[2026-02-08] 로봇의 지능적 '고민'을 구현하다: RD-VLA, 잠재적 반복 추론을 통한 VLA 모델의 혁신적 확장

1. 핵심 요약 (Executive Summary)
현대 로봇 공학의 가장 큰 화두는 Vision-Language-Action (VLA) 모델이 어떻게 실시간성(Real-time)과 복잡한 추론(Reasoning) 능력을 동시에 확보할 것인가 하는 점입니다. 기존의 VLA 모델들은 단순한 동작이나 복잡한 조작에 상관없이 동일한 계산 비용을 지불하는 고정된 구조를 가지고 있었습니다. 이는 자원이 제한된 로봇 환경에서 비효율적일 뿐만 아니라, 깊은 사고가 필요한 작업에서 성능의 한계를 드러냈습니다.
최근 공개된 Recurrent-Depth VLA (RD-VLA)는 이러한 문제를 해결하기 위해 ‘잠재적 반복 추론(Latent Iterative Reasoning)’이라는 획기적인 개념을 도입했습니다. 핵심은 텍스트 기반의 Chain-of-Thought(CoT) 방식 대신, 잠재 공간(Latent space) 내에서 가중치를 공유하는(Weight-tied) 순환 코어를 통해 계산 깊이를 동적으로 조절하는 것입니다. 이를 통해 RD-VLA는 기존 CoT 기반 VLA 대비 최대 80배의 속도 향상과 상수 수준의 메모리 점유율을 달성하면서도, 난도가 높은 작업에서 성공률을 0%에서 90% 이상으로 끌어올리는 놀라운 성과를 거두었습니다.
본 칼럼에서는 시니어 AI 사이언티스트의 시각에서 RD-VLA의 아키텍처적 혁신성과 이것이 로보틱스 산업에 미칠 파급력을 심층 분석합니다.
2. 연구 배경 및 문제 정의 (Introduction & Problem Statement)
고정된 계산 비용의 딜레마
기존의 RT-2나 OpenVLA와 같은 모델들은 트랜스포머 아키텍처를 기반으로 하며, 입력 데이터가 모델을 통과할 때 정해진 수의 레이어를 거치게 됩니다. 이는 ‘팔을 1cm 이동하라’는 단순한 명령과 ‘여러 장애물을 피해 컵을 집어라’라는 복잡한 명령에 대해 똑같은 에너지를 소비한다는 뜻입니다. 인간이 쉬운 일은 직관적으로(System 1), 어려운 일은 숙고하여(System 2) 처리하는 것과는 대조적입니다.
CoT의 한계: 연속적 액션 공간의 부적합성
언어 모델에서 성능을 높이는 ‘테스트 시간 계산량 확장(Test-time Compute Scaling)’ 기술로 Chain-of-Thought(CoT)가 주목받아 왔습니다. 하지만 로보틱스 분야에서 CoT를 적용하는 데는 두 가지 치명적인 문제가 있습니다.
- 메모리 폭발: 추론 토큰이 길어질수록 KV 캐시가 선형적으로 증가하여 로봇의 온보드 메모리를 압도합니다.
- 연속적 데이터 처리의 어려움: 텍스트와 달리 로봇의 액션은 연속적인 수치(Continuous action space)로 표현되는 경우가 많아, 이를 토큰화하여 문장처럼 생성하는 방식은 비효율적이고 정밀도가 떨어집니다.
RD-VLA 연구진은 바로 이 지점에서 질문을 던졌습니다. “토큰을 생성하지 않고도 모델 내부의 잠재 상태를 반복적으로 정제(Refinement)함으로써 사고의 깊이를 더할 수는 없을까?”
3. 핵심 기술 및 아키텍처 심층 분석 (Core Methodology)
RD-VLA의 핵심은 모델의 깊이를 물리적 레이어의 수가 아닌, ‘순환 횟수(Iterations)’로 정의한 것입니다.
