[2026-02-06] DreamDojo: 4.4만 시간의 인간 비디오로 학습한 차세대 로봇 범용 월드 모델 심층 분석

DreamDojo: 4.4만 시간의 인간 비디오로 학습한 차세대 로봇 범용 월드 모델 심층 분석
1. 핵심 요약 (Executive Summary)
로봇 공학의 성배는 가상 세계에서 학습한 지능을 현실 세계로 전이시키는 것, 그리고 새로운 환경에서도 인간처럼 유연하게 대처하는 ‘범용 로봇 에이전트’를 구축하는 것입니다. 최근 AI 분야의 거대 모델 트렌드에도 불구하고, 로봇 학습은 여전히 데이터 부족(Data Scarcity)과 행동 라벨링(Action Labeling)의 한계에 부딪혀 왔습니다.
오늘 분석할 DreamDojo는 이러한 한계를 돌파하기 위해 44,000시간에 달하는 방대한 인간 1인칭(Egocentric) 영상을 활용하여 구축된 범용 월드 모델(Generalist World Model)입니다. 이 모델의 핵심은 라벨이 없는 대규모 영상 데이터에서 ‘잠재 행동(Latent Actions)’을 추출하여 물리 법칙과 상호작용의 원리를 학습하고, 이를 소량의 로봇 데이터를 통해 미세 조정함으로써 정교한 제어 능력을 확보하는 데 있습니다.
DreamDojo는 단순한 영상 생성을 넘어, 10.81 FPS의 실시간 추론 속도를 달성했으며, 실시간 텔레오퍼레이션(Teleoperation), 정책 평가(Policy Evaluation), 모델 기반 계획(Model-based Planning) 등 실제 로봇 제어의 핵심 파이프라인에 즉시 적용 가능한 수준의 성능을 보여줍니다.
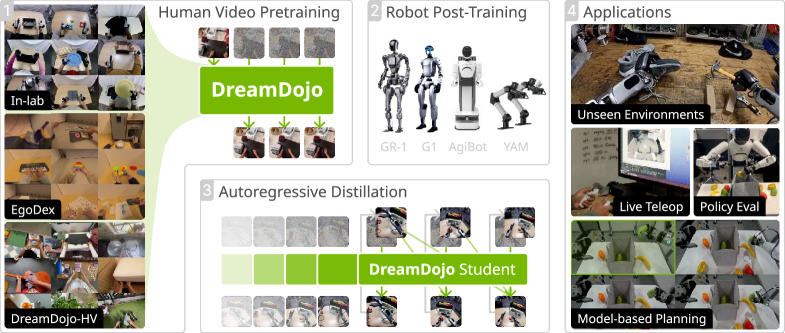 그림 1: DreamDojo의 전체적인 개요. 대규모 인간 데이터를 통해 물리 지식을 습득하고, 로봇 데이터를 통한 사후 학습 및 증류 과정을 거쳐 실시간 제어가 가능한 월드 모델로 거듭납니다.
그림 1: DreamDojo의 전체적인 개요. 대규모 인간 데이터를 통해 물리 지식을 습득하고, 로봇 데이터를 통한 사후 학습 및 증류 과정을 거쳐 실시간 제어가 가능한 월드 모델로 거듭납니다.
2. 연구 배경 및 문제 정의 (Introduction & Problem Statement)
2.1. 로봇 학습의 고질적 난제: 데이터 기근
전통적인 로봇 학습 방식은 로봇이 직접 환경과 상호작용하며 수집한 데이터(Robot-specific Data)에 의존해 왔습니다. 하지만 로봇 데이터는 수집 비용이 매우 비싸고, 하드웨어의 파손 위험이 있으며, 무엇보다 다양성이 부족하다는 치명적인 약점이 있습니다. 결과적으로 기존 모델들은 특정 작업이나 제한된 환경(In-distribution)에서는 잘 작동하지만, 조금만 새로운 환경(Out-of-distribution, OOD)에 놓여도 급격히 성능이 저하되는 현상을 보였습니다.
