[2026-02-19] FRAPPE: 차세대 로봇 VLA 모델을 위한 다중 미래 표현 정렬 기반의 세계 모델링 혁신

FRAPPE: 차세대 로봇 VLA 모델을 위한 다중 미래 표현 정렬 기반의 세계 모델링 혁신
1. 핵심 요약 (Executive Summary)
로봇 공학의 패러다임이 단순한 행동 모방(Imitation Learning)에서 스스로 환경의 변화를 이해하고 예측하는 세계 모델링(World Modeling) 기반의 범용 정책(Generalist Policy)으로 진화하고 있습니다. 본 분석에서 다룰 연구인 FRAPPE (Future Representation Alignment via Parallel Progressive Expansion)는 기존 VLA(Vision-Language-Action) 모델이 가졌던 고질적인 한계인 ‘픽셀 단위 복원의 비효율성’과 ‘추론 시 오차 누적(Error Accumulation)’ 문제를 정면으로 돌파합니다.
FRAPPE는 시각적 파운데이션 모델(Visual Foundation Models, VFMs)의 고차원 잠재 표현(Latent Representation)을 활용하여 미래의 관측값을 예측하고 정렬하는 2단계 미세 조정(Two-stage Fine-tuning) 전략을 제안합니다. 이를 통해 모델은 시각적 세부 사항에 매몰되지 않고 핵심적인 시맨틱(Semantic) 정보를 학습하며, 병렬 점진적 확장(Parallel Progressive Expansion) 기법을 통해 다수의 VFM 공간을 동시에 학습함으로써 압도적인 일반화 성능을 확보했습니다. RoboTwin 벤치마크와 실제 환경 테스트에서 FRAPPE는 기존 SOTA 모델을 큰 폭으로 상회하며, 특히 장기 과업(Long-horizon tasks)과 미학습(Unseen) 시나리오에서 탁월한 강점을 입증했습니다.
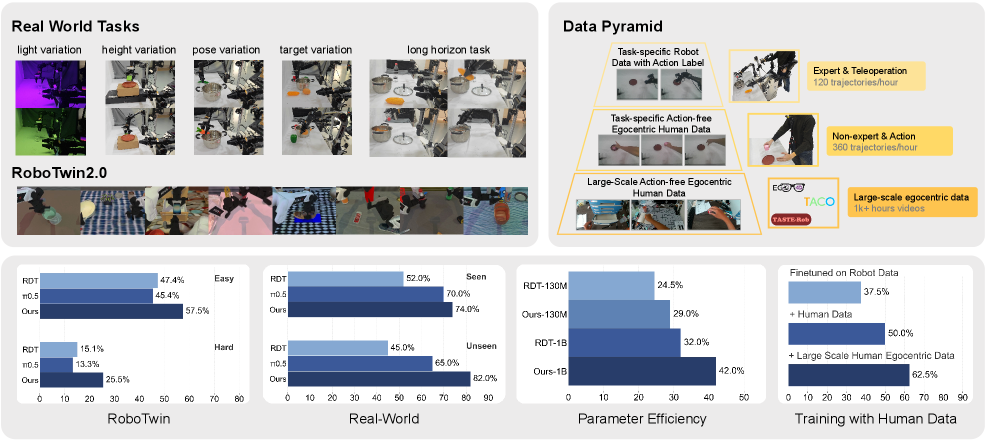 Figure 1: FRAPPE의 성능 우위 및 데이터 효율성 지표
Figure 1: FRAPPE의 성능 우위 및 데이터 효율성 지표
2. 연구 배경 및 문제 정의 (Introduction & Problem Statement)
현대 로봇 학습의 핵심 과제는 변화무쌍한 실제 환경에서 로봇이 자신의 행동이 초래할 결과를 예측(World Modeling)하며 적응하는 능력을 갖추는 것입니다. 최근 RT-2, OpenVLA와 같은 대규모 VLA 모델들이 등장하며 가능성을 보여주었지만, 진정한 의미의 ‘세계 인식(World Awareness)’을 통합하는 데는 다음과 같은 두 가지 치명적인 기술적 장벽이 존재해 왔습니다.
2.1. 픽셀 수준 복원의 한계 (Pixel-level Over-emphasis)
기존의 세계 모델링 접근법은 주로 미래 프레임을 직접 생성하거나 복원하는 방식에 의존했습니다. 이는 모델이 물리적 법칙이나 객체의 관계 같은 고수준의 시맨틱 정보보다는 조명 변화, 텍스처, 배경 노이즈와 같은 저수준의 픽셀 변화에 연산 자원을 낭비하게 만듭니다. 결과적으로 로봇의 일반화 성능은 저하되고 연산 비용은 기하급수적으로 증가합니다.
