[2026-03-19] 3DreamBooth: 2D 환각에 빠진 비디오 생성 모델을 구원할 진짜 3D 커스텀 방법론 (1프레임 최적화의 비밀)

[Metadata]
- Project Page: 3DreamBooth
- ArXiv ID: 2603.18524
- Tags: #VideoGeneration #3D #Diffusion #Dreambooth
비디오 생성 모델로 특정 피사체를 커스텀해 본 개발자라면 다들 치가 떨리는 지점이 하나 있을 겁니다. 정면 샷은 기가 막히게 뽑히는데, 카메라가 조금만 돌아가면 모델이 피사체의 뒷면을 멋대로 상상해서 크리피한 괴물을 만들어버리죠. 기존 2D 기반 커스텀 방법론들이 피사체를 그저 ‘납작한 픽셀 뭉치’로 취급하기 때문입니다.
이걸 해결하겠다고 다중 시점 비디오(Multi-view Video)를 수집해서 파인튜닝을 돌린다고요? 바로 끔찍한 시간적 과적합(Temporal Overfitting)의 늪에 빠지게 됩니다. 비디오가 움직이질 않고 뻣뻣하게 굳어버리거든요. 이 골치 아픈 딜레마를 3DreamBooth가 굉장히 엔지니어링 친화적인 방식으로 뚫어냈습니다.
TL;DR: 3DreamBooth는 ‘1프레임 최적화’로 공간(Geometry)과 시간(Motion)을 완벽히 분리해 3D 일관성을 강제하는 프레임워크입니다. 여기에 3Dapter라는 동적 라우팅 어텐션을 붙여 텍스처 뭉개짐을 막고 수렴 속도를 미친 듯이 끌어올렸죠.

- [그림 설명] 소수의 다중 시점 레퍼런스 이미지만으로 완벽하게 3D 일관성이 유지되는 비디오를 뽑아낸 결과물입니다. 카메라가 돌아가도 피사체의 뒷면이 무너지지 않죠.
⚙️ 1프레임으로 3D 공간을 연성해내는 기괴한 파이프라인 해부
솔직히 처음 페이퍼를 읽었을 때, “어떻게 비디오 모델에 3D 개념을 주입하면서 모션이 안 망가지게 할까?”가 제일 궁금했습니다. 3DreamBooth의 대답은 허탈할 정도로 명쾌합니다. “비디오로 학습하지 마라. 1프레임으로 공간만 깎아라.”
