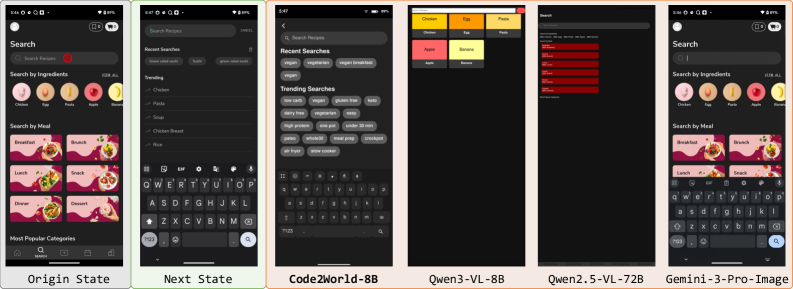 그림 4: Code2World와 타 베이스라인 모델 간의 정성적 비교. Code2World가 텍스트 가독성과 레이아웃 정확도 면에서 압도적입니다.
그림 4: Code2World와 타 베이스라인 모델 간의 정성적 비교. Code2World가 텍스트 가독성과 레이아웃 정확도 면에서 압도적입니다.
질적 평가(Figure 4)를 보면, 기존 Diffusion 모델은 텍스트가 뭉개지거나 레이아웃이 뒤틀리는 현상이 빈번합니다. 반면 Code2World는 코드를 통해 렌더링되므로 텍스트가 매우 선명하고 버튼의 경계가 명확합니다. 이는 에이전트가 다음 행동을 결정할 때 결정적인 요소로 작용합니다.
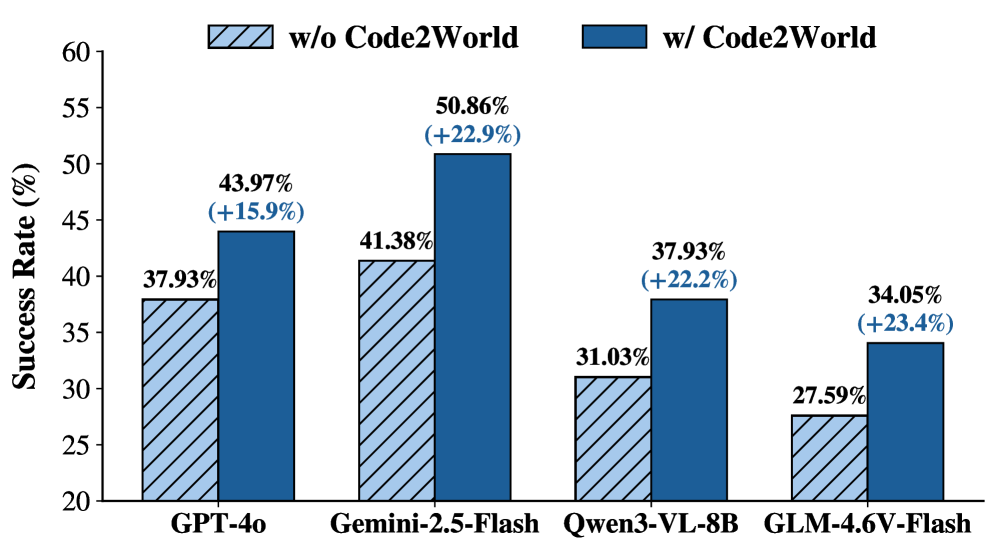 그림 5: AndroidWorld 벤치마크에서의 성능 비교. Code2World를 결합했을 때 에이전트의 성공률이 유의미하게 상승합니다.
그림 5: AndroidWorld 벤치마크에서의 성능 비교. Code2World를 결합했을 때 에이전트의 성공률이 유의미하게 상승합니다.
정량적 지표인 Figure 5를 분석해 보면, Code2World를 ‘Simulated Sandbox’로 활용한 경우 Gemini-1.5 Flash 에이전트의 성능이 9.5% 향상되었습니다. 이는 에이전트가 실수를 하기 전에 가상 환경에서 미리 실행해 보고 오류를 수정할 수 있는 능력을 갖추게 되었음을 의미합니다.
6. Real-World Application & Impact (실제 적용 분야 및 글로벌 파급력)
이 기술이 상용화될 경우, 다음과 같은 분야에서 파괴적인 혁신이 예상됩니다.
- 자율 주행 소프트웨어 테스팅 (Automated QA): 개발자가 앱을 수정할 때마다 에이전트가 수천 가지 시나리오를 가상 환경(Code2World)에서 미리 실행해 보고 UI 깨짐이나 로직 오류를 자동으로 찾아낼 수 있습니다. 실제 기기 없이도 고충실도 시뮬레이션이 가능해집니다.