2.2. 월드 모델(World Model)의 부상
이 문제를 해결하기 위해 제시된 대안이 바로 ‘월드 모델’입니다. 월드 모델은 에이전트가 내린 행동에 따라 미래 상태가 어떻게 변할지를 예측하는 시뮬레이터 역할을 합니다. 만약 우리가 완벽에 가까운 월드 모델을 가질 수 있다면, 로봇은 위험한 현실 세계가 아닌 상상 속(가상 환경)에서 수억 번의 시행착오를 거치며 학습할 수 있습니다.
2.3. 행동 라벨이 없는 데이터의 활용 방안
인터넷에는 수백만 시간의 인간 영상 데이터가 존재합니다. 이는 로봇 데이터보다 훨씬 방대하고 다양합니다. 하지만 이 데이터에는 로봇 제어에 필요한 ‘행동 값(Action Labels, 예: 모터의 토크, 관절의 각도)’이 없습니다. 인간이 사과를 집는 영상은 많지만, 그 인간의 근육에 전달된 전기 신호나 손가락의 정확한 좌표 변화를 알 수는 없기 때문입니다. DreamDojo는 바로 이 ‘라벨 없는 대량의 영상’에서 어떻게 의미 있는 행동 지능을 추출할 것인가라는 질문에서 시작되었습니다.
3. 핵심 기술 및 아키텍처 심층 분석 (Core Methodology)
DreamDojo의 아키텍처는 크게 세 가지 단계로 나뉩니다: 데이터 믹스처 구성, 잠재 행동 모델(Latent Action Model) 설계, 그리고 실시간 증류(Distillation).
3.1. 대규모 인간 영상 데이터셋: DreamDojo-HV
연구진은 44,000시간 이상의 대규모 인간 비디오 데이터셋을 구축했습니다. 이는 현재까지 로봇 월드 모델 학습에 사용된 데이터 중 최대 규모입니다. 이 데이터셋은 단순히 양만 많은 것이 아니라, 일상 생활에서 발생하는 복잡하고 섬세한 조작 과업(Dexterous Tasks)을 포함하고 있습니다.
![Figure 2:Distribution analysis of DreamDojo-HV.(a)Distribution of the scenarios and random examples from the most frequent categories.(b)[Left]: Distribution of subtask numbers within each video. Most videos involve long-horizon tasks that require multiple interactions to accomplish. [Right]: Representative skills in DreamDojo-HV and their frequencies. Our dataset covers a wide range of interaction types beyond pick-and-place.(c)Visualization of skill verbs and object names based on their frequency of occurrence in language annotations.](https://www.opsoai.com/assets/img/papers/2602.06949/x2.png) 그림 2: DreamDojo-HV 데이터셋의 분포 분석. 단순한 집기(Pick-and-place)를 넘어 다양한 환경과 상호작용 기술을 포괄하고 있음을 보여줍니다.
그림 2: DreamDojo-HV 데이터셋의 분포 분석. 단순한 집기(Pick-and-place)를 넘어 다양한 환경과 상호작용 기술을 포괄하고 있음을 보여줍니다.
위의 그림 2에서 볼 수 있듯이, DreamDojo-HV는 시나리오의 다양성(Scenarios), 긴 호흡의 과업(Long-horizon tasks), 그리고 수많은 동사-목적어 조합(Skill verbs and objects)을 통해 물리 세계의 풍부한 맥락을 제공합니다. 이는 모델이 ‘물리적 인과관계’를 파악하는 데 결정적인 역할을 합니다.
3.2. 잠재 행동 모델 (Latent Action Model, LAM)
DreamDojo의 가장 혁신적인 지점은 연속적 잠재 행동(Continuous Latent Actions)의 도입입니다. 행동 라벨이 없는 영상에서 인접한 두 프레임 사이의 변화를 ‘행동’으로 정의하는 방식입니다.
