[2026-02-12] [심층 분석] GigaBrain-0.5M*: 월드 모델 기반 강화학습(RL)으로 진화한 차세대 VLA 모델의 탄생

[심층 분석] GigaBrain-0.5M*: 월드 모델 기반 강화학습(RL)으로 진화한 차세대 VLA 모델의 탄생
1. 핵심 요약 (Executive Summary)
로보틱스 분야에서 인공지능의 역할은 단순한 ‘인식’을 넘어 ‘실행’과 ‘예측’으로 빠르게 진화하고 있습니다. 오늘 분석할 GigaBrain-0.5M*는 기존의 시각-언어-행동(Vision-Language-Action, VLA) 모델이 가진 태생적 한계를 극복하기 위해 월드 모델(World Model)과 강화학습(Reinforcement Learning, RL)을 결합한 최첨단 아키텍처입니다.
이 모델의 핵심은 RAMP(Reinforcement leArning via world Model-conditioned Policy) 프레임워크에 있습니다. 단순히 현재 상태에서 행동을 예측하는 것을 넘어, 월드 모델을 통해 미래 상태를 시뮬레이션하고 이를 정책(Policy) 결정의 조건으로 활용함으로써 복잡한 장기 실행(Long-horizon) 과업에서 압도적인 성능을 보여줍니다. 10,000시간 이상의 로봇 조작 데이터를 학습한 GigaBrain-0.5를 기반으로 하며, 세탁물 접기, 박스 포장, 에스프레소 제조와 같은 고난도 작업에서 기존 RECAP 베이스라인 대비 약 30% 이상의 성능 향상을 달성했습니다.
2. 연구 배경 및 문제 정의 (Introduction & Problem Statement)
2.1. 기존 VLA 모델의 한계점
RT-2, Octo 등 기존의 VLA 모델들은 대규모 멀티모달 데이터셋을 통해 로봇 조작 분야에서 괄목할 만한 성과를 거두었습니다. 그러나 이러한 모델들은 대부분 Direct Action Prediction(직접 행동 예측) 방식에 의존합니다. 즉, 현재의 관측값(Observation)을 기반으로 다음 행동 청크(Action chunk)를 즉각적으로 출력하는 방식입니다.
이러한 방식은 다음과 같은 두 가지 치명적인 결함을 가집니다:
- 제한된 장면 이해(Constrained Scene Understanding): 정적인 이미지나 짧은 비디오 클립만으로는 물리적 공간의 복잡한 상관관계를 완벽히 파악하기 어렵습니다.
- 약한 미래 예측 능력(Weak Future Anticipation): 자신의 행동이 환경에 미칠 영향을 미리 계산하지 못하기 때문에, 실수가 발생했을 때 이를 능동적으로 수정하거나 장기적인 계획을 유지하는 능력이 부족합니다.
2.2. 월드 모델의 부상과 기회
최근 Sora나 Genie와 같은 비디오 생성 모델들은 웹 스케일의 데이터를 통해 물리 법칙이 투영된 시공간적 추론(Spatiotemporal Reasoning) 능력을 입증했습니다. 로봇 공학자들은 질문하기 시작했습니다. “비디오 월드 모델이 가진 ‘물리적 상상력’을 로봇의 제어 정책에 직접 주입할 수 있다면 어떨까?”
GigaBrain-0.5M*는 바로 이 질문에 대한 해답입니다. 월드 모델을 단순한 보조 도구가 아닌, RL 학습의 핵심 컨디션으로 활용하여 ‘생각하고 움직이는’ 로봇 지능을 구현하고자 했습니다.
3. 핵심 기술 및 아키텍처 심층 분석 (Core Methodology)
GigaBrain-0.5M*의 혁신은 RAMP(Reinforcement leArning via world Model-conditioned Policy)라는 4단계 파이프라인에 응축되어 있습니다.
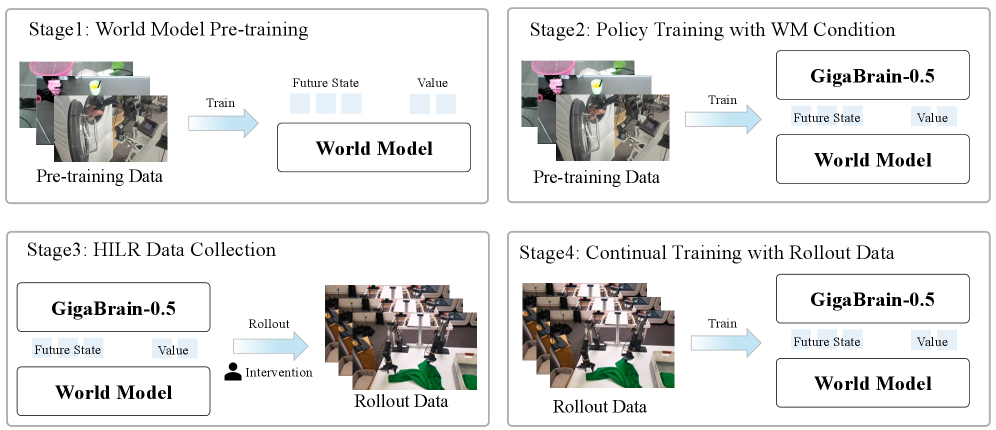 그림 2: RAMP 프레임워크의 4단계 파이프라인 개요. 월드 모델 사전 학습부터 인간 개입형 데이터 수집, 지속적 학습에 이르는 폐쇄 루프(Closed-loop) 과정을 보여줍니다.
