[2026-03-13] 💥 하나의 모델, 두 개의 뇌: 텍스트 이해와 이미지 생성을 찢어버린 'Cheers' 아키텍처 해부

Paper Link: 2603.12793 Github: TBA Date: March 2026
솔직히 까놓고 말해봅시다. 요즘 멀티모달 모델(UMM) 생태계를 보면 기가 찹니다. 비전 인코더랑 LLM을 억지로 이어 붙여놓고 ‘만능’이라고 우기는 경우가 태반이죠. 이미지를 ‘이해’하는 태스크는 픽셀의 자잘한 디테일보다는 전체적인 ‘의미(Semantic)’를 뭉뚱그려 파악하는 게 중요합니다. 반대로 이미지를 ‘생성’하려면 머리카락 한 올, 벽돌의 질감 하나하나 같은 ‘디테일(Patch details)’이 목숨줄입니다. 이 두 가지 서로 다른 방향성을 하나의 피처 스페이스에 구겨 넣으려니 모델이 바보가 될 수밖에 없는 겁니다.
텍스트를 잘 이해하게 만들면 생성된 이미지가 찰흙 덩어리가 되고, 반대로 이미지 퀄리티를 높이면 모델이 시각적 문맥을 까먹어버립니다. 이걸 해결하겠다고 파라미터만 무식하게 키우다가 GPU 클러스터 대여료만 수억 원씩 깨지고 있죠. 그런데 이번에 등장한 Cheers 논문은 이 지긋지긋한 딜레마를 아주 영리하고 변태적인 아키텍처로 박살 냈습니다.
TL;DR: 시각적 ‘의미’와 ‘디테일’의 경로를 물리적으로 분리(Decoupling)하여 토큰을 4배 압축하고, 타겟 UMM(Tar-1.5B) 대비 학습 비용을 80%나 깎아버린 압도적 효율의 통합 멀티모달 프레임워크.
 Figure 1: 이해(Understanding)와 생성(Generation) 벤치마크 모두에서 동급 모델들을 학살하는 성능. 특히 이미지 생성 퀄리티가 기존 통합 모델들이 겪던 고질적인 ‘블러링’ 현상을 완벽히 극복한 것이 눈에 띕니다.
Figure 1: 이해(Understanding)와 생성(Generation) 벤치마크 모두에서 동급 모델들을 학살하는 성능. 특히 이미지 생성 퀄리티가 기존 통합 모델들이 겪던 고질적인 ‘블러링’ 현상을 완벽히 극복한 것이 눈에 띕니다.
⚙️ 픽셀 뭉치를 3D 공간으로 연성하는 파이프라인 해부
Cheers의 핵심 철학은 아주 단순하고 명쾌합니다. “LLM한테 굳이 픽셀 쪼가리 데이터를 쌩으로 다 던져줄 필요가 있나?”라는 거죠. 기존 모델들이 비전 인코더에서 나온 결과를 통째로 LLM에 밀어 넣었다면, Cheers는 이 흐름 자체를 시작점부터 두 갈래로 쪼개버렸습니다.
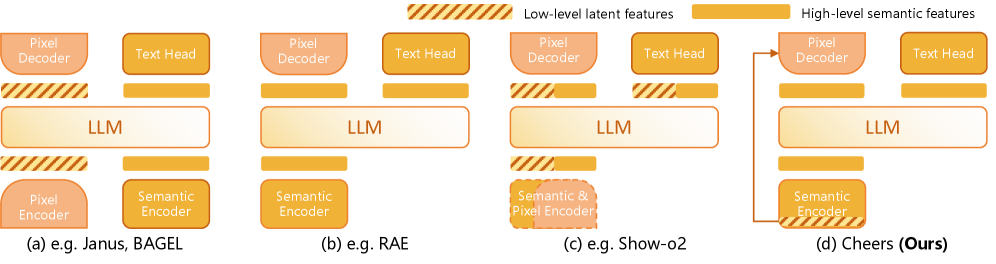 Figure 2: 끔찍했던 기존 아키텍처(a,b,c)와의 비교. Cheers(d)는 의미적 안정성을 위해 LLM과 소통하는 토큰과, 생성 디테일을 살리기 위한 토큰을 별도로 분리하여 피처 간섭(Interference)을 원천 차단했습니다.