이들은 공간 기하학(Spatial geometry)과 시간적 움직임(Temporal motion)을 분리(Decouple)했습니다. 비디오 전체를 학습시키는 대신, 특정 1프레임의 공간적 표현만 업데이트하는 방식으로 모델에 3D 사전 지식(Prior)을 구워버린 거죠.
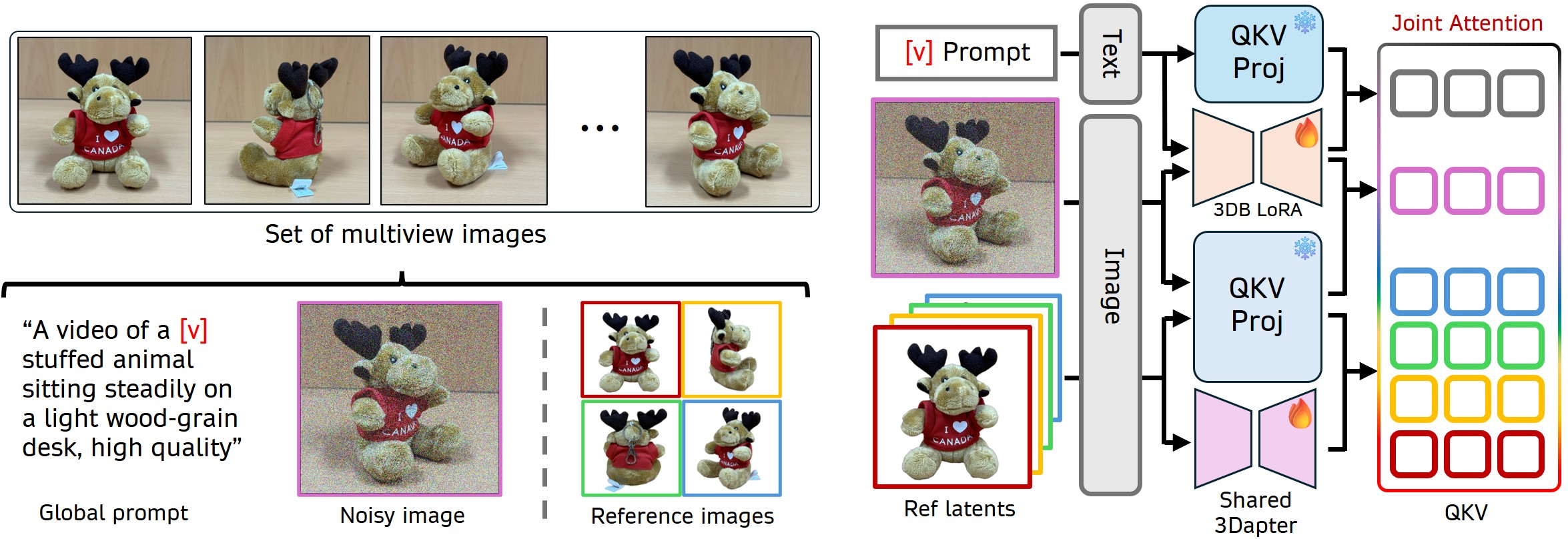
- [그림 설명] 핵심 파이프라인입니다. 텍스트와 노이즈가 메인 브랜치(3DB LoRA)를 타는 동안, 레퍼런스 이미지들은 공유되는 3Dapter를 통과해 조인트 어텐션으로 병합됩니다.
여기에 3Dapter(Visual Conditioning Module)가 등장합니다. 단순히 레퍼런스 이미지를 냅다 때려 넣는 게 아니라, 아주 영리한 비대칭 조건부 전략(Asymmetrical conditioning strategy)을 씁니다.
🔹 Single-view Pre-training: 먼저 단일 뷰 레퍼런스로 3Dapter를 사전 학습시킵니다. 🔹 Multi-view Joint Optimization: 그 다음, 메인 브랜치에 학습 가능한 3DB LoRA를 붙이고, 3Dapter와 함께 다중 뷰 레퍼런스를 병렬로 처리합니다.
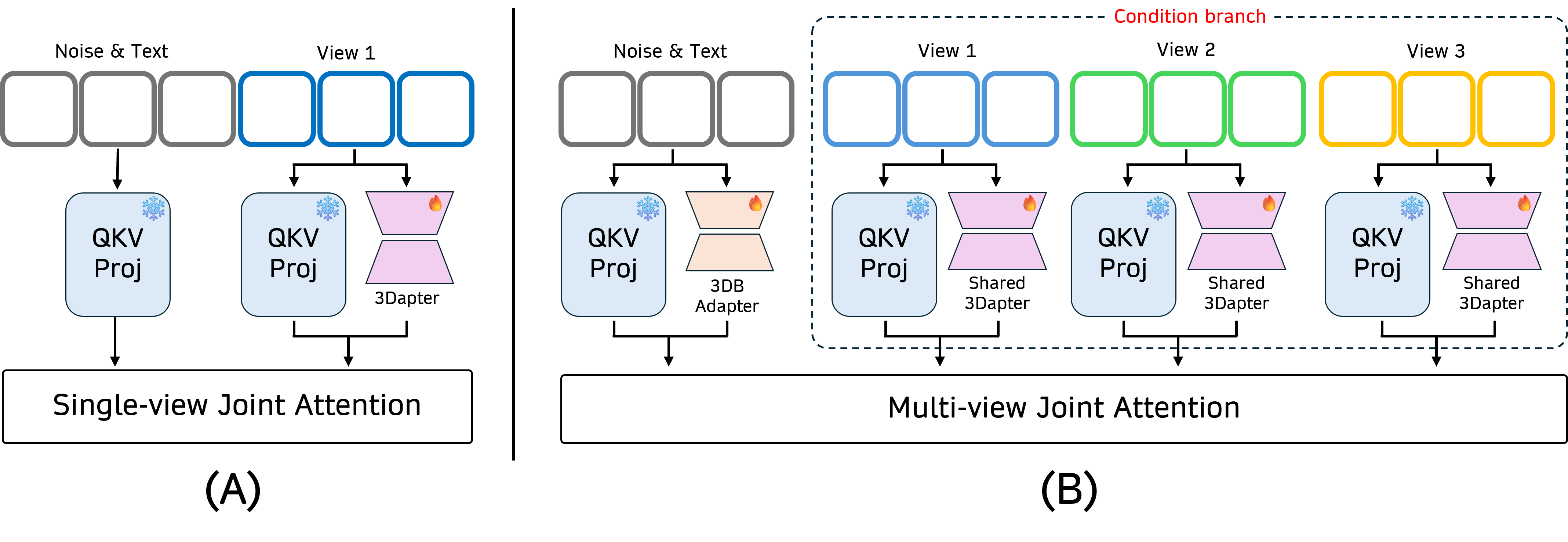
- [그림 설명] 2단계 조건부 메커니즘의 아키텍처. 3Dapter가 다중 시점의 레퍼런스를 처리한 뒤, 타겟 뷰를 재구성할 때 필요한 기하학적 힌트만 쏙쏙 뽑아주는 ‘동적 선택 라우터’ 역할을 합니다.
말이 좀 복잡하죠? 개발자답게 코드로 이 다중 뷰 조인트 어텐션(Multi-view Joint Attention)의 데이터 플로우를 까봅시다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# [Mock Code] 3Dapter Multi-View Joint Attention Routing
def multi_view_joint_attention(target_latent, ref_latents, text_prompt):
