[2026-01-28] [심층 분석] 비디오 생성은 어떻게 인공지능의 시각적 추론 능력을 깨우는가?: Thinking in Frames 논문 분석

비디오 생성이 지능의 척도가 될 수 있는가?: ‘Thinking in Frames’에 대한 기술적 심층 분석
1. Executive Summary (핵심 요약)
전통적인 시각-언어 모델(Vision-Language Models, VLMs)은 텍스트 기반의 추론 능력에서는 괄목할 만한 성과를 거두었으나, 미세한 공간적 이해(Fine-grained spatial understanding)와 연속적인 행동 계획(Continuous action planning) 측면에서는 여전히 한계를 보이고 있습니다. 본 포스트에서 다룰 논문 “Thinking in Frames: How Visual Context and Test-Time Scaling Empower Video Reasoning”은 비디오 생성 모델을 단순한 미디어 생성 도구가 아닌, 복잡한 시각적 추론 문제를 해결하기 위한 ‘월드 모델(World Model)’이자 ‘추론 엔진’으로 재정의합니다.
연구팀은 비디오의 각 프레임이 초기 상태와 최종 해답 사이의 ‘중간 추론 단계(Intermediate Reasoning Steps)’ 역할을 한다고 가정합니다. 미로 찾기(Maze Navigation)와 탱그램 퍼즐(Tangram Puzzle)이라는 두 가지 상반된 환경(이산적 논리 vs 연속적 조작)을 통해 실험한 결과, 모델은 별도의 미세 조정 없이도 강력한 제로샷 일반화 능력을 보여주었으며, 특히 ‘시각적 테스트 시간 스케일링(Visual Test-Time Scaling)’ 법칙을 발견했습니다. 이는 생성되는 비디오의 프레임 수(즉, 추론 예산)를 늘릴수록 더 복잡한 공간적·시간적 문제를 해결할 수 있음을 의미합니다.
2. Introduction & Problem Statement (연구 배경 및 문제 정의)
최근 GPT-4o, Gemini 1.5 Pro와 같은 모델들은 다중 모달리티를 통합하며 놀라운 성능을 보여주고 있습니다. 하지만 이러한 모델들은 정적인 이미지 기반 학습에 치중되어 있어, 시간에 따른 변화나 물리적 법칙이 작용하는 시각적 시뮬레이션에서는 ‘환각(Hallucination)’ 현상을 빈번히 겪습니다. 예를 들어, 로봇 팔이 물체를 옮기는 과정을 설명하라고 하면 텍스트로는 유창하게 답변하지만, 그 과정을 픽셀 단위로 정확하게 예측하거나 실행 계획을 수립하는 데에는 어려움을 겪습니다.
이러한 한계의 근본 원인은 ‘시각적 사고의 부재’에 있습니다. LLM이 ‘Chain of Thought(CoT)’를 통해 텍스트로 사고 과정을 풀어내듯, 시각적 지능 역시 결과물에 도달하기까지의 중간 과정을 시각적으로 그려낼 수 있어야 합니다.
본 연구는 바로 이 지점에서 출발합니다. “비디오 생성 모델이 미래의 프레임을 예측하는 과정 자체가 곧 시각적 추론의 과정이 될 수 있지 않을까?”라는 질문을 던집니다. 이는 OpenAI의 Sora가 지향하는 ‘World Simulator’ 개념과 맞닿아 있으며, 이를 더 구체적인 추론 과업(Reasoning Tasks)으로 검증했다는 점에서 기술적 가치가 매우 높습니다.
3. Core Methodology (핵심 기술 및 아키텍처 심층 분석)
3.1. 비디오 생성을 통한 시각적 추론의 정형화
본 논문은 시각적 추론 문제를 시퀀스 생성 문제로 치환합니다.
- 입력(Initial State): 문제의 시작 상태를 나타내는 정지 영상 혹은 짧은 컨텍스트.
- 중간 단계(Reasoning Frames): 목표를 달성하기 위해 거쳐야 하는 중간 프레임들.
- 결과(Solution): 최종적으로 문제가 해결된 상태의 프레임.
