[2026-02-04] [심층 분석] 숨겨진 추론의 벽을 넘다: Privileged Information Distillation(π-Distill)을 통한 차세대 에이전트 모델 학습 전략

[심층 분석] 숨겨진 추론의 벽을 넘다: Privileged Information Distillation(π-Distill)을 통한 차세대 에이전트 모델 학습 전략
1. 핵심 요약 (Executive Summary)
최근 대규모 언어 모델(LLM) 시장은 ‘추론 능력의 폐쇄화’라는 거대한 전환점에 직면해 있습니다. OpenAI의 o1과 같은 최첨단(Frontier) 모델들은 결과물(Action)은 제공하지만, 그 결과에 도달하기까지의 사고 과정인 Chain-of-Thought(CoT)를 외부로 노출하지 않습니다. 이는 기존의 지식 증류(Knowledge Distillation) 방식, 즉 교사 모델의 사고 과정을 학생 모델이 그대로 모방하게 하던 SFT(Supervised Fine-Tuning) 전략을 무력화시킵니다.
본 분석에서 다룰 연구인 “Privileged Information Distillation for Language Models”는 이러한 제약 환경을 돌파하기 위한 혁신적인 프레임워크인 π-Distill과 OPSD(On-Policy Self-Distillation)를 제안합니다. 이 방법론의 핵심은 학습 시에만 사용할 수 있는 ‘특권 정보(Privileged Information, PI)’를 활용하여, 추론 과정이 생략된 행동 궤적만으로도 학생 모델이 교사 모델의 복잡한 논리 구조를 내재화하도록 만드는 것입니다. 실험 결과, 이 방식은 교사 모델의 CoT를 직접 사용하는 기존의 업계 표준(SFT+RL)보다 더 우수한 성능과 일반화 능력을 보여주었습니다.
2. 연구 배경 및 문제 정의 (Introduction & Problem Statement)
2.1. 지식 증류의 위기: ‘블랙박스’가 된 추론
전통적으로 모델 증류는 교사 모델이 생성한 풍부한 중간 데이터(Logits, CoT 등)를 학생 모델이 학습 데이터로 삼는 방식이었습니다. 하지만 현재의 상용 프런티어 모델들은 보안과 비즈니스 전략상의 이유로 내부 추론 과정을 숨기고 최종 API 응답(Action)만을 제공합니다.
이러한 상황에서 발생하는 문제는 다음과 같습니다.
- 관찰 불가능한 추론(Unobservable Reasoning): 성공적인 결과는 관찰되지만, 왜 그 행동이 최선이었는지에 대한 논리적 근거가 부재합니다.
- 데이터 효율성 저하: 단순 행동 모방(Behavior Cloning)만으로는 복잡하고 긴 호흡(Long-horizon)을 가진 에이전트 태스크를 해결하기 어렵습니다.
- RL의 한계: 보상(Reward) 기반의 강화학습(RL)은 탐색 공간(Exploration Space)이 너무 넓어 초기 학습 속도가 매우 느립니다.
2.2. Privileged Information(PI)의 정의
본 논문은 ‘Privileged Information(PI)’이라는 개념을 언어 모델 학습에 도입합니다. PI란 “학습 시점에는 가용하지만 추론(Inference) 시점에는 사용할 수 없는 정보”를 의미합니다. 예를 들어, 미래의 성공적인 행동 궤적, 환경의 숨겨진 상태값, 혹은 교사 모델의 도구 호출(Tool call) 기록 등이 이에 해당합니다.
3. 핵심 기술 및 아키텍처 심층 분석 (Core Methodology)
본 논문은 PI를 활용하는 두 가지 주요 알고리즘을 제안합니다.
3.1. π-Distill: 공동 매개변수화 기반 증류
π-Distill의 가장 독창적인 점은 교사 모델($\pi^T$)과 학생 모델($\pi^S$)이 동일한 모델 매개변수($ heta$)를 공유한다는 것입니다.