# target_latent: [B, C, H, W] (Current noisy frame)
# ref_latents: [B, N, C, H, W] (N = Number of multi-view reference images)
# 1. 메인 브랜치에서 타겟의 쿼리(Q) 추출
Q_target = main_branch_q_proj(target_latent)
# 2. 3Dapter에서 레퍼런스들의 키(K), 밸류(V) 추출 (Shared weights)
K_refs, V_refs = [], []
for i in range(num_views):
k, v = adapter_kv_proj(ref_latents[:, i, ...])
K_refs.append(k)
V_refs.append(v)
# 3. K, V 병합 (Concat along sequence/view dimension)
K_fused = torch.cat(K_refs, dim=1)
V_fused = torch.cat(V_refs, dim=1)
# 4. 동적 선택적 라우팅 (Dynamic Selective Routing)
# 여기서 어텐션 스코어가 타겟 뷰와 가장 유사한 레퍼런스 뷰에 가중치를 몰아줍니다.
attention_scores = softmax(Q_target @ K_fused.transpose(-2, -1) / sqrt(d))
# 5. 최종 3D 힌트 주입
spatial_hints = attention_scores @ V_fused
return target_latent + spatial_hints
이 구조가 왜 미쳤냐면, 네트워크가 N개의 레퍼런스를 그냥 뭉뚱그려 평균 내는 게 아닙니다. 타겟 프레임을 그릴 때 “어? 지금 측면을 그리고 있네? 그럼 2번(측면) 레퍼런스에서 텍스처를 더 많이 가져와야겠다”라고 스스로 가중치를 조절하는 동적 라우터(Dynamic Selective Router) 역할을 수행한다는 겁니다.
⚔️ 기존 2D-centric 모델 vs 3DreamBooth: 진짜 갈아탈 가치가 있나?