Figure 2: 끔찍했던 기존 아키텍처(a,b,c)와의 비교. Cheers(d)는 의미적 안정성을 위해 LLM과 소통하는 토큰과, 생성 디테일을 살리기 위한 토큰을 별도로 분리하여 피처 간섭(Interference)을 원천 차단했습니다.
🔹 Unified Vision Tokenizer (통합 비전 토크나이저) 입력된 이미지를 두 가지 형태의 토큰으로 압축합니다. 하나는 LLM이 텍스트와 함께 씹어먹을 Semantic Tokens(의미 토큰)이고, 다른 하나는 나중에 이미지 생성 시 디테일을 살릴 때 쓸 Detail Tokens(디테일 토큰)입니다. 여기서 이미 토큰 수를 1/4로 압축(4x token compression)해버리기 때문에 LLM이 감당해야 할 컨텍스트 윈도우 연산 부담이 획기적으로 줄어듭니다.
🔹 LLM-based Transformer (자기회귀 & 디퓨전 통합 백본) 텍스트 생성은 흔히 아는 Auto-regressive 방식으로 처리합니다. 재미있는 건 이미지 생성의 기반이 되는 Diffusion 디코딩 역시 같은 트랜스포머 백본에서 처리한다는 점입니다. 이 단계에서는 앞서 추출한 Semantic 토큰만 활용하여 생성할 이미지의 전체적인 뼈대와 문맥을 잡는 역할을 수행합니다.
🔹 Cascaded Flow Matching (CFM) Head 이 아키텍처의 진짜 마법은 여기서 벌어집니다. LLM이 뱉어낸 거대한 ‘의미적 뼈대’ 위에, 아까 빼돌려놨던 ‘디테일 토큰’을 Gated Residual 형태로 주입(Inject)합니다. 고주파수(High-frequency)의 쨍한 디테일을 여기서 덧칠하는 겁니다. CFM 헤드는 연속적인 시간 흐름 속에서 속도장(Velocity Field)을 예측하며, 가우시안 노이즈에서 시작해 최종 이미지 잠재 변수(Terminal Latent)로 완벽하게 수렴해 나갑니다. 마지막으로 이 최종 잠재 변수는 VAE 디코더를 거쳐 우리가 눈으로 볼 수 있는 고해상도 픽셀 이미지로 환원되죠.
아래는 Cheers의 내부 데이터 흐름을 직관적으로 이해하기 위해 작성해 본 수도 코드(Pseudo-code)입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
def forward_cheers(image_input, text_prompt, task_type):
# 1. 토크나이저: 의미와 디테일을 강제로 이혼시킵니다. (토큰 4배 압축)
semantic_tokens, detail_tokens = unified_vision_tokenizer(image_input)
# 2. LLM 트랜스포머: 의미 토큰만 가지고 텍스트/이미지 뼈대 생성
llm_output = llm_transformer(semantic_tokens, text_prompt)
if task_type == "generation":