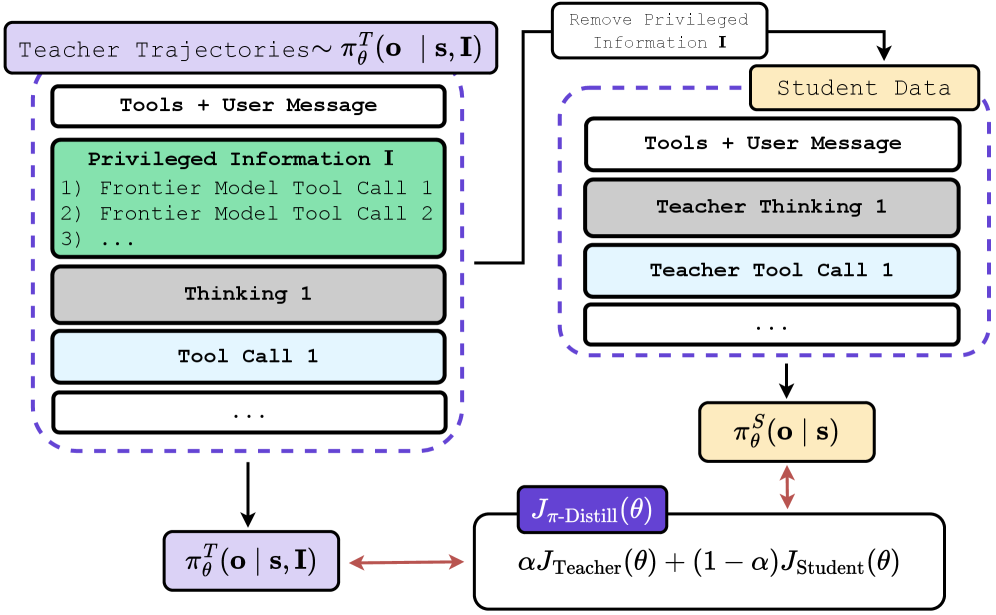 Figure 1: π-Distill 프레임워크 개요. 성공 궤적을 PI로 변환하여 교사 정책을 샘플링하고, 동일 모델 내의 학생 정책과 공동 학습합니다.
Figure 1: π-Distill 프레임워크 개요. 성공 궤적을 PI로 변환하여 교사 정책을 샘플링하고, 동일 모델 내의 학생 정책과 공동 학습합니다.
- 메커니즘:
교사 정책 $\pi^T$는 상태(s)와 특권 정보(I)를 모두 입력받습니다: $\pi^T(a s, I)$ 학생 정책 $\pi^S$는 상태(s)만을 입력받습니다: $\pi^S(a s)$ - 학습 과정에서 교사는 PI를 통해 정답에 쉽게 도달하며 학생을 가이드하고, 학생은 동일한 가중치 내에서 PI 없이도 유사한 출력 분포를 내도록 최적화됩니다.
- 손실 함수(Loss Function): \(L_{joint}(\theta) = E[L_{CE}(\pi^T_{\theta}) + L_{CE}(\pi^S_{\theta}) + \lambda D_{KL}(\pi^T_{\theta} || \pi^S_{\theta})]\) 여기서 $\lambda$는 교사와 학생 간의 정렬을 조절하는 하이퍼파라미터입니다.
3.2. OPSD (On-Policy Self-Distillation)
OPSD는 강화학습(RL) 프레임워크 내에서 PI를 활용합니다. 표준 RL은 높은 보상을 찾는 과정에서 안정성이 떨어지는 반면, OPSD는 PI에 조건화된 교사 모델을 ‘참조 모델(Reference Model)’로 활용하여 학생의 정책이 너무 멀어지지 않도록 제어합니다.
- 특징: 표준 RL의 KL Penalty는 보통 사전 학습된 모델(Pre-trained model)을 기준으로 하지만, OPSD는 실시간으로 학습 중인 PI-Conditioned Teacher를 기준으로 Reverse-KL Divergence를 계산합니다. 이는 학생 모델이 단순 보상 극대화를 넘어, PI가 암시하는 ‘성공의 지름길’을 추종하게 만듭니다.
3.3. PI의 구성 방식 (Deriving PI)
프런티어 모델로부터 CoT를 얻을 수 없는 상황에서 연구진은 다음과 같은 세 가지 형태의 PI를 실험했습니다.