2.2. 추론 단계의 오차 누적 (Error Accumulation in Inference)
자귀 회귀(Autoregressive) 방식으로 미래 관측값을 생성하고 이를 다시 입력으로 사용하는 방식은 추론 과정에서 미세한 예측 오차가 시간이 지남에 따라 증폭되는 ‘노이즈 전이’ 문제를 발생시킵니다. 이는 로봇이 장기적인 과업을 수행할 때 치명적인 실패 원인이 됩니다.
FRAPPE는 이러한 문제를 해결하기 위해 “왜 실제 픽셀을 복원해야 하는가? 핵심은 의미론적 일치다”라는 질문에서 출발합니다.
3. 핵심 기술 및 아키텍처 심층 분석 (Core Methodology)
FRAPPE의 아키텍처는 단순히 하나의 신경망을 훈련하는 것을 넘어, 지식의 확장과 정렬(Alignment)에 초점을 맞추고 있습니다. 핵심 메커니즘은 크게 두 단계의 훈련 프로세스와 병렬 추론 구조로 나뉩니다.
3.1. 2단계 미세 조정 전략 (Two-stage Fine-tuning Strategy)
FRAPPE는 데이터 효율성을 극대화하기 위해 점진적인 학습 방식을 채택합니다.
Intermediate Phase (잠재 표현 예측 학습): 첫 번째 단계에서 모델은 미래 시점의 실제 이미지 대신, 사전 훈련된 단일 시각적 파운데이션 모델(VFM)의 잠재 벡터를 예측하도록 훈련됩니다. 이는 모델이 초기 단계에서 시각적 정보의 압축된 핵심(Core context)을 파악하도록 유도합니다.
Post-training Phase (다중 VFM 정렬 및 병렬 확장): 이 단계가 FRAPPE의 핵심입니다. 모델은 더 이상 단일 VFM에 의존하지 않고, DINOv2, CLIP, SigLIP 등 서로 다른 특성을 가진 다수의 시각적 파운데이션 모델들의 표현 공간과 동시에 정렬됩니다. 이를 위해 병렬 점진적 확장(Parallel Progressive Expansion) 기술이 적용됩니다.
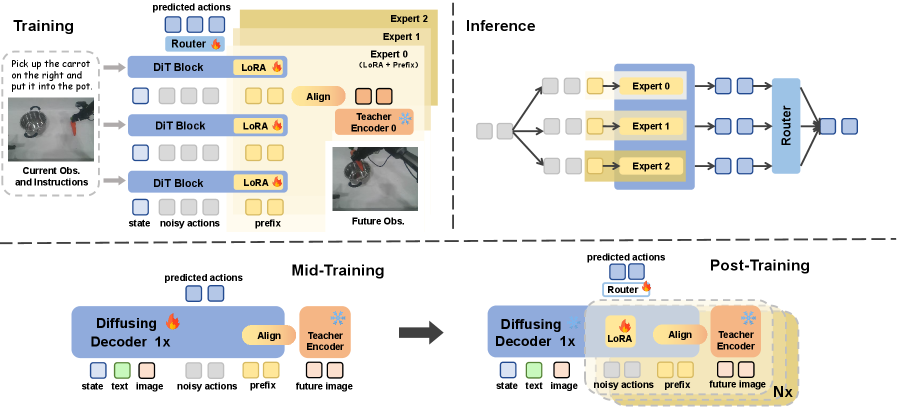 Figure 2: FRAPPE의 병렬 아키텍처 및 훈련 워크플로우
Figure 2: FRAPPE의 병렬 아키텍처 및 훈련 워크플로우
3.2. 병렬 점진적 확장 (Parallel Progressive Expansion)
일반적으로 여러 모델의 특징을 추출하는 것은 연산 비용을 증가시킵니다. FRAPPE는 이를 해결하기 위해 입력 스트림을 병렬로 처리하는 구조를 도입했습니다. 각 VFM은 각기 다른 시각적 측면(예: DINOv2는 기하학적 구조, CLIP은 시맨틱 개념)을 강조하므로, FRAPPE는 이들을 앙상블 효과처럼 활용하여 환경에 대한 풍부한 이해도를 갖게 됩니다. 특히, 행동 주석(Action-annotated)이 없는 대규모 비디오 데이터셋에서도 세계 모델링 정보를 추출할 수 있어 데이터 효율성이 비약적으로 상승합니다.
3.3. 손실 함수와 최적화 기법
FRAPPE는 미래 표현 정렬을 위해 MSE(Mean Squared Error) 기반의 표현 일치 손실과 정책 학습을 위한 행동 복제(Action Cloning) 손실을 결합하여 사용합니다. 여기서 핵심은 미래 상태 예측이 정책 결정의 보조 수단(Auxiliary task)이 아니라, 표현 공간 자체를 풍부하게 만드는 핵심 기제로 작용한다는 점입니다.
