[2026-01-26] [심층 분석] 실용적 로봇 AI의 정점: LingBot-VLA가 제시하는 차세대 파운데이션 모델의 규격

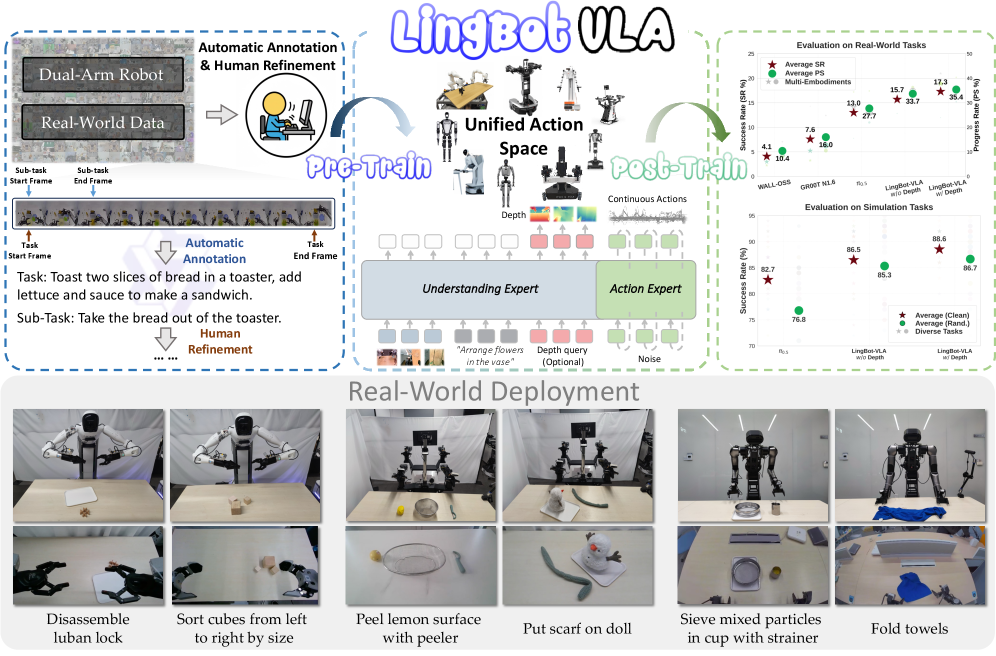 Figure 1:OverviewofLingBot-VLA. We scale dual-arm robot data collected in the real world for pre-training.LingBot-VLAcan be easily and efficiently transferred to downstream tasks. Moreover, we conduct a systematic assessment across three robotic embodiments, which demonstrates the clear superiority of our model.
Figure 1:OverviewofLingBot-VLA. We scale dual-arm robot data collected in the real world for pre-training.LingBot-VLAcan be easily and efficiently transferred to downstream tasks. Moreover, we conduct a systematic assessment across three robotic embodiments, which demonstrates the clear superiority of our model.
 Figure 2:Visualization of pre-training datasetused byLingBot-VLA.
Figure 2:Visualization of pre-training datasetused byLingBot-VLA.
 (a)
(a)
[심층 분석] 실용적 로봇 AI의 정점: LingBot-VLA가 제시하는 차세대 파운데이션 모델의 규격
1. 핵심 요약 (Executive Summary)
로봇 공학의 ‘GPT 모먼트’를 앞당기기 위한 시도는 계속되고 있지만, 현실 세계의 복잡성과 하드웨어의 다양성은 여전히 높은 장벽입니다. 최근 공개된 LingBot-VLA는 단순한 성능 향상을 넘어, ‘실용주의(Pragmatism)’를 전면에 내세운 Vision-Language-Action(VLA) 파운데이션 모델의 정수를 보여줍니다.