이쯤에서 의문이 듭니다. “그냥 기존 비디오 드림부스(Video-Dreambooth)에 LoRA 떡칠하면 안 되나요?” 네, 안 됩니다. 테이블로 명확히 비교해 드리죠.
| 비교 지표 | Standard Video-Dreambooth | 3DreamBooth (w/ 3Dapter) |
|---|---|---|
| 학습 데이터 요구량 | 긴 길이의 고화질 비디오 필수 | 소수의 정적 다중 시점 이미지 (3~4장) |
| 학습 방식 | Temporal & Spatial 동시 업데이트 | 1-Frame Spatial 최적화 (Temporal 고정) |
| 3D 일관성 (Novel View) | 카메라 패닝 시 텍스처 환각(Hallucination) 발생 | 타겟 뷰에 맞춰 레퍼런스에서 기하학적 특징 추출 (완벽 유지) |
| 텍스처 수렴 속도 | 매우 느림 (Detail Loss 심함) | 매우 빠름 (3Dapter의 시각적 힌트 덕분) |
| VRAM 사용량 (학습 시) | VRAM 터짐 (다수 프레임 로드) | 상대적으로 낮음 (1프레임 타겟 + N개 레퍼런스) |
이게 인프라 비용 관점에서 엄청난 차이를 만듭니다. 기존 방식은 수십 프레임의 비디오를 메모리에 올려두고 그래디언트를 계산해야 하니 A100 80GB가 아니면 학습조차 버겁습니다. 반면 3DreamBooth는 1프레임 타겟 학습이라 VRAM 요구량이 확연히 줄어듭니다.
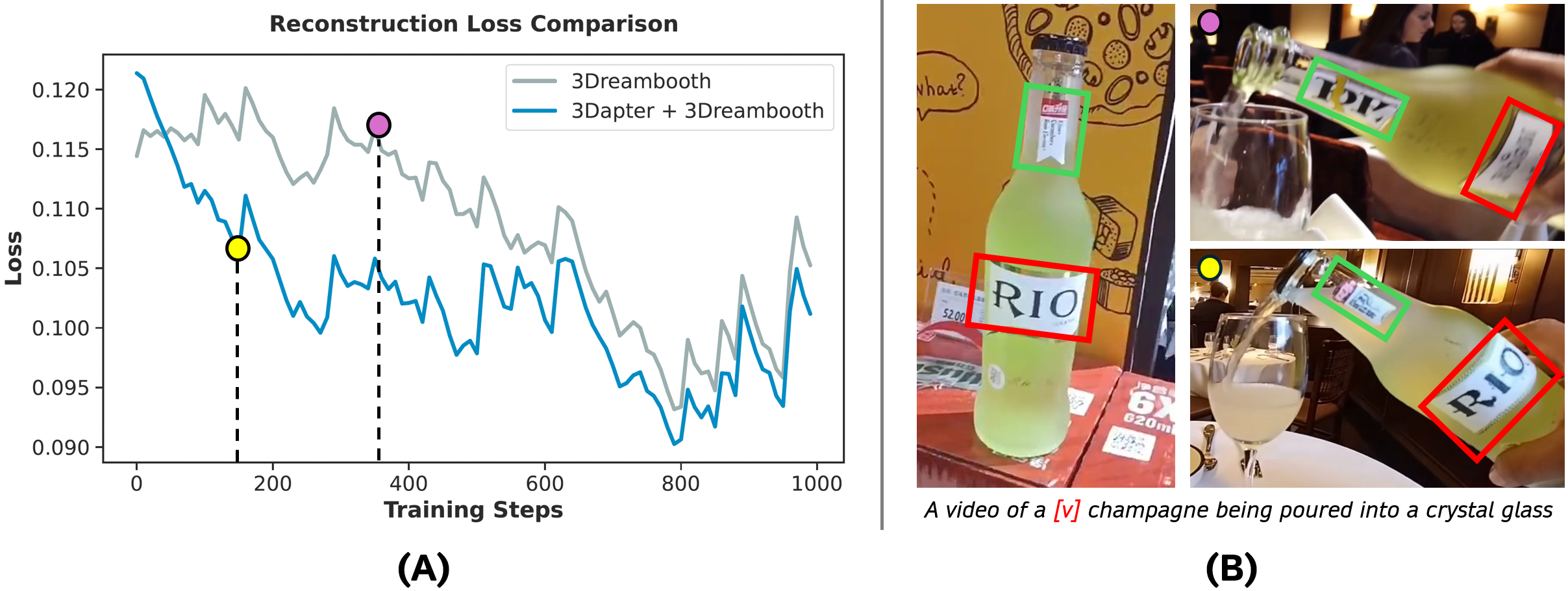
- [그림 설명] 재구성 손실(Reconstruction Loss) 그래프를 보세요. 3Dapter를 붙인 파란 선이 압도적인 속도로 바닥을 찍습니다. 오른쪽 결과물을 보면 글씨 같은 미세 텍스처도 훨씬 일찍, 완벽하게 보존하죠.