# 3. CFM 헤드: 뼈대(llm_output) 위에 디테일 토큰을 조건부 주입
final_latent = cfm_head(
base_semantics=llm_output,
high_freq_residuals=gate_mechanism(detail_tokens)
)
return vae_decode(final_latent)
else:
return generate_text(llm_output)
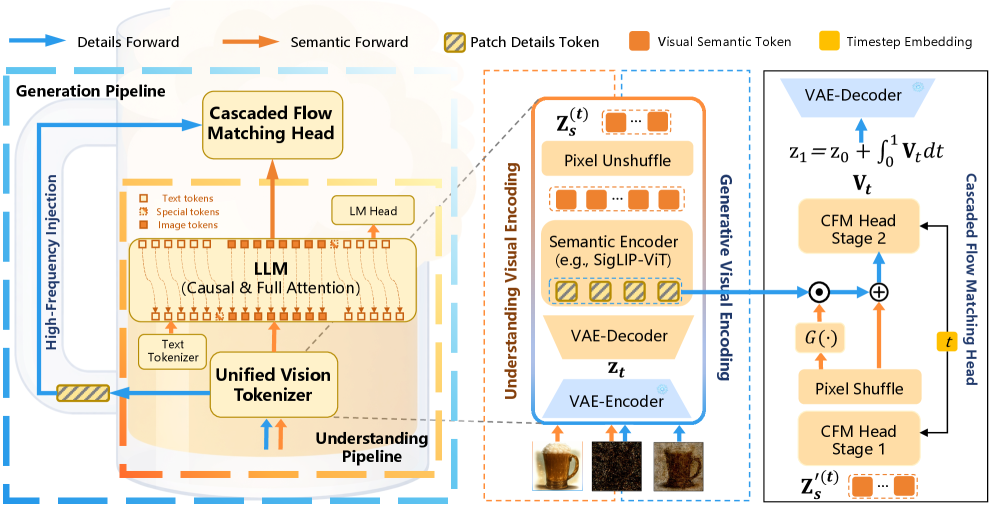 Figure 3: 전체 파이프라인의 구조도. VAE 디코더로 넘어가기 전, CFM Head에서 어떻게 노이즈를 걷어내며 디테일 토큰을 스텝에 맞춰 적절히 쏟아붓는지 명확하게 보여줍니다.
Figure 3: 전체 파이프라인의 구조도. VAE 디코더로 넘어가기 전, CFM Head에서 어떻게 노이즈를 걷어내며 디테일 토큰을 스텝에 맞춰 적절히 쏟아붓는지 명확하게 보여줍니다.
⚔️ 기존 스택 vs 새로운 패러다임: 진짜 쓸만한가?
맨날 논문에서는 “우리 방식이 SOTA를 찍었다”라고 떠들죠. 하지만 진짜 실무자 입장에서 와닿는 수치로 기존 접근법과 냉정하게 비교해 봅시다. LLaVA 계열(이해 전용)과 Stable Diffusion(생성 전용)을 따로 띄워서 파이프라인을 엮는 방식, Tar-1.5B 같은 기존 최신 UMM, 그리고 Cheers를 테이블로 정리해봤습니다.
| Metric | LLaVA + SDXL (Separate) | Tar-1.5B (Prior UMM) | Cheers (Ours) |
|---|---|---|---|
| Architecture Complexity | 2개의 무거운 모델 파이프라인 릴레이 | 단일 퓨전 (피처 간섭 발생) | Decoupled 단일 모델 (간섭 없음) |
| Token Compression | 없음 (비전 인코더 해상도에 극도로 의존) | 1x (원시 패치 토큰 무식하게 사용) | 4x Compression (극강의 효율) |
| Training Cost | 모델별 각각 학습 (비용 측정 불가) | Baseline (100% 기준) | 20% (80% 압도적 절감) |
| Context Window VRAM | VRAM 폭발 직전 (KV 캐시 낭비) | 꽤 무거움 | 매우 가벼움 |
| Visual Fidelity | 매우 높음 (SDXL 깡패) | 피처 간섭으로 인한 만성 블러링 | SDXL에 비빌만한 쨍한 디테일 |
이 표가 의미하는 바는 명확합니다. 토큰을 4배나 압축했기 때문에 고해상도 이미지를 입력으로 받아도 OOM(Out of Memory)이 뜰 확률이 기하급수적으로 낮아집니다. 게다가 Tar-1.5B 대비 학습 비용이 20%밖에 안 든다는 건, 우리 같은 인프라 거지 스타트업도 자체 데이터를 태워서 파인튜닝을 해볼 엄두를 낼 수 있다는 뜻이죠. 성능 타협 없이 80%의 GPU 비용을 아꼈다는 건 단순한 개선이 아니라 혁명에 가깝습니다.