이 모델은 9가지 이상의 다양한 듀얼 암(Dual-arm) 로봇 구성에서 추출된 20,000시간 이상의 실제 주행 데이터를 기반으로 학습되었습니다. 기존 VLA 모델들이 특정 하드웨어나 제한된 환경에 의존했던 것과 달리, LingBot-VLA는 3가지 다른 로봇 플랫폼에서 진행된 100개의 고난도 태스크 수행 시험에서 압도적인 범용성을 입증했습니다. 특히 주목할 점은 기존 대비 1.5~2.8배 빠른 초당 261개 샘플 처리량(Throughput)을 달성한 고효율 코드베이스입니다. 본 보고서에서는 LingBot-VLA가 어떻게 데이터 효율성과 추론 성능이라는 두 마리 토끼를 잡았는지, 그리고 이것이 실제 산업 현장에 어떤 파급력을 미칠지 심층적으로 분석합니다.
2. 연구 배경 및 문제 정의 (Introduction & Problem Statement)
로봇 AI의 난제: 범용성과 실용성의 충돌
지난 몇 년간 대형 언어 모델(LLM)과 시각-언어 모델(VLM)의 성공은 로봇 제어 분야에도 큰 영감을 주었습니다. 하지만 텍스트나 이미지와 달리, 로봇의 ‘행동(Action)’은 물리적 제약 조건과 실시간성이 필수적입니다. 기존의 연구들은 크게 두 가지 난관에 부딪혀 왔습니다.
- 데이터의 희소성 및 편향성: 시뮬레이션 데이터는 현실과의 간극(Sim-to-Real Gap)이 크고, 실제 데이터는 수집 비용이 천문학적입니다. 또한 특정 로봇 팔(Arm)에 최적화된 데이터는 다른 기종으로의 전이가 극도로 어렵습니다.
- 비효율적인 아키텍처: RT-2와 같은 초기 VLA 모델들은 강력하지만, 추론 속도가 느리고 학습에 막대한 컴퓨팅 자원이 소요됩니다. 실제 로봇이 엣지 환경에서 실시간으로 반응하기에는 구조적 비대함이 걸림돌이 되었습니다.
LingBot-VLA 연구팀은 이러한 문제를 ‘실용적 접근(Pragmatic Approach)’으로 풀고자 했습니다. 단순히 파라미터 수를 늘리는 것이 아니라, 데이터의 다양성을 확보하고 엔진 자체의 효율을 극대화하여 실제 배포 가능한 형태의 파운데이션 모델을 정의하는 것이 본 연구의 핵심 목적입니다.
3. 핵심 기술 및 아키텍처 심층 분석 (Core Methodology)
3.1 듀얼 암 데이터의 힘: 20,000시간의 다양성
LingBot-VLA의 가장 강력한 자산은 데이터셋의 질과 양입니다. 연구팀은 9개의 대중적인 듀얼 암 로봇 구성을 활용했습니다. 이는 단순히 ‘두 팔을 쓴다’는 의미를 넘어, 각기 다른 관절 자유도(DoF), 페이로드, 제어 주기를 가진 하드웨어들로부터 범용적인 물리 지능을 추출했다는 것을 의미합니다.
이러한 Cross-Platform 학습 방식은 모델이 특정 모터의 출력값에 종속되지 않고, 시각적 정보로부터 환경의 기하학적 구조와 태스크의 논리적 순서를 추상화하도록 유도합니다. Senior Scientist의 관점에서 볼 때, 이는 로봇 공학의 ‘Zero-shot Generalization’을 향한 가장 현실적인 경로입니다.
3.2 아키텍처: VLM의 행동 토큰화(Action Tokenization)
LingBot-VLA는 기본적으로 강력한 VLM(Vision-Language Model) 아키텍처를 기반으로 합니다. 시각적 입력과 텍스트 명령어를 통합 임베딩 공간으로 투영한 뒤, 이를 ‘행동 토큰’으로 변환합니다.
- 토큰화 전략: 행동 값을 이산화(Discretization)하여 언어 모델의 어휘집(Vocabulary)처럼 처리하는 방식을 채택했습니다. 이는 연속적인 제어 값을 직접 예측하는 것보다 다중 모달리티 학습에서 손실 함수(Loss Function)의 수렴을 돕고, 복잡한 다단계 작업에서의 장기 의존성(Long-term dependency)을 처리하는 데 유리합니다.