🚀 내일 당장 프로덕션에 도입한다면?
이론은 훌륭합니다. 그럼 실제 프로덕션 환경에선 어떨까요? 두 가지 시나리오를 살펴봅시다.
1. 차세대 이커머스 (3D Product Showcase) 가장 즉각적으로 돈이 되는 유스케이스입니다. 신발이나 가방의 전/후/좌/우 사진 4장만 있으면, 이 제품이 폭발하는 화산재를 뚫고 날아오거나 물보라를 일으키며 회전하는 3D 다이내믹 광고 영상을 뽑아낼 수 있습니다. 텍스처(로고, 재질)가 뭉개지지 않으니 브랜드 마케팅 팀이 환호할 수밖에 없죠.
2. 몰입형 VR/AR 및 버추얼 프로덕션 하지만 여기서 병목(Bottleneck)을 하나 예상해 볼 수 있습니다. 3Dapter가 다중 시점을 동적으로 참조하다 보니, 만약 프롬프트로 요구한 모션이 너무 과격해서(예: 피사체가 360도로 미친 듯이 회전하며 변형됨) 주어진 레퍼런스 시점들의 커버리지를 완전히 벗어난다면? 동적 라우터가 참조할 뷰를 잃고 어텐션 가중치가 붕괴될 위험이 있습니다.

- [그림 설명] 디퓨전 타임스텝에 따른 크로스 어텐션 히트맵. 모델이 타겟 프레임의 포즈와 일치하는 ‘View 2’에만 강하게 가중치를 주고 있는 것을 볼 수 있습니다. 이것이 3Dapter가 단순한 합성이 아닌 ‘동적 라우터’로 불리는 이유입니다.
🧐 Tech Lead’s Honest Verdict
👍 Pros (이건 진짜 물건이다)
- 1프레임 최적화의 우아함: 비디오를 쑤셔 넣지 않고도 공간과 시간을 분리해 3D Prior를 굽는 아이디어는 예술에 가깝습니다. 덕분에 Temporal Overfitting에서 완벽히 해방됐죠.
- 미친 수렴 속도와 디테일: 3Dapter가 명시적인 기하학적 힌트를 쏴주기 때문에, 복잡한 텍스처나 글씨가 뭉개지는 현상(Information bottleneck)을 초기에 잡아냅니다.
👎 Cons (환상은 여기까지)
- 입력 데이터의 한계: 아무리 1프레임 최적화라 해도, 결국 ‘깔끔하게 분리된 다중 시점 레퍼런스 이미지’가 최소 3~4장은 필수적입니다. 인터넷에서 대충 주운 사진 1장으로는 이 퍼포먼스를 낼 수 없습니다.
- VRAM 트레이드오프: 학습 시 타겟 프레임은 1장이지만, 3Dapter가 N개의 레퍼런스를 매 스텝 메모리에 들고 있어야 합니다. 레퍼런스 개수(N)를 늘릴수록 VRAM 요구량은 선형적으로 증가하겠죠.
총평: Clone immediately for internal toy projects. 현재 2D 비디오 생성 모델들이 가진 3D 한계를 가장 공학적으로 영리하게 풀어낸 수작입니다. 당장 사내 이커머스나 제품 렌더링 팀의 토이 프로젝트로 클론해볼 가치가 충분합니다. 다만, 인더 더 와일드(In-the-wild)의 단일 이미지나 모션이 극도로 튀는 환경에서는 아직 검증이 필요해 보입니다. V2를 기대해 봅니다.