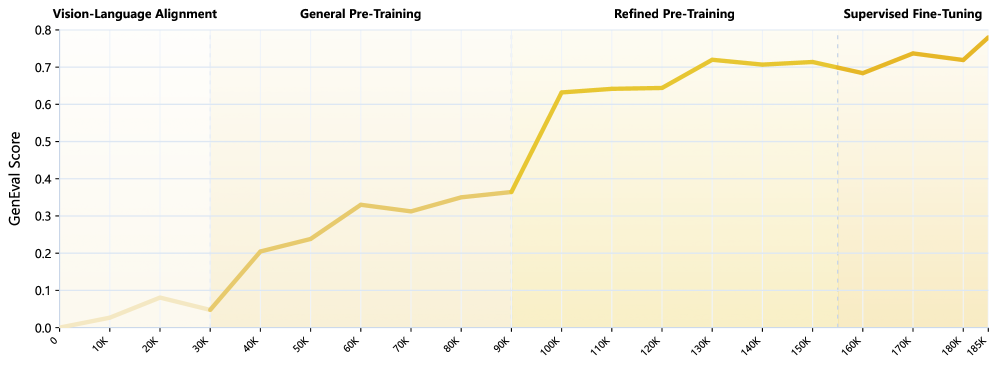 Figure 4: 누적 학습 스텝에 따른 GenEval 스코어 상승 곡선. 기존 모델들이 수만 시간의 GPU 타임을 태워가며 천천히 학습할 때, Cheers는 가파른 초기 수렴 속도를 보여주며 연산 자원을 아껴줍니다.
Figure 4: 누적 학습 스텝에 따른 GenEval 스코어 상승 곡선. 기존 모델들이 수만 시간의 GPU 타임을 태워가며 천천히 학습할 때, Cheers는 가파른 초기 수렴 속도를 보여주며 연산 자원을 아껴줍니다.
🚀 내일 당장 프로덕션에 도입한다면?
당장 내일 회사에서 멀티모달 파이프라인을 새롭게 구축해야 한다고 칩시다. 어떤 실무 시나리오에서 Cheers가 가장 빛을 발할까요?
1. 실시간 모바일 쇼핑 어시스턴트 (레이턴시와 VRAM 최적화) 유저가 본인 옷 사진을 찍어 올리면서 “이거랑 비슷한 스타일로 벙거지 모자 씌워서 보여줘”라고 요청하는 상황입니다. 기존 파이프라인이면 이미지를 캡셔닝 모델로 텍스트화하고(이해), 그걸 다시 프롬프트로 깎아서(LLM), 무거운 디퓨전 모델에 던져야(생성) 합니다. 딜레이가 최소 5~10초죠. 반면 Cheers는 4배 압축된 토큰 덕분에 컨텍스트 연산이 번개처럼 빠릅니다. 게다가 단일 파이프라인이라 T4 GPU 한 대만 띄워놔도 유저의 이탈을 막을 수 있는 빠른 레이턴시를 뽑아낼 수 있습니다.
2. 고해상도 디자인 에셋 자동 생성 API 디자이너들이 대충 그린 스케치를 바탕으로 고품질 게임 에셋을 생성하는 내부 툴을 만든다고 생각해 봅시다. CFM(Cascaded Flow Matching) 헤드의 진가가 여기서 나옵니다. 초기 스텝에서는 ‘전체적인 형태와 의미’를 잡고, 후반 스텝에서는 아껴뒀던 ‘고주파수 디테일’을 미친 듯이 때려 박습니다.