그림 2: RAMP 프레임워크의 4단계 파이프라인 개요. 월드 모델 사전 학습부터 인간 개입형 데이터 수집, 지속적 학습에 이르는 폐쇄 루프(Closed-loop) 과정을 보여줍니다.
3.1. 1단계: 월드 모델 사전 학습 (World Model Pre-training)
연구팀은 먼저 방대한 비디오 데이터를 사용하여 미래 상태를 예측하는 월드 모델을 학습시킵니다. 이 모델은 단순히 다음 프레임을 생성하는 것이 아니라, 잠재 공간(Latent Space) 내에서 미래 상태 예측(Future State Prediction)과 가치 추정(Value Estimation)을 위한 통합 표현 공간을 구축합니다. 이는 로봇이 물리적 인과관계를 이해하는 기초가 됩니다.
3.2. 2단계: 월드 모델 조건부 정책 학습 (Policy Training with World Model Condition)
기존의 GigaBrain-0.5 모델에 월드 모델의 잠재 표현(Latent Representation)을 명시적인 조건(Condition)으로 주입합니다. 이를 통해 정책 네트워크는 현재의 시각 정보뿐만 아니라, 월드 모델이 제시하는 ‘예상되는 미래’를 참고하여 최적의 행동을 선택하게 됩니다. 이것이 바로 모델 이름 뒤에 ‘M(World Model-based)’이 붙은 이유입니다.
3.3. 3단계: 인간 개입형 롤아웃(HILR) 데이터 수집
자율적인 실행만으로는 복잡한 코너 케이스(Corner Case)를 극복하기 어렵습니다. RAMP는 Human-in-the-Loop Rollout (HILR) 방식을 채택했습니다. 로봇이 작업을 수행하다가 실패하거나 불확실한 상황에 직면하면 전문가가 개입하여 수정을 가합니다. 이 과정에서 성공 궤적뿐만 아니라 ‘수정 신호(Corrective Signal)’가 포함된 고품질 데이터가 축적됩니다.
3.4. 4단계: 롤아웃 데이터를 이용한 지속적 학습 (Continual Training)
수집된 데이터를 바탕으로 정책을 지속적으로 업데이트합니다. 이는 단순한 모방 학습(Imitation Learning)을 넘어, 월드 모델이 제공하는 가치 함수(Value Function)를 보상으로 활용하는 강화학습적 기법이 결합되어 정책의 견고함(Robustness)을 극대화합니다.
4. 구현 및 실험 환경 (Implementation Details & Experiment Setup)
4.1. 학습 데이터 스케일
GigaBrain-0.5M*의 베이스 모델인 GigaBrain-0.5는 10,000시간 이상의 실제 로봇 조작 데이터로 학습되었습니다. 이는 현재 공개된 로봇 모델 중 손꼽히는 규모이며, RoboChallenge 벤치마크에서 1위를 차지한 기록이 그 성능을 뒷받침합니다.
4.2. 하드웨어 구성
본 연구는 다양한 폼팩터에서의 범용성을 입증하기 위해 두 가지 주요 플랫폼을 사용했습니다.
- PiPER 로봇 암: 정밀한 박스 포장 및 물체 조작 테스트용.
- G1 휴머노이드 로봇: 전신 제어 및 이동성이 결합된 복잡한 과업 수행용.
4.3. 테스트 시나리오
단순한 집기(Pick-and-place)를 넘어, 다음과 같은 Long-horizon 과업을 설정했습니다.
- Laundry Folding: 유연한 물체(비정형 객체)를 다루는 고난도 작업.
- Box Packing: 공간 추론이 필요한 정밀 작업.
- Espresso Preparation: 여러 도구를 순차적으로 사용하는 복합 시퀀스 작업.
5. 성능 평가 및 비교 (Comparative Analysis)
실험 결과는 놀라웠습니다. RAMP 프레임워크를 적용한 GigaBrain-0.5M*는 기존의 최신 기법인 RECAP 대비 확연한 우위를 점했습니다.
- 성능 향상 폭: 세탁물 접기, 박스 포장 등 핵심 과업에서 성공률이 약 30% 향상되었습니다.