![Figure 3:Latent action model.[Left]: The information bottleneck design of our latent action model enforces action disentanglement, producing a continuous latent vector that represents actions between frames. [Right]: We retrieve and group the frame pairs from different datasets that share the most similar latent actions. The embodiments are performing the same actions despite the significant differences in context.](https://www.opsoai.com/assets/img/papers/2602.06949/x3.png) 그림 3: 잠재 행동 모델(LAM)의 구조. 정보 병목(Information Bottleneck) 설계를 통해 외형(Appearance) 정보를 배제하고 순수한 행동(Action) 정보만을 추출합니다.
그림 3: 잠재 행동 모델(LAM)의 구조. 정보 병목(Information Bottleneck) 설계를 통해 외형(Appearance) 정보를 배제하고 순수한 행동(Action) 정보만을 추출합니다.
LAM은 두 프레임 ($s_t, s_{t+1}$)을 입력받아 잠재 벡터 $a_t$를 생성합니다. 이때 핵심은 정보 병목(Information Bottleneck) 설계입니다. 모델이 다음 프레임을 재구성할 때, 너무 많은 정보를 잠재 벡터에 담지 못하게 제한함으로써 모델이 배경이나 물체의 질감 같은 정보가 아닌, ‘물체가 어떻게 움직였는가’라는 핵심적인 행동 특성만을 포착하도록 강제합니다.
흥미로운 점은 그림 3의 오른쪽에서 보듯, 서로 다른 환경과 손 모양(Embodiment)을 가졌음에도 유사한 잠재 행동 벡터를 공유하는 경우를 시각화했을 때, 모델이 ‘밀기’, ‘당기기’와 같은 추상적인 행동의 의미를 정확히 이해하고 있다는 것이 확인되었습니다. 이는 ‘Cross-Embodiment’ 학습의 가능성을 시사합니다.
3.3. 사후 학습 및 실시간 증류 (Post-training & Distillation)
인간 영상으로 물리 상식을 배운 모델은 이제 실제 로봇 데이터(소량)를 통해 로봇의 특정 그리퍼나 카메라 시점에 적응하는 과정을 거칩니다. 또한, 일반적인 확산 모델(Diffusion Model) 기반의 월드 모델은 생성 속도가 매우 느려 실시간 제어에 부적합합니다. DreamDojo는 이를 해결하기 위해 Consistency Distillation 기법을 적용하여, 반복적인 샘플링 과정 없이도 단 몇 번의 스텝(One-step generation)만에 고품질의 미래 영상을 생성할 수 있도록 하여 10.81 FPS라는 경이로운 속도를 달성했습니다.
4. 구현 및 실험 환경 (Implementation Details)
DreamDojo는 최신 Vision Transformer(ViT) 아키텍처와 Flow-matching 기반의 비디오 생성 기법을 결합하였습니다.
- 데이터 스케일: 44k 시간의 인간 영상 + 0.5k 시간의 로봇 데이터.
- 아키텍처: DiT(Diffusion Transformer) 스타일의 구조를 사용하여 고해상도 비디오 문맥을 유지.
- 학습 전략: 대규모 사전 학습 후, 로봇 도메인에 특화된 LoRA(Low-Rank Adaptation) 또는 Full fine-tuning을 수행하여 도메인 간 간극(Gap)을 최소화.
- 평가 지표: 영상 품질(PSNR, SSIM, LPIPS)뿐만 아니라, 실제 로봇 정책을 평가했을 때의 성공률(Success Rate)과 실시간성(FPS)을 중점적으로 평가.
5. 성능 평가 및 비교 (Comparative Analysis)
DreamDojo의 진가는 OOD(Out-of-Distribution) 벤치마크에서 드러납니다. 연구진은 로봇이 한 번도 본 적 없는 6가지 복잡한 시나리오를 구성하여 테스트를 진행했습니다.
 그림 4: 벤치마크 시각화. DreamDojo의 일반화 능력을 테스트하기 위해 구축된 다양하고 도전적인 환경들.
그림 4: 벤치마크 시각화. DreamDojo의 일반화 능력을 테스트하기 위해 구축된 다양하고 도전적인 환경들.