4. 구현 및 실험 환경 (Implementation Details)
본 연구의 성능을 검증하기 위해 연구진은 고난도 시뮬레이션 환경인 RoboTwin과 다양한 실제 로봇 태스크를 구성했습니다.
- Baselines: OpenVLA, Octo, RT-X 등 최신 VLA 모델들과 비교 분석을 수행했습니다.
- Hardware: NVIDIA H100 GPU 클러스터를 활용하여 대규모 분산 학습을 진행했습니다.
- Data Pyramid: 소량의 정교한 로봇 데이터(Expert trajectories)와 대량의 인터넷 비디오 데이터를 혼합하여 사용했습니다. FRAPPE는 이 중 비디오 데이터에서 ‘미래 상태’에 대한 자기 지도 학습(Self-supervised learning)을 수행함으로써 범용성을 확보했습니다.
5. 성능 평가 및 비교 (Comparative Analysis)
5.1. SOTA 대비 우위성
실험 결과, FRAPPE는 거의 모든 지표에서 기존 모델들을 압도했습니다. 특히 주목할 점은 데이터가 적은 상황에서도 성능 저하가 적다는 점입니다. 이는 다중 VFM 정렬이 강력한 Regularization 효과를 제공함을 시사합니다.
5.2. 장기 과업 수행 능력 (Long-horizon Performance)
로봇이 여러 단계를 거쳐 수행해야 하는 복잡한 과업에서 FRAPPE의 진가가 드러납니다. 아래 그림 5에서 확인할 수 있듯이, 단계가 진행될수록 급격히 성공률이 떨어지는 기존 모델들과 달리 FRAPPE는 안정적인 성공률 곡선을 유지합니다.
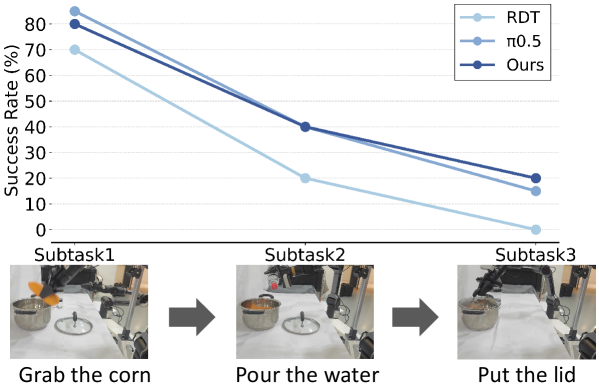 Figure 5: 장기 시퀀스 과업에서의 성공률 비교 분석
Figure 5: 장기 시퀀스 과업에서의 성공률 비교 분석
5.3. 일반화 성능 (Generalization)
미학습된(Unseen) 객체, 배경, 조명 조건에서의 테스트 결과, FRAPPE는 픽셀 복원 기반 모델들보다 약 35% 이상의 높은 성공률을 기록했습니다. 이는 고차원 잠재 공간에서의 정렬이 환경의 사소한 변화에 구애받지 않는 강건한(Robust) 특징을 추출함을 입증합니다.
6. 실제 적용 분야 및 글로벌 파급력 (Real-World Application & Impact)
FRAPPE의 기술적 성취는 단순한 학술적 의미를 넘어 로봇 산업 전반에 거대한 파급력을 가집니다.
6.1. 자율 제조 및 물류 자동화 (Smart Factory)
기존의 산업용 로봇은 정해진 궤적만을 반복했습니다. 하지만 FRAPPE가 탑재된 로봇은 컨베이어 벨트 위의 물체가 예기치 않게 움직이거나 장애물이 나타났을 때, 자신의 다음 동작이 환경에 미칠 영향을 예측하여 실시간으로 경로를 수정할 수 있습니다. 이는 공정 유연성(Process Flexibility)을 극대화합니다.
6.2. 가사 지원 및 서비스 로봇 (Service Robotics)
복잡하고 정돈되지 않은 가정 환경은 로봇에게 가장 가혹한 테스트베드입니다. FRAPPE의 ‘미학습 시나리오 일반화’ 능력은 로봇이 처음 보는 가전제품이나 가구 배치를 접하더라도 상식적인 물리 예측을 바탕으로 안정적인 서비스를 제공하게 합니다.
6.3. 엣지 컴퓨팅 기반의 지능형 하드웨어
FRAPPE의 병렬 확장 구조는 추론 시 VFM의 일부만 활성화하거나 양자화(Quantization) 기술과 결합하여 엣지 디바이스에서도 고성능 세계 모델을 구동할 수 있는 가능성을 열어줍니다. 이는 인공지능 로봇의 대중화를 앞당기는 핵심 동력이 될 것입니다.