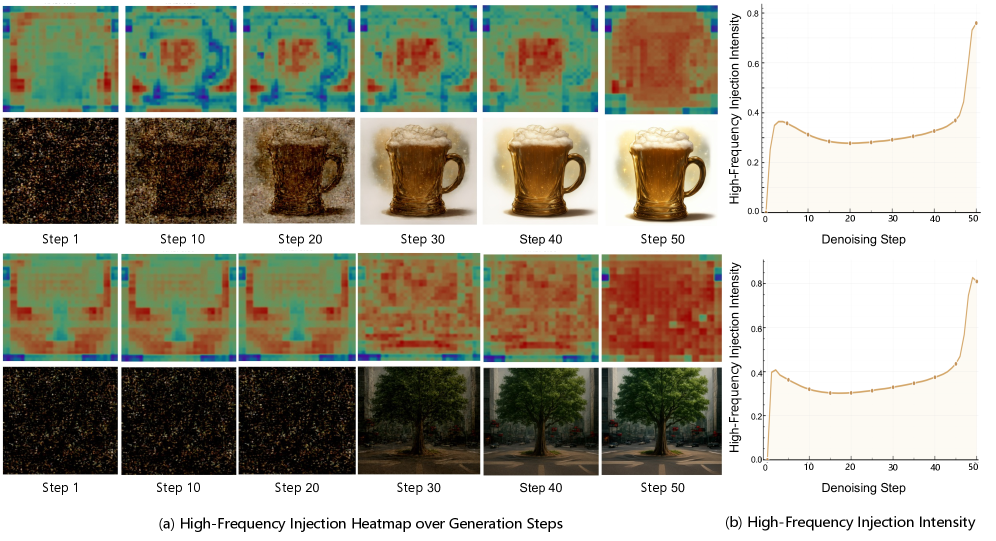 Figure 5: 생성 스텝별 고주파수(High-frequency) 주입 강도. 초반에는 전체적인 형상(Semantics)을 잡고, 후반부로 갈수록 질감이나 모서리 같은 마이크로 디테일을 폭발적으로 살려내는 과정을 확인할 수 있습니다.
Figure 5: 생성 스텝별 고주파수(High-frequency) 주입 강도. 초반에는 전체적인 형상(Semantics)을 잡고, 후반부로 갈수록 질감이나 모서리 같은 마이크로 디테일을 폭발적으로 살려내는 과정을 확인할 수 있습니다.
🧐 Tech Lead’s Honest Verdict
자, 이제 뽕을 빼고 냉정하게 평가해 볼 시간입니다.
👍 Pros: 이거 왜 안 써?
- 토큰 압축률의 축복: 4x 압축은 진짜 신의 한 수입니다. LLM의 어텐션 메커니즘 연산량이 시퀀스 길이의 제곱에 비례한다는 걸 생각하면, 이건 단순한 비용 절감이 아니라 ‘가능/불가능’을 나누는 기준이 됩니다.
- 미친 가성비: Tar-1.5B 대비 20%의 학습 비용. 이 정도면 A100 인스턴스 몇 개만 렌트해서 주말 내내 돌려볼 만한 부담 없는 사이즈입니다.
👎 Cons: 현실적인 빡침 포인트
- CFM Head 튜닝의 난해함: 디테일 토큰을 Gating하는 로직은 논문 수식으로 보면 깔끔해 보이지만, 실제 커스텀 엣지 케이스 데이터를 넣었을 때 하이퍼파라미터(특히 주입 강도)를 잡는 건 꽤나 끔찍한 노가다일 확률이 높습니다.
- 의존성 및 환경 지옥 예상: 디퓨전과 LLM을 단일 트랜스포머에 묶어놨기 때문에, 커스텀 쿠다 커널이나 xFormers 버전이 꼬이면 딥러닝 디버깅하다가 머리카락이 다 빠질 수도 있습니다. 공식 코드의 안정성이 매우 중요합니다.
🔥 Final Verdict: “내부 토이 프로젝트용으로 즉시 Clone. 프로덕션 도입은 코드 공개 후 한 달 뒤 커뮤니티 이슈 트래커 반응을 보고 결정할 것.” 비전과 언어를 통합하려는 시도는 셀 수 없이 많았지만, ‘이해’와 ‘생성’의 충돌을 물리적인 토큰 분리로 우아하게 해결한 이 접근법은 박수받아 마땅합니다. 멀티모달 모델 최적화와 파인튜닝으로 고통받고 있는 엔지니어라면 당장 깃허브 알림부터 켜두시기 바랍니다.