실험 결과, DreamDojo는 기존의 SOTA(State-of-the-art) 모델들과 비교했을 때 압도적인 성능 향상을 보였습니다. 특히, 단순히 영상을 ‘그럴듯하게’ 만드는 것을 넘어, 물리적인 제약 조건(물체가 손에 가려져도 계속 존재해야 함, 중력에 의한 낙하 등)을 훨씬 더 정확하게 반영했습니다.
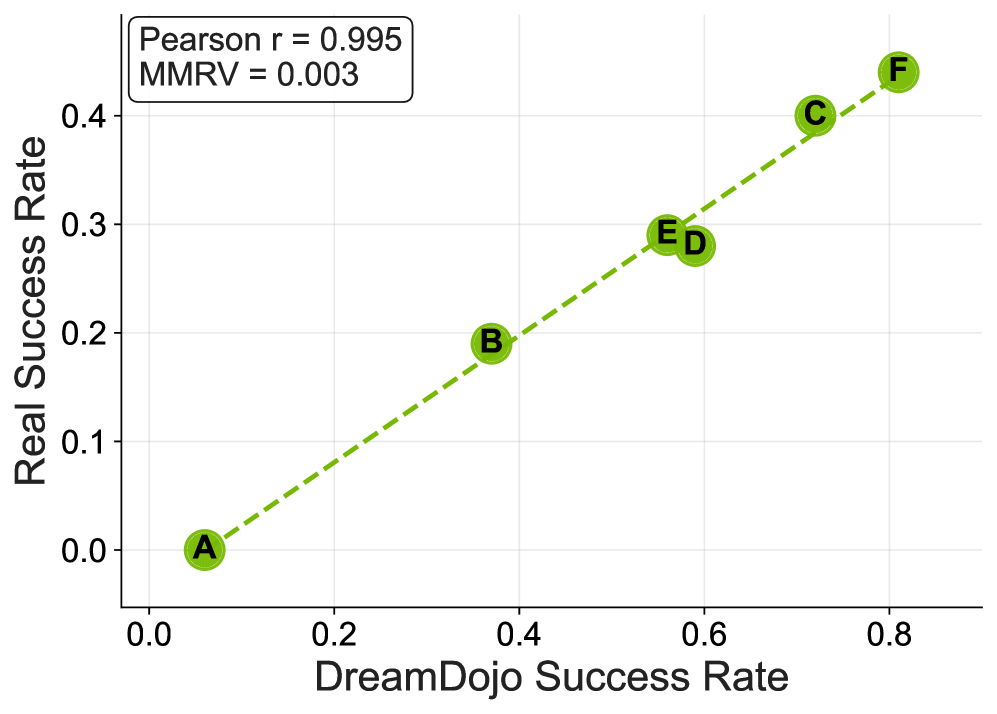 그림 5: 실제 환경과 DreamDojo 시뮬레이션 환경에서의 성공률 비교.
그림 5: 실제 환경과 DreamDojo 시뮬레이션 환경에서의 성공률 비교.
그림 5는 DreamDojo가 구축한 가상 세계에서의 정책 평가 결과가 실제 세계에서의 결과와 얼마나 일치하는지를 보여줍니다. 두 지표 사이의 상관관계가 매우 높다는 것은 DreamDojo를 이용한 가상 평가가 실제 로봇 배포 전의 ‘디지털 트윈’으로서 충분히 기능할 수 있음을 입증합니다.
6. 실제 적용 분야 및 글로벌 파급력 (Real-World Application & Impact)
DreamDojo는 단순한 연구 결과물을 넘어 산업계에 다음과 같은 혁신을 가져올 수 있습니다.
6.1. 무한한 가상 학습 데이터 생성 (Sim2Real 2.0)
기존의 Sim2Real은 물리 엔진(MuJoCo, Isaac Gym 등)을 사람이 일일이 코딩해야 했습니다. DreamDojo는 영상을 통해 물리 법칙을 학습하므로, 복잡한 코딩 없이도 현실과 유사한 시뮬레이션 환경을 자동으로 생성할 수 있습니다. 이는 로봇 학습 속도를 기하급수적으로 높일 것입니다.