- 장기 실행 안정성: 수백 단계에 이르는 긴 작업 과정에서도 오류가 누적되지 않고 월드 모델을 통해 지속적으로 궤적을 수정하는 모습을 보였습니다.
- 적응성(Adaptability): 처음 본 조명 조건이나 물체의 위치 변화에도 월드 모델의 일반화 능력을 바탕으로 유연하게 대처했습니다.
특히, 기존 VLA 모델들이 특정 각도나 배경에서 쉽게 무너지는 것과 달리, GigaBrain-0.5M*는 월드 모델이 구축한 ‘물리적 불변성’ 덕분에 훨씬 더 높은 견고함을 보여주었습니다.
6. 실제 적용 분야 및 글로벌 파급력 (Real-World Application & Impact)
이 기술은 단순한 연구실의 결과물을 넘어 산업 전반에 엄청난 파급력을 미칠 것으로 예상됩니다.
6.1. 물류 및 풀필먼트 센터
박스 포장(Box Packing) 실험의 성공은 물류 자동화의 마지막 퍼즐을 맞추는 것과 같습니다.
 그림 5: 실제 환경에서 PiPER 로봇 암을 이용해 박스 포장 작업을 수행 중인 GigaBrain-0.5.
그림 5: 실제 환경에서 PiPER 로봇 암을 이용해 박스 포장 작업을 수행 중인 GigaBrain-0.5.
기존의 정형화된 공정 라인이 아니라, 다양한 크기의 물건을 임의의 상자에 최적으로 배치해야 하는 시나리오에서 GigaBrain-0.5M*의 공간 추론 능력은 핵심적인 가치를 발휘합니다.
6.2. 서비스 및 가사 로봇
휴머노이드 로봇 G1에 탑재된 GigaBrain-0.5M*는 우리가 꿈꾸던 가사 도우미 로봇의 가능성을 보여줍니다.
 그림 6: G1 휴머노이드 로봇에 탑재되어 실제 환경에서 박스 운반 과업을 수행하는 모습.
그림 6: G1 휴머노이드 로봇에 탑재되어 실제 환경에서 박스 운반 과업을 수행하는 모습.
단순히 물건을 옮기는 것을 넘어, 주변 환경의 변화(사람의 통행, 장애물 등)를 월드 모델로 예측하며 안전하고 정확하게 목표를 달성합니다. 이는 서비스 로봇 시장의 폭발적인 성장을 견인할 기술적 변곡점이 될 것입니다.
7. 한계점 및 기술적 비평 (Discussion: Limitations & Critical Critique)
전문가적 시각에서 볼 때, GigaBrain-0.5M*가 완벽한 것은 아닙니다. 몇 가지 비판적 검토가 필요합니다.
- 추론 비용(Inference Cost): 정책 네트워크 외에 거대한 월드 모델을 동시에 실행하거나 조건부로 활용하는 것은 계산 리소스를 많이 소모합니다. 엣지 디바이스에서의 실시간성(Real-time latency) 확보가 관건이 될 것입니다.
- HILR의 확장성 문제: 30%의 성능 향상이 인간 전문가의 개입(Human-in-the-Loop) 덕분이라면, 수만 대의 로봇을 학습시키기 위해 필요한 전문가 데이터를 어떻게 스케일링할 것인가에 대한 의문이 남습니다. 인간의 개입 없이 스스로 월드 모델을 정교화하는 Self-supervised RL 단계로의 진화가 필요합니다.
- 물리적 정확도의 한계: 비디오 월드 모델이 생성한 ‘상상’이 실제 물리 법칙과 미세하게 다를 경우(예: 마찰력, 미끄러짐 등), 정책 결정에 오히려 독이 될 수 있습니다. 잠재 공간의 물리적 정합성을 어떻게 보장할지에 대한 더 깊은 연구가 필요합니다.
8. 결론 (Conclusion)
GigaBrain-0.5M*는 VLA 모델이 단순히 ‘데이터를 많이 먹인 모델’에서 벗어나, 환경을 이해하고 미래를 예측하는 ‘지능형 에이전트’로 진화하고 있음을 보여주는 이정표적 연구입니다. 월드 모델과 강화학습의 결합은 로봇이 복잡한 세상을 헤쳐 나가는 데 필요한 강력한 도구가 될 것입니다.
우리는 이제 로봇이 프로그래밍된 대로만 움직이는 시대를 지나, 자신의 행동 결과를 예측하고 스스로 교정하며 목표를 달성하는 시대로 진입하고 있습니다. GigaBrain-0.5M*가 열어젖힌 이 문은 머지않아 우리 일상 속으로 휴머노이드 로봇이 들어오는 날을 앞당길 것입니다.
이 포스팅은 최신 AI 기술의 흐름을 분석하고 개발자 및 비즈니스 리더들에게 인사이트를 제공하기 위해 작성되었습니다.