- 개인화된 AI 비서의 신뢰성 향상: “내 은행 앱에서 이체해줘”라는 명령을 받았을 때, 에이전트는 실제로 송금 버튼을 누르기 전 가상의 시뮬레이션을 통해 결과 화면을 미리 확인하고 사용자에게 컨펌을 받을 수 있습니다. 이는 치명적인 실수를 방지하는 안전장치(Safety Rail) 역할을 합니다.
- 저사양 기기를 위한 클라우드 에이전트: 복잡한 GUI 렌더링 엔진을 기기에서 직접 돌리지 않고도, 코드 기반의 가벼운 예측 모델을 통해 UI 변화를 실시간으로 스트리밍하거나 예측하는 것이 가능해집니다.
7. Discussion: Limitations & Critical Critique (한계점 및 기술적 비평)
본 연구는 매우 훌륭한 성과를 거두었지만, 전문가적 시각에서 몇 가지 비판적 검토가 필요합니다.
- HTML의 범용성 문제: 연구진은 안드로이드 GUI를 HTML로 변환하여 학습시켰습니다. 그러나 실제 안드로이드 앱 중에는 Jetpack Compose, Flutter, 혹은 독자적인 그래픽 엔진(Unity 등)을 사용하여 HTML로 완벽히 매핑하기 어려운 구조가 많습니다. 이러한 비표준 UI 환경에서도 Code2World의 논리가 유효할지는 의문입니다.
- 추론 비용 (Inference Latency): “Propose, Simulate, Select” 파이프라인은 하나의 행동을 결정하기 위해 여러 번의 미래 예측을 수행해야 합니다. 8B 모델을 여러 번 호출하고 렌더링하는 과정은 실시간 상호작용이 중요한 모바일 환경에서 상당한 지연 시간을 초래할 수 있습니다.
- 보상 함수의 편향: RARL에서 사용된 SigLIP 점수는 시각적 유사도에 치중되어 있습니다. 때로는 픽셀상으로는 비슷해 보여도 기능적으로는 완전히 다른(예: 투명한 오버레이 버튼의 유무) 경우가 존재하는데, 이를 완벽히 잡아내기 위한 논리적 보상 체계가 더 정교해져야 할 것입니다.
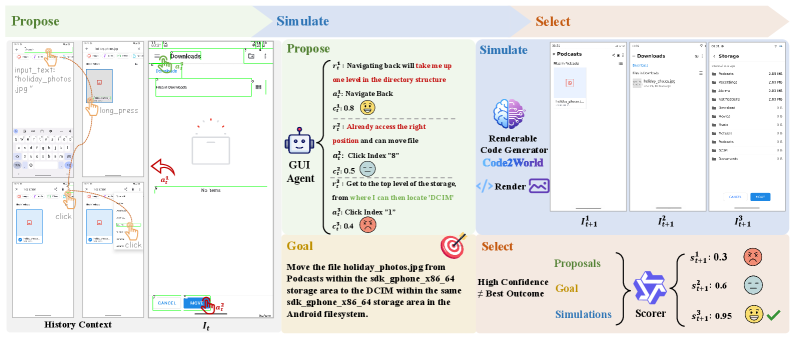 그림 3: Propose-Simulate-Select 파이프라인. 에이전트의 의사결정 과정을 비약적으로 개선합니다.
그림 3: Propose-Simulate-Select 파이프라인. 에이전트의 의사결정 과정을 비약적으로 개선합니다.
8. Conclusion (결론 및 인사이트)
Code2World는 GUI 에이전트 연구의 패러다임을 ‘단순 수행’에서 ‘예측 기반 최적화’로 전환시켰습니다. 픽셀이 아닌 코드를 생성한다는 발상의 전환은 시각적 정확도와 논리적 구조라는 두 마리 토끼를 잡는 데 성공했습니다.
특히 GRPO를 활용한 강화학습 방식은 향후 다른 도메인의 월드 모델(예: 로보틱스, 웹 브라우징)에서도 널리 채택될 수 있는 강력한 프레임워크를 제시했습니다. 비록 연산 비용과 UI 표현의 한계라는 숙제가 남아있지만, Code2World가 보여준 ‘디지털 샌드박스’로서의 가능성은 AI 에이전트가 인간의 비서로서 더 안전하고 정확하게 작동할 미래를 앞당기고 있습니다.
이 연구는 단순한 벤치마크 점수 경쟁을 넘어, LLM이 실제 세계(혹은 그에 준하는 복잡한 디지털 세계)를 어떻게 모델링하고 이해해야 하는지에 대한 중요한 이정표를 제시하고 있습니다. 인공지능이 스스로 ‘만약에(What-if)’를 고민하기 시작했다는 것, 그것이 바로 Code2World가 우리에게 던지는 가장 큰 메시지입니다.