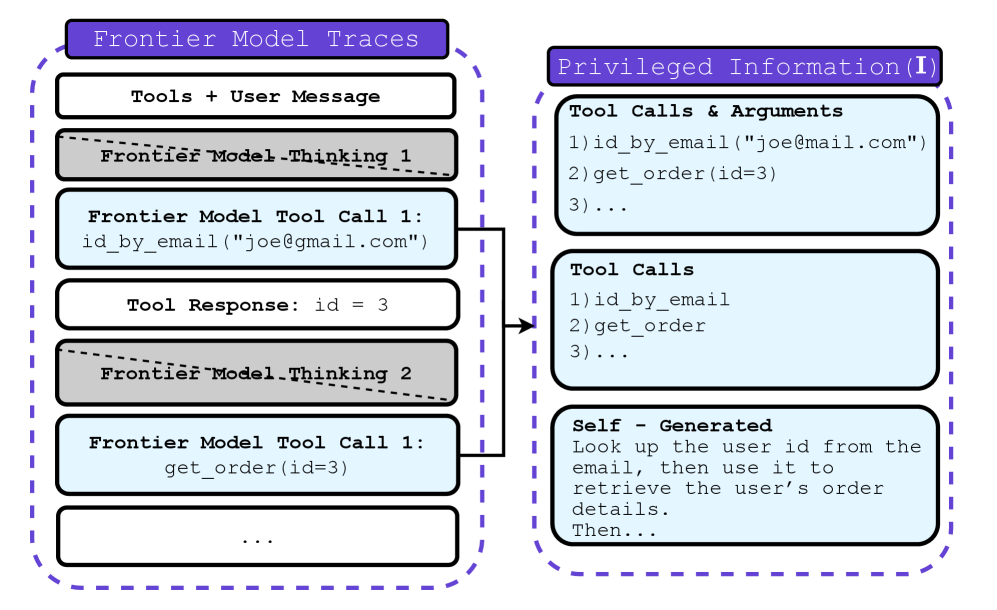 Figure 3: 프런티어 모델 궤적에서 추출한 세 가지 유형의 PI (Tool Calls, Tool Calls Only, Self-Generated Hints).
Figure 3: 프런티어 모델 궤적에서 추출한 세 가지 유형의 PI (Tool Calls, Tool Calls Only, Self-Generated Hints).
- Tool Calls & Arguments: 프런티어 모델이 사용한 도구와 그 인자값들을 그대로 PI로 제공합니다. 가장 강력한 힌트가 됩니다.
- Tool Calls Only: 어떤 도구를 썼는지만 알려주고, 세부 인자값은 학생이 스스로 추론하게 합니다.
- Self-Generated Hints: 학생 모델 스스로가 성공한 궤적을 요약하여 힌트를 생성하게 합니다. 이는 외부 데이터 의존도를 낮추는 전략입니다.
4. 구현 및 실험 환경 (Implementation Details)
연구진은 모델의 에이전틱(Agentic) 능력을 평가하기 위해 다음과 같은 까다로운 벤치마크를 선정했습니다.
- TravelPlanner: 복잡한 제약 조건 하에서 여행 일정을 짜는 작업으로, 다단계 계획(Multi-step planning) 능력이 필수적입니다.
- τ-Bench (Retail & Airline): 실제 서비스 환경과 유사한 도구 호출 및 사용자 상응 능력을 평가합니다.
- 모델 라인업:
- Qwen3-8B: 최신 오픈소스 모델로 메인 실험 진행.
- Llama-3-8B: 일반화 성능 검증을 위해 사용.
- 교사 데이터 소스: GPT-4o 등 프런티어 모델의 성공 궤적(CoT 제외)을 사용.
5. 성능 평가 및 비교 (Comparative Analysis)
5.1. 주요 결과 (Main Results)
실험 결과는 놀라웠습니다. 교사 모델의 추론 과정(CoT)을 전혀 보지 못한 π-Distill이, CoT를 데이터셋에 포함해 SFT를 진행한 모델보다 월등한 성능을 보였습니다.