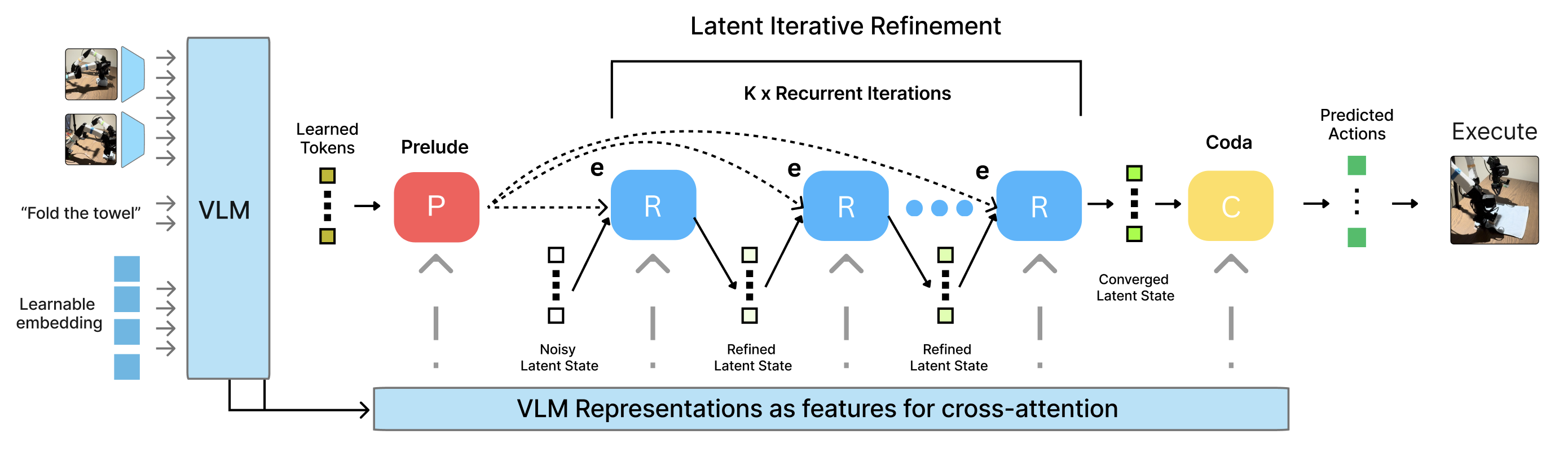 그림 1: RD-VLA의 아키텍처 구조. 서사(Prelude), 순환 코어(Recurrent Core), 종결(Coda)의 3단계로 구성된다.
그림 1: RD-VLA의 아키텍처 구조. 서사(Prelude), 순환 코어(Recurrent Core), 종결(Coda)의 3단계로 구성된다.
1) 구조적 구성 요소
RD-VLA는 크게 세 부분으로 나뉩니다.
- Prelude (P): 학습된 쿼리(Learned Queries)를 VLM의 중간 레이어 특징(Features)에 크로스 어텐션(Cross-attention)시켜 초기 맥락을 파악합니다.
- Recurrent Core (R): 가중치가 고정된(Weight-tied) 트랜스포머 블록입니다. 여기서 ‘Noisy Latent Scratchpad’라고 불리는 잠재 상태가 반복적으로 업데이트됩니다. 매 반복마다 VLM의 최종 출력과 로봇의 현재 상태(Proprioception)를 참조하여 액션을 정교화합니다.
- Coda (C): 충분히 수렴된 잠재 상태를 최종적인 로봇 액션(Action chunk)으로 디코딩합니다.
2) 잠재적 반복 정제 (Latent Iterative Refinement)
이 모델의 백미는 가중치 공유(Weight-sharing)입니다. 수십 개의 서로 다른 레이어를 쌓는 대신, 하나의 강력한 레이어를 반복해서 사용함으로써 파라미터 수는 일정하게 유지하면서도 논리적인 깊이를 무한히 확장할 수 있습니다. 이는 수학적으로 고정점 반복(Fixed-point iteration)과 유사한 효과를 냅니다.
3) TBPTT를 이용한 학습
반복적인 구조를 안정적으로 학습시키기 위해 연구진은 Truncated Backpropagation Through Time (TBPTT)을 사용했습니다. 이는 RNN 학습에서 주로 쓰이는 기법으로, 잠재 상태가 반복을 거듭할수록 정답 액션에 가까워지도록 유도합니다. 특히 학습 시 ‘Noisy Scratchpad’ 기법을 통해 초기값에 대한 강건성(Robustness)을 확보한 점이 인상적입니다.
4) 적응적 정지 기준 (Adaptive Stopping Criterion)
모든 작업에 풀 파워(Full iterations)를 쓸 필요는 없습니다. RD-VLA는 잠재 상태의 변화량(Cosine similarity 등)을 모니터링하여, 상태가 더 이상 변하지 않고 수렴했다고 판단되면 즉시 추론을 멈춥니다. 이는 실시간 제어가 중요한 로봇 환경에서 매우 효율적인 자원 배분을 가능하게 합니다.
4. 구현 및 실험 환경 (Implementation Details)
연구팀은 RD-VLA를 검증하기 위해 OpenVLA를 백본으로 사용하고, LIBERO 벤치마크 및 다양한 조작 작업(Manipulation tasks)에서 실험을 진행했습니다.
- 데이터셋: 로봇 조작 데이터인 LIBERO-100 및 실제 환경의 데이터.
- 비교군: 고정된 깊이의 VLA, CoT 기반 VLA, 그리고 일반적인 트랜스포머 기반 에이전트.
- 하드웨어: 로봇의 실시간성을 테스트하기 위해 NVIDIA Jetson과 같은 엣지 디바이스 환경을 고려한 벤치마킹 수행.
특히 주목할 점은 ‘Test-time Compute Scaling’ 현상입니다. 연구진은 추론 시 반복 횟수(K)를 늘림에 따라 모델의 성공률이 어떻게 변화하는지 측정했습니다. 이는 LLM에서 ‘생각할 시간을 더 주면 똑똑해진다’는 정설이 로봇의 액션 도메인에서도 유효함을 증명하는 핵심 실험입니다.