이 과정에서 핵심은 Visual Context입니다. 모델은 입력값으로 주어지는 에이전트의 아이콘(예: 미로 속의 쥐)이나 목표 형상(예: 탱그램 퍼즐의 타겟 모양)을 명시적인 제어 신호로 활용합니다.
3.2. 실험 설계: Maze Navigation vs Tangram Puzzle
연구팀은 두 가지 극단적인 케이스를 설정하여 모델을 테스트했습니다.
- Maze Navigation (이산적 계획): 시각적 변화는 적지만, 논리적인 경로 탐색이 중요한 과업입니다.
- Tangram Puzzle (연속적 조작): 공간적 회전, 평행 이동 등 높은 수준의 시각적 변화와 정밀한 배치가 요구되는 과업입니다.
 Figure 5: 탱그램 퍼즐을 해결하기 위한 다양한 시스템 변형들의 예시. 각 모델이 어떻게 시각적 정보를 처리하는지 보여줍니다.
Figure 5: 탱그램 퍼즐을 해결하기 위한 다양한 시스템 변형들의 예시. 각 모델이 어떻게 시각적 정보를 처리하는지 보여줍니다.
위 그림에서 볼 수 있듯이, 탱그램 퍼즐은 단순한 이미지 편집(Image Editing) 모델이나 기존의 VLM(Qwen-2-VL 등)과 비교됩니다. 비디오 생성 모델은 이 과정을 연속적인 움직임으로 표현함으로써 단순한 결과 예측 이상의 성능을 보여줍니다.
4. Implementation Details & Experiment Setup (구현 및 실험 환경)
4.1. 모델 아키텍처
연구팀은 사전 학습된 비디오 생성 모델(예: Stable Video Diffusion 기반 또는 그와 유사한 확산 모델 아키텍처)을 베이스라인으로 활용한 것으로 보입니다. 여기서 주목할 점은 모델을 특정 태스크에 맞춰 파인튜닝(Finetuning)하는 대신, 제로샷(Zero-shot) 혹은 최소한의 컨텍스트 제공을 통한 성능을 측정했다는 것입니다.
4.2. Visual OOD (Out-of-Distribution) 평가
지능의 진정한 척도는 ‘학습하지 않은 데이터’에 대한 대응 능력입니다. 연구팀은 학습 시 보지 못했던 새로운 형태의 에이전트 아이콘을 미로에 배치하여 모델의 일반화 능력을 검증했습니다.
 Figure 4: 미로 찾기 학습 및 평가에 사용된 다양한 에이전트 아이콘들. 학습된 적 없는 아이콘에 대해서도 모델은 ‘이것이 움직이는 주체’임을 인식해야 합니다.
Figure 4: 미로 찾기 학습 및 평가에 사용된 다양한 에이전트 아이콘들. 학습된 적 없는 아이콘에 대해서도 모델은 ‘이것이 움직이는 주체’임을 인식해야 합니다.
5. Comparative Analysis (성능 평가 및 비교)
5.1. 기존 VLM과의 차별성
기존의 VLM(예: Qwen-2-VL)은 좌표값(Coordinates)을 텍스트로 출력하는 방식을 사용합니다. 하지만 논문에 따르면, 픽셀 단위의 생성을 수행하는 비디오 모델이 공간적 일관성을 유지하는 데 훨씬 뛰어난 능력을 보였습니다.