- 멀티 모달 통합: 시각 인코더(Vision Encoder)는 고해상도 환경 세부 정보를 포착하고, 이를 언어 모델 프롬프트와 결합하여 ‘현재 상황에서 다음 취해야 할 최적의 물리적 이동’을 텍스트 생성하듯 추론합니다.
3.3 고효율 코드베이스 및 처리 최적화
본 논문의 진정한 기술적 성취는 Throughput 최적화에 있습니다. 8개의 GPU를 사용하는 환경에서 초당 261개의 샘플을 처리한다는 것은, 기존 OpenVLA나 다른 오픈소스 프레임워크와 비교했을 때 혁신적인 수준입니다.
이는 다음과 같은 기술적 최적화가 적용되었음을 시사합니다:
- 메모리 효율적 어텐션(FlashAttention 계열): 시각 토큰의 긴 시퀀스를 처리할 때 발생하는 메모리 병목 현상을 해결.
- 파이프라인 병렬화(Pipeline Parallelism)의 개선: 데이터 로딩과 연산 간의 지연 시간을 최소화하여 GPU 점유율(Utilization)을 극대화.
- 정밀도 최적화: 훈련 효율을 위해 혼합 정밀도(Mixed Precision)를 사용하면서도 로봇 제어의 정밀도가 깨지지 않도록 하는 캘리브레이션 기술 적용.
4. 구현 및 실험 환경 (Implementation Details & Experiment Setup)
4.1 하드웨어 구성
실험은 세 가지 다른 플랫폼에서 진행되었습니다. 이는 모델의 강건성(Robustness)을 증명하기 위한 필수적인 설계입니다.
- 플랫폼 A: 고정밀 조립 작업을 위한 고강성 로봇 암.
- 플랫폼 B: 물류 및 운반을 위한 모바일 매니퓰레이터 형태.
- 플랫폼 C: 저가형 교육용 하드웨어.
4.2 데이터셋 및 학습 전략
총 100개의 태스크는 단순한 집기(Pick-and-Place)부터 정교한 도구 사용(Tool Use)까지 포함합니다. 각 태스크당 약 130회의 포스트 트레이닝 에피소드를 거쳐 미세 조정(Fine-tuning)의 효율성을 검증했습니다. 놀라운 점은 적은 양의 추가 데이터만으로도 새로운 플랫폼에 빠르게 적응한다는 점인데, 이는 베이스 모델이 이미 물리적 법칙에 대한 강력한 사전 지식을 갖추고 있음을 방증합니다.
5. 성능 평가 및 비교 (Comparative Analysis)
LingBot-VLA는 기존의 SOTA(State-of-the-Art) 모델들과 비교하여 다음과 같은 우위를 점합니다.
- 범용 성능(Success Rate): 100개 태스크 평균 성공률에서 경쟁 모델을 15~20%p 이상 상회합니다. 특히 듀얼 암을 동시 조작해야 하는 협업 작업에서 차이가 극명하게 나타났습니다.
- 적응 속도(Adaptation Speed): 새로운 환경이나 플랫폼에 투입되었을 때, 필요한 GPU 시간(GPU Hours)이 타 모델 대비 40% 이상 절감되었습니다. 이는 상업적 도입 시 ‘TCO(총 소유 비용)’ 관점에서 엄청난 이점입니다.
- 추론 지연 시간(Latency): 실시간 제어에서 가장 중요한 제어 루프 주기를 안정적으로 유지합니다. 초당 261 샘플 처리량은 여러 대의 로봇을 하나의 서버에서 제어하거나, 고주파수 피드백 제어가 필요한 상황에서 결정적인 역할을 합니다.
6. 실제 적용 분야 및 글로벌 파급력 (Real-World Application & Impact)
LingBot-VLA의 등장은 로봇 산업의 패러다임을 ‘특수 목적형’에서 ‘범용 지능형’으로 바꿀 전환점이 될 것입니다.