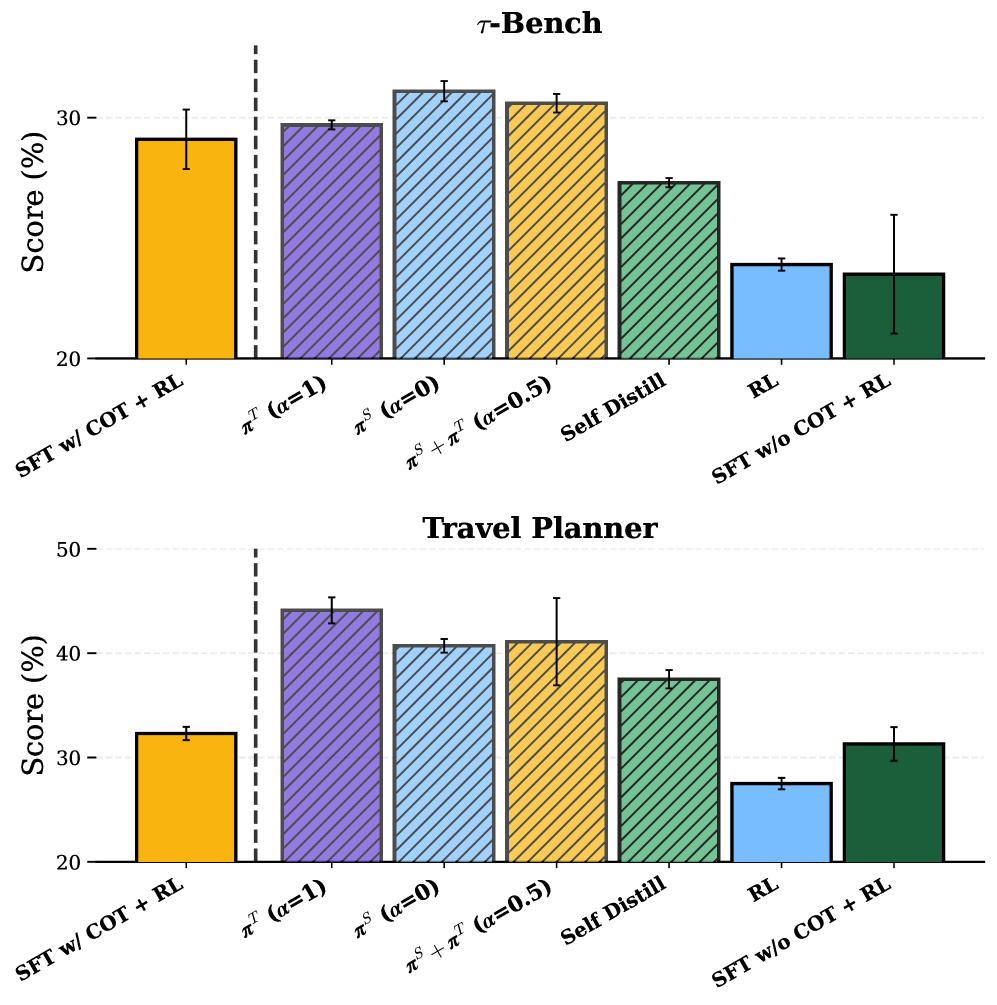 Figure 2: TravelPlanner 및 τ-Bench에서의 성능 비교. π-Distill과 OPSD가 기존 SFT+RL 방식을 크게 앞지릅니다.
Figure 2: TravelPlanner 및 τ-Bench에서의 성능 비교. π-Distill과 OPSD가 기존 SFT+RL 방식을 크게 앞지릅니다.
- 에이전트 성공률: π-Distill은 TravelPlanner에서 기본 RL 대비 약 2배 이상의 성능 향상을 보였으며, 이는 SFT w/ CoT + RL(CoT 데이터를 직접 학습에 사용한 경우)보다도 높은 수치입니다.
- PI의 밀도와 성능: Tool Call뿐만 아니라 학생 모델이 스스로 생성한 빈약한 힌트(Self-Generated Hints)만으로도 상당한 성능 향상이 관찰되었습니다. 이는 PI가 반드시 완벽할 필요는 없으며, ‘탐색의 방향’만 제시해 주어도 모델이 충분히 학습할 수 있음을 시사합니다.
5.2. 일반화 및 잊어버림 방지 (Generalization & Forgetting)
일반적으로 특정 도메인의 RL을 수행하면 모델의 범용적인 능력이 감퇴(Catastrophic Forgetting)하는 경향이 있습니다. 하지만 π-Distill은 OOD(Out-of-Domain) 벤치마크인 GEM(Search-tool benchmark)에서도 높은 성능을 유지했습니다.