5. 성능 평가 및 비교 (Comparative Analysis)
결과는 압도적이었습니다.
- 동적 성능 향상: 단일 반복(K=1)에서는 성공률이 0%에 가깝던 복잡한 작업들이 반복 횟수를 4회(K=4)로 늘리자 성공률 90%를 상회했습니다. 이는 모델이 물리적인 레이어 추가 없이 오직 ‘시간’을 더 투자함으로써 난제를 해결할 수 있음을 의미합니다.
- 효율성 (Speed vs. Memory): 기존의 토큰 기반 CoT 모델이 추론 단계에서 선형적인 메모리 증가를 보인 것과 달리, RD-VLA는 상수 메모리(Constant Memory)를 유지했습니다. 또한, 텍스트 생성을 기다릴 필요가 없어 기존 CoT-VLA 대비 최대 80배 빠른 속도를 기록했습니다.
- 적응적 추론: 쉬운 작업에서는 평균 1.2회의 반복만으로 작업을 완수하여 에너지를 절약한 반면, 어려운 작업에서는 평균 3.5회 이상의 반복을 수행하며 신중함을 보였습니다.
시니어 사이언티스트로서 평가하자면, 이는 “연산 효율성과 인지적 깊이 사이의 Pareto Frontier를 새로 썼다”고 볼 수 있습니다.
6. 실제 적용 분야 및 글로벌 파급력 (Real-World Application)
RD-VLA는 실험실 수준을 넘어 실제 산업 현장에 즉각적인 임팩트를 줄 수 있습니다.
- 정밀 제조 및 조립: 부품을 끼워 맞추는 작업처럼 미세한 조정이 반복적으로 필요한 공정에서 RD-VLA는 잠재적 정제를 통해 오차를 줄일 수 있습니다.
- 물류 및 분류: 컨베이어 벨트 위의 물건이 겹쳐 있거나 복잡한 상황일 때만 ‘더 깊이 생각’하고, 평시에는 빠르게 움직이는 가변 속도 제어가 가능해집니다.
- 가정용 서비스 로봇: 냉장고에서 깨지기 쉬운 달걀을 꺼낼 때와 플라스틱 물통을 꺼낼 때의 사고 수준을 조절하여 배터리 수명을 연장하고 안전성을 높일 수 있습니다.
- 의료 로봇: 수술 보조 로봇이 인체 조직의 미세한 변화에 따라 실시간으로 동작을 보정(Refinement)하는 시나리오에 최적입니다.
7. 기술적 비평 및 한계점 (Discussion: Critical Critique)
하지만 이 모델이 완벽한 것은 아닙니다. 다음과 같은 비판적 시각이 필요합니다.
- TBPTT의 학습 불안정성: 순환 구조는 본질적으로 그라디언트 소실(Vanishing)이나 폭주(Exploding) 문제에 취약합니다. 가중치를 공유하는 구조에서 복잡한 조작의 모든 케이스를 커버할 수 있을 만큼 가중치가 풍부한(Expressive)지는 여전히 의문입니다.
- 적응적 정지의 신뢰성: 모델이 스스로 ‘충분히 생각했다’고 판단하는 기준이 잘못될 경우, 위험한 환경에서 로봇이 성급하게 행동할 위험이 있습니다. 이 stopping criterion에 대한 안전성 보증(Safety guarantee) 메커니즘이 보완되어야 합니다.
- Backbone VLM 의존성: 결국 RD-VLA의 성능 상한선은 기반이 되는 VLM(OpenVLA 등)의 시각적 이해력에 갇혀 있습니다. 시각적 특징 자체가 부정확하다면 아무리 반복 추론을 해도 결과는 개선되지 않는 ‘Garbage In, Garbage Out’의 위험이 있습니다.
8. 결론 및 인사이트 (Conclusion)
RD-VLA는 로봇 AI 모델이 나아가야 할 새로운 방향을 제시했습니다. 지금까지의 VLA 연구가 ‘더 큰 모델, 더 많은 데이터’에 집중했다면, RD-VLA는 ‘연산 자원을 어떻게 지능적으로 배분할 것인가’에 집중했습니다.
잠재 공간에서의 반복적 정제는 메모리 효율과 추론 속도라는 로봇 공학의 두 마리 토끼를 잡았으며, 특히 ‘테스트 시간 계산량 확장’을 실현함으로써 로봇이 상황에 따라 ‘심사숙고’할 수 있는 길을 열었습니다. 이는 향후 테슬라의 옵티머스나 피규어(Figure) 같은 휴머노이드 로봇들이 실제 환경의 복잡성을 극복하는 데 핵심적인 소프트웨어 아키텍처가 될 것입니다.
이제 로봇은 단순히 명령을 수행하는 기계를 넘어, 상황의 난이도를 스스로 파악하고 그에 맞는 지능적 깊이를 조절하는 ‘사고하는 주체’로 진화하고 있습니다.