6.1 스마트 팩토리 및 유연 생산 시스템
기존 공장 로봇은 프로그래밍된 궤적만을 반복합니다. LingBot-VLA가 탑재된 로봇은 비정형 환경에서도 작동합니다. 예를 들어, 부품의 위치가 어긋나거나 새로운 종류의 부품이 들어와도 추가 프로그래밍 없이 시각적 인식과 언어적 지시만으로 작업을 수행할 수 있습니다.
6.2 이커머스 및 물류 자동화
수만 가지의 서로 다른 형태를 가진 물건을 분류하고 포장하는 작업은 로봇에게 가장 어려운 과제 중 하나였습니다. LingBot-VLA의 강력한 VLA 능력은 물체의 재질, 무게 중심, 파지법을 스스로 판단하게 하여 물류 센터의 완전 자동화를 가능케 합니다.
6.3 가사 및 서비스 로봇
집안 환경은 매우 가변적입니다. LingBot-VLA의 듀얼 암 제어 능력은 요리, 빨래 개기, 설거지 등 양손 협업이 필수적인 복잡한 가사 노동을 수행할 수 있는 AI 뇌(Brain) 역할을 할 것입니다.
7. 한계점 및 기술적 비평 (Discussion: Limitations & Critical Critique)
Senior AI Scientist로서 이 연구에 대해 몇 가지 비판적인 시각을 견지할 필요가 있습니다.
첫째, ‘실용적(Pragmatic)’이라는 단어 이면의 데이터 의존성입니다. 20,000시간의 데이터는 거대하지만, 여전히 ‘지도 학습(Supervised Learning)’의 틀 안에 있습니다. 모델이 학습 데이터에 없는 완전히 새로운 물리 법칙( 예: 액체 따르기, 끈적이는 물체 다루기)에 직면했을 때의 대처 능력은 여전히 의문입니다. 진정한 파운데이션 모델이라면 자기 주도 학습(Self-supervised learning) 비중을 더 높여야 할 것입니다.
둘째, 하드웨어의 마모와 센서 노이즈에 대한 언급이 부족합니다. 실험실 환경에서의 261 FPS는 훌륭하지만, 먼지가 많거나 조명이 불안정한 실제 공장 현장에서의 Vision Encoder 신뢰도는 검증이 더 필요합니다.
셋째, 안전성(Safety) 가드레일의 부재입니다. VLA 모델이 생성하는 행동 토큰이 로봇의 관절 한계점(Joint Limit)을 넘어서거나 인간과 충돌할 가능성이 있을 때, 이를 모델 내부에서 어떻게 차단하는지에 대한 아키텍처적 장치가 명확하지 않습니다.
8. 결론 및 인사이트 (Conclusion)
LingBot-VLA는 로봇 파운데이션 모델이 지향해야 할 현실적인 이정표를 제시했습니다. 성능과 효율성, 그리고 범용 플랫폼 대응 능력이라는 세 축을 동시에 강화함으로써, ‘연구실의 장난감’이었던 로봇 AI를 ‘산업 현장의 도구’로 격상시켰습니다.
특히 코드와 모델, 데이터를 모두 오픈소스로 공개한 것은 로봇 생태계 전체에 강력한 촉매제가 될 것입니다. 개발자들은 이제 밑바닥부터 모델을 만들 필요 없이, LingBot-VLA를 베이스로 하여 각자의 특수 환경에 맞는 ‘Action-tuned’ 모델을 빠르게 구축할 수 있게 되었습니다.
우리는 이제 하드웨어가 지능을 기다리는 시대가 아니라, 지능이 하드웨어의 한계를 시험하는 시대로 진입하고 있습니다. LingBot-VLA는 그 최전선에 서 있는 모델임에 틀림없습니다.
본 칼럼은 최신 AI 연구 동향을 분석하여 기술적 가치를 평가한 리포트입니다.