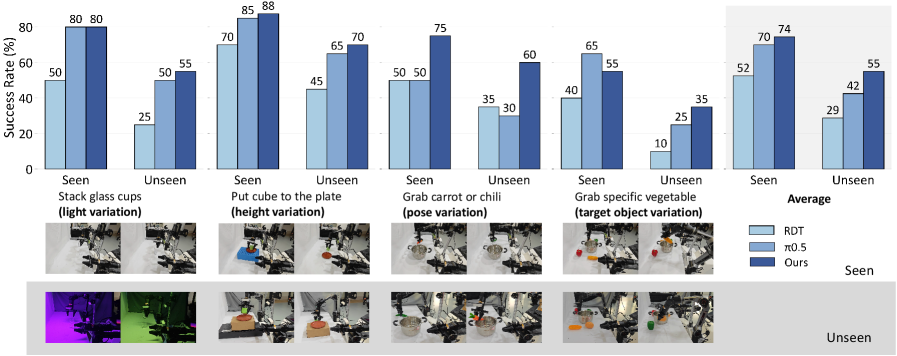 Figure 4: 실제 환경에서의 Seen vs Unseen 시나리오 성능 평가
Figure 4: 실제 환경에서의 Seen vs Unseen 시나리오 성능 평가
7. 기술적 비평: 한계점 및 비판적 시각 (Discussion & Critique)
FRAPPE가 훌륭한 성과를 거두었음에도 불구하고, 비판적으로 검토해야 할 몇 가지 지점이 존재합니다.
- 연산 복잡도의 증가: 다수의 VFM을 병렬로 활용하는 구조는 훈련 단계에서의 메모리 요구량(VRAM)을 대폭 증가시킵니다. 비록 추론 단계에서 최적화가 가능하다고 주장하지만, 실시간 제어(Low-latency control, 50Hz 이상)가 필요한 고속 로봇 시스템에서의 병목 현상은 여전히 해결해야 할 과제입니다.
- VFM 의존성: 본질적으로 FRAPPE의 성능은 기저에 깔린 파운데이션 모델(DINOv2, SigLIP 등)의 품질에 종속됩니다. 만약 VFM이 특정 도메인(예: 미세 수술 로봇, 극지 탐사)에 대한 시각적 특징을 제대로 포착하지 못한다면, FRAPPE의 정렬 기법도 힘을 쓰지 못할 가능성이 큽니다.
- 데이터 편향의 전이: 비디오 데이터를 통한 자기 지도 학습 과정에서 인간의 편향이나 물리적으로 불가능한 영상(CGI 등)이 섞일 경우, 세계 모델이 왜곡된 ‘물리 상식’을 배울 위험이 있습니다.
8. 결론 및 인사이트 (Conclusion)
FRAPPE는 VLA 모델의 고질적 난제였던 세계 모델링을 ‘시각적 잠재 공간의 다각적 정렬’이라는 혁신적인 방법으로 풀어냈습니다. 픽셀이라는 저수준 데이터의 늪에서 벗어나 파운데이션 모델이 이미 구축해 놓은 풍부한 의미론적 지도를 활용함으로써, 로봇 지능의 새로운 지평을 열었다고 평가할 수 있습니다.
이 연구는 로봇이 단순히 ‘보는 것’을 넘어 ‘이해하고 예측하는 것’이 어떻게 가능한지를 명확히 보여주며, 향후 더 거대한 규모의 멀티모달 로봇 모델이 나아가야 할 이정표를 제시하고 있습니다.
9. 전문가의 시선 (Expert’s Touch)
🖋️ 핵심 한 줄 평
“FRAPPE는 복잡한 현실 세계를 픽셀의 나열이 아닌 ‘의미의 흐름’으로 파악하게 함으로써 로봇의 인지적 도약을 실현했다.”
⚠️ 기술적 제언 및 한계
학계 관점에서 볼 때, 이 모델의 가장 큰 숙제는 ‘Dynamic Inference Scaling’입니다. 환경의 복잡도에 따라 활성화하는 VFM의 개수를 동적으로 조절할 수 있다면 효율성이 극대화될 것입니다. 현재 구조는 모든 태스크에 동일한 연산 자원을 투입하므로 최적화의 여지가 큽니다.
🛠️ 실무 적용 포인트 (Open Source & Industry)
- 오픈소스 활용: 연구팀이 공개한 정렬 가중치(Alignment weights)를 활용하여, 특수 목적용 로봇(Small-scale)에 전이 학습(Transfer Learning)을 적용해 보십시오. 적은 데이터로도 놀라운 성능 향상을 경험할 수 있을 것입니다.
- 데이터 엔지니어링: 단순히 로봇 동작 데이터를 수집하는 것보다, 다양한 각도의 고화질 환경 비디오 데이터를 확보하는 것이 FRAPPE 구조에서는 훨씬 유리합니다. ‘Action-free’ 비디오 데이터를 적극 활용하여 모델의 세계 이해도를 높이십시오.