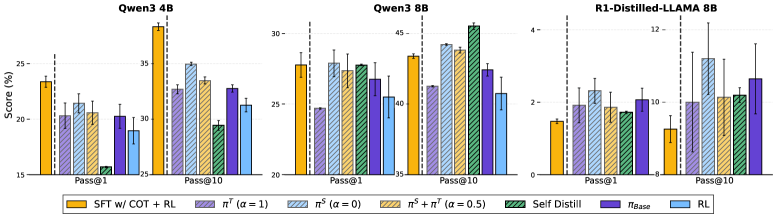 Figure 4: GEM 벤치마크 결과. π-Distill은 표준 RL에 비해 지식 유지 능력이 탁월하며, SFT w/ CoT보다 높은 일반화 성능을 보여줍니다.
Figure 4: GEM 벤치마크 결과. π-Distill은 표준 RL에 비해 지식 유지 능력이 탁월하며, SFT w/ CoT보다 높은 일반화 성능을 보여줍니다.
6. 실제 적용 분야 및 글로벌 파급력 (Real-World Application)
Senior AI Scientist로서 필자는 이 기술이 산업계에 미칠 영향이 지대하다고 판단합니다.
- 기업 전용 폐쇄형 에이전트 구축: 기업들은 GPT-4o의 성능을 원하지만, 데이터 유출 우려로 직접 API를 쓰기 꺼려합니다. π-Distill을 사용하면 GPT-4o의 ‘결과’만 수집하여(추론 과정 없이도) 그에 필적하는 온프레미스 소형 모델을 구축할 수 있습니다.
- 추론 비용 절감: CoT는 토큰 소모량이 많아 비용과 지연 시간(Latency)을 발생시킵니다. π-Distill로 학습된 학생 모델은 CoT 없이도 ‘직관적’으로 정답 궤적을 찾아내므로, 운영 비용을 획기적으로 낮출 수 있습니다.
- 전문가 시스템(Expert Systems): 의료, 법률 등 정답 궤적은 명확하지만 사고 과정은 설명하기 복잡한 영역에서, 전문가의 행동 로그만을 PI로 활용해 모델을 고도화할 수 있습니다.
7. 한계점 및 기술적 비평 (Discussion: Limitations & Critique)
본 연구가 매우 뛰어나지만, 몇 가지 비판적 시각을 가질 필요가 있습니다.
- PI 의존성: 결국 ‘성공한 궤적’이 어느 정도 확보되어야 합니다. 극도로 어려운 태스크에서 프런티어 모델조차 성공률이 낮다면 PI를 생성하는 것 자체가 병목이 될 것입니다.
- Joint Training의 복잡도: 동일 모델 내에서 $\pi^T$와 $\pi^S$를 동시에 학습시키는 과정은 배치 사이즈와 메모리 관리 측면에서 까다로울 수 있습니다. 특히 $\lambda$ 파라미터에 대한 민감도 분석이 더 필요해 보입니다.
- 암묵적 CoT의 한계: 논문은 학생 모델이 CoT 없이도 성공한다고 주장하지만, 이는 결국 학생 모델이 내부적으로 CoT에 해당하는 연산을 ‘압축’해서 수행한다는 뜻입니다. 이 압축 과정에서 해석 가능성(Interpretability)이 완전히 상실된다는 점은 안전성 측면에서 우려될 수 있습니다.
8. 결론 및 인사이트 (Conclusion)
“Privileged Information Distillation”은 모델 증류의 패러다임을 ‘설명 모방’에서 ‘역량 전이’로 바꾸었습니다. 교사 모델이 친절하게 설명해주지 않아도, 그가 남긴 발자국(PI)만으로 학생은 충분히 스스로의 길을 개척할 수 있음을 증명했습니다.
특히 π-Distill이 보여준 성능은 우리가 흔히 믿어왔던 “데이터(CoT)가 많을수록 좋다”는 상식에 반문을 던집니다. 때로는 명시적인 가이드보다, 학습 시에만 주어지는 적절한 ‘힌트’와 ‘자율적 탐색’의 결합이 더 견고한 지능을 만들어냅니다. 앞으로 오픈소스 진영이 폐쇄형 프런티어 모델과의 격차를 줄이는 데 있어, 이 π-Distill 프레임워크는 가장 강력한 무기 중 하나가 될 것입니다.
전문가 한 줄 평: “프런티어 모델의 ‘입’은 막혔을지 몰라도, 그들의 ‘발자취’를 통해 지능을 훔치는 시대가 열렸다.”