6.2. 실시간 라이브 텔레오퍼레이션 (Live Teleoperation)
10 FPS 이상의 속도는 사람이 로봇을 원격 제어할 때 미래의 결과를 미리 예측해서 보여주는 기능을 가능하게 합니다. 통신 지연(Latency)이 있는 환경에서도 작업자는 모델이 예측한 미래 영상을 보며 선제적으로 대응할 수 있어, 보다 정밀한 원격 수술이나 우주 로봇 제어가 가능해집니다.
6.3. 온라인 모델 기반 계획 (Online Model-based Planning)
로봇이 행동을 실행하기 전, DreamDojo를 통해 수백 가지 시나리오를 ‘상상’해보고 가장 성공 확률이 높은 행동을 선택할 수 있습니다. 이는 예기치 못한 장애물이 나타나거나 환경이 변할 때 로봇의 적응력을 극대화합니다.
7. 기술적 비평 및 한계점 (Discussion: Limitations & Critical Critique)
본 연구가 로봇 월드 모델의 새로운 이정표를 세운 것은 분명하지만, 기술적인 관점에서 몇 가지 비판적 검토가 필요합니다.
- 잠재 행동의 명확성 결여: ‘연속적 잠재 행동’은 영상의 변화를 잘 포착하지만, 이것이 실제 로봇의 관절 토크나 각도와 수학적으로 어떻게 매핑되는지에 대한 이론적 설명이 부족합니다. 즉, 모델이 내부적으로 생성한 $a_t$가 실제 로봇 제어기에 전달될 때 발생할 수 있는 ‘해석 가능성(Interpretability)’ 문제가 존재합니다.
- 장기 예측의 안정성: 비디오 생성 기반 모델의 고질적 문제인 ‘Drift’ 현상이 여전히 존재할 가능성이 큽니다. 짧은 프레임(예: 8~16프레임) 예측은 정확하지만, 수분 이상의 긴 작업을 수행할 때 오차가 누적되어 현실과 동떨어진 결과를 낼 수 있습니다.
- 데이터 편향성: 인간 1인칭 영상은 손의 움직임에 집중되어 있습니다. 로봇의 하체가 움직여야 하는 이동형 로봇(Mobile Robot)이나 전신 조작(Whole-body control) 과업에 대해서도 인간 비디오 데이터가 동일한 효율성을 보일지는 미지수입니다.
- 계산 자원: 44,000시간의 영상을 학습시키기 위해 필요한 컴퓨팅 자원은 어마어마합니다. 이는 중소 규모의 연구실이나 기업이 접근하기 어려운 ‘자본 집약적 AI’의 전형을 보여주며, 연구의 재현성을 떨어뜨릴 우려가 있습니다.
8. 결론 및 인사이트 (Conclusion)
DreamDojo는 “데이터가 곧 지능이다”라는 AI의 대원칙을 로봇 공학에서 다시 한번 증명했습니다. 특히 라벨이 없는 대규모 인간 영상을 로봇의 ‘교과서’로 활용할 수 있는 구체적인 아키텍처(LAM + Distillation)를 제시했다는 점에서 그 가치가 높습니다.
시니어 AI 과학자로서 필자는 이 연구가 ‘로봇 판 Sora’의 탄생을 예고한다고 봅니다. 영상 생성 모델이 세상을 이해하기 시작할 때, 그 이해력은 비단 픽셀의 생성에 머물지 않고 물리적 상호작용의 원리로 전이됩니다. DreamDojo는 로봇이 현실 세계에 투입되기 전, 수천만 번의 가상 경험을 쌓게 해주는 ‘꿈의 도장(Dojo)’이 될 것입니다.
향후 이 모델이 텍스트 기반의 지시(Language-conditioned)와 결합하고, 더 긴 시간적 일관성(Long-term consistency)을 확보한다면, 우리는 비로소 공장이나 가정에서 사람과 함께 자연스럽게 협업하는 진정한 의미의 범용 로봇을 목격하게 될 것입니다.