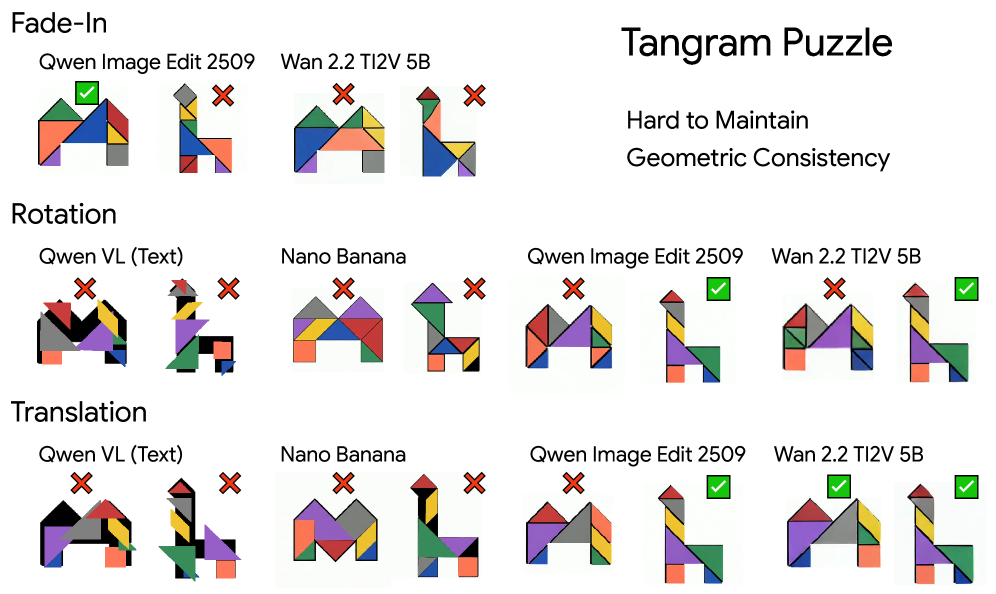 Figure 2: 탱그램 퍼즐 해결 결과 비교. 비디오 생성 모델이 좌표 기반의 VLM이나 단순 이미지 편집 모델보다 월등히 정확한 배치를 수행함을 알 수 있습니다.
Figure 2: 탱그램 퍼즐 해결 결과 비교. 비디오 생성 모델이 좌표 기반의 VLM이나 단순 이미지 편집 모델보다 월등히 정확한 배치를 수행함을 알 수 있습니다.
5.2. Visual Test-Time Scaling의 발견
본 논문의 가장 혁신적인 발견 중 하나는 시각적 테스트 시간 스케일링(Visual Test-Time Scaling)입니다. 이는 LLM에서 추론 시 ‘생각할 시간’을 더 주면(Chain of Thought의 길이를 늘리면) 정답률이 올라가는 현상과 매우 흡사합니다.
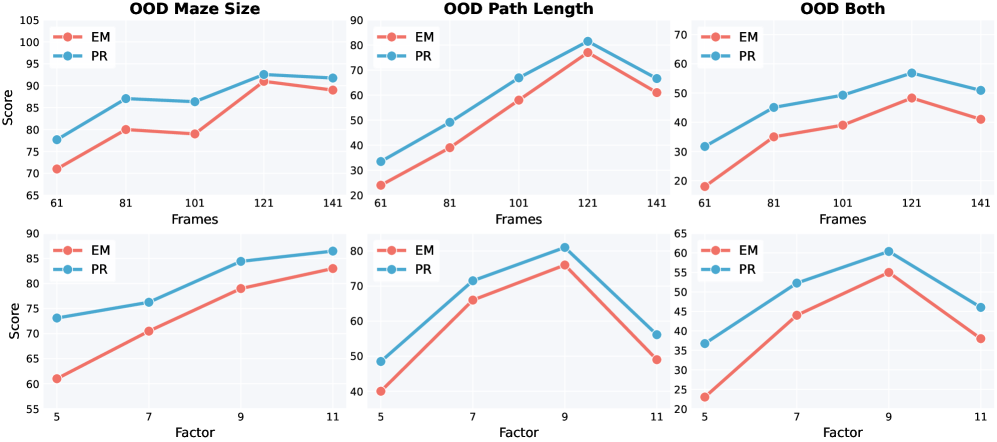 Figure 3: 추론 예산(프레임 수) 증가에 따른 성능 향상 곡선. 더 많은 프레임을 생성할수록 복잡한 미로에서도 성공률이 비약적으로 상승합니다.
Figure 3: 추론 예산(프레임 수) 증가에 따른 성능 향상 곡선. 더 많은 프레임을 생성할수록 복잡한 미로에서도 성공률이 비약적으로 상승합니다.
연구팀은 비디오의 총 프레임 수를 늘리거나(Inference Budget), 각 단계별 할당되는 프레임 밀도(Scaling factor κ)를 조절함으로써 복잡한 문제 해결 능력이 선형적으로 혹은 지수적으로 향상되는 것을 관찰했습니다.
6. Real-World Application & Impact (실제 적용 분야 및 글로벌 파급력)
이 연구가 시사하는 바는 단순히 퍼즐을 잘 푸는 인공지능에 그치지 않습니다.
- 로보틱스 및 자율 주행: 물리적 환경에서 로봇이 자신의 행동 결과를 미리 ‘상상(Visual Imagination)’해보고 최적의 경로를 선택할 수 있게 합니다. 이는 시각적 시뮬레이터로서의 비디오 모델의 가치를 증명합니다.
- 디지털 트윈 및 공정 최적화: 복잡한 기계 조립 과정이나 물류 흐름을 비디오 생성 모델로 시뮬레이션하여 병목 구간을 예측하고 최적의 동선을 설계할 수 있습니다.
- 인터랙티브 AI 에이전트: 사용자의 지시에 따라 UI 상에서의 변화를 미리 시뮬레이션하여 보여줌으로써 사용자 경험(UX)을 극대화할 수 있습니다.
비즈니스적 관점에서, 이는 ‘추론 비용의 자산화’를 의미합니다. 기업은 더 강력한 하드웨어를 통해 추론 시간을 늘림으로써(Scaling up test-time), 추가적인 모델 학습 없이도 고난도의 문제 해결 능력을 확보할 수 있게 됩니다.
7. Discussion: Limitations & Critical Critique (한계점 및 기술적 비평)
시니어 AI 사이언티스트로서 냉철하게 분석했을 때, 본 연구에는 몇 가지 짚고 넘어가야 할 한계점이 존재합니다.
- 계산 효율성의 문제: 비디오 생성은 텍스트 생성에 비해 수천 배 이상의 계산 자원을 소모합니다. 단순한 미로 찾기를 위해 64프레임의 고해상도 영상을 생성하는 것이 과연 실용적인가에 대한 비판적 시각이 필요합니다.
- 일관성 유지의 한계 (Temporal Inconsistency): 현재의 비디오 모델들은 프레임이 길어질수록 초기 설정이 무너지거나 물체가 갑자기 사라지는 ‘Temporal Drift’ 현상을 겪습니다. 복잡한 3D 환경에서도 이 ‘Thinking in Frames’가 유효할지는 의문입니다.
- 물리 법칙의 내재화 부족: 모델이 시각적 패턴을 복사하는 것인지, 아니면 정말로 물리적 중력과 충돌을 이해하고 있는지는 아직 명확하지 않습니다. 탱그램 퍼즐의 경우 기하학적 매칭에 가깝지만, 유체 역학이나 복잡한 물리 엔진이 필요한 과업에서는 한계가 명확할 것입니다.
8. Conclusion (결론 및 인사이트)
“Thinking in Frames”는 비디오 생성 기술을 단순한 콘텐츠 제작의 영역에서 추론의 영역으로 끌어올린 매우 중요한 연구입니다.
이 논문은 우리에게 두 가지 중요한 교훈을 줍니다. 첫째, 시각적 지능은 정적인 이미지의 나열이 아닌, 연속적인 변화의 예측에서 비롯된다는 것입니다. 둘째, LLM의 시대가 그러했듯, 비디오 지능 역시 테스트 시간의 연산량(Test-time Compute)이 성능의 핵심 지표가 될 것이라는 점입니다.
이제 인공지능은 텍스트로 논리를 전개하는 단계를 넘어, 픽셀의 변화로 세상을 시뮬레이션하며 사고하기 시작했습니다. 우리는 머지않아 로봇이 행동하기 전, 수백 개의 가상 미래 비디오를 생성해보고 가장 안전한 길을 선택하는 광경을 목격하게 될 것입니다. 이것이 바로 ‘시각적 추론’이 그리는 미래입니다.
본 분석은 최신 AI 기술 동향을 기반으로 Senior Chief AI Scientist의 시각에서 작성되었습니다.
