[2026-03-12] [비디오 생성] 캐릭터 두 명 넣었다고 얼굴 융합되는 현상, VAE 건너뛰는 잠재 공간(Latent) RL로 해결한 DreamVideo-Omni 해부하기

[Metadata]
- Paper: DreamVideo-Omni: Omni-Motion Controlled Multi-Subject Video Customization with Latent Identity Reinforcement Learning
- ID: Arxiv 2603.12257
- Category: Video Generation, Diffusion Models, Reinforcement Learning
최근 비디오 생성 AI 시장을 보면 참 답답할 때가 많습니다. 데모 영상만 보면 헐리우드 영화를 당장이라도 뚝딱 만들 것 같죠. 하지만 현실은 어떨까요? 특정 캐릭터 한 명의 얼굴(Identity)을 유지하며 움직이게 만드는 것도 프롬프트 엔지니어링과 LoRA 파라미터 깎는 노가다의 연속입니다.
그런데 만약 두 명 이상의 캐릭터를 하나의 씬에 넣고, A는 왼쪽으로 걸어가고 B는 오른쪽에서 뛰어오는데, 카메라는 패닝(Panning)을 해야 한다면? 지금까지의 오픈소스 스택(AnimateDiff, ControlNet-Video 등)으로는 어림도 없습니다. 캐릭터 두 명이 교차하는 순간 얼굴이 서로 융합된 혼종 괴물이 탄생하거나, 움직임이 커질수록 찰흙처럼 이목구비가 녹아내리기 일쑤죠.
오늘 뜯어볼 DreamVideo-Omni는 바로 이 지긋지긋한 ‘다중 객체 통제 불능’과 ‘정체성 붕괴(Identity Degradation)’ 문제를 해결하기 위해 작정하고 나온 녀석입니다. 단순히 데이터셋을 때려 넣은 게 아니라, 구조적으로 꽤나 영리하고 변태적인 엔지니어링 꼼수를 썼더군요.
한 줄 요약: 복잡한 카메라 워크와 여러 명의 캐릭터 동선을 한 번에 제어하면서, 캐릭터 얼굴이 뭉개지는 현상을 막기 위해 무거운 VAE 디코딩을 건너뛰고 Latent(잠재 공간) 단에서 직접 RL 보상을 때려 박은 독종 프레임워크.
⚙️ 피 터지는 다중 객체 제어, DiT와 잠재 공간 강화학습(RL)으로 멱살 잡기
기존 Diffusion 모델들이 멀티 객체 비디오를 만들 때 바보가 되는 이유는 단순합니다. 픽셀을 그럴싸하게 뭉개고 복원하는 데는 도가 텄지만, ‘누가(Who)’, ‘어디로(Where)’ 가는지에 대한 논리적 매핑 능력이 떨어지기 때문이죠. DreamVideo-Omni 팀은 이 문제를 해결하기 위해 프레임워크를 크게 두 단계(Stage)로 찢어발겼습니다.

- 그림 1. 이게 제로샷(Zero-shot)으로 된다고?: 단순한 텍스트 프롬프트가 아니라, A와 B 두 캐릭터의 레퍼런스 이미지와 개별 BBox(바운딩 박스) 궤적, 심지어 카메라 무빙까지 입력받아 얼굴 붕괴 없이 렌더링을 뽑아낸 결과물입니다.*
🔹 Stage 1: 누가 누군지 이름표부터 붙이자 (Group & Role Embeddings) 가장 먼저 해야 할 일은 Attention 레이어가 헷갈리지 않게 만드는 겁니다. 여러 장의 레퍼런스 이미지(Subject A, B)와 각자의 동선(Trajectory), 그리고 카메라의 움직임(Global motion) 등 이기종(Heterogeneous) 조건들이 쏟아져 들어옵니다. 이때 모델은 Condition-aware 3D RoPE (Rotary Positional Embedding)를 도입해 시간과 공간 좌표를 꽉 잡아둡니다. 그리고 결정적으로 Group and Role Embeddings를 사용합니다. 개발자 입장에서 비유하자면, 변수가 스코프를 벗어나 오염되지 않도록 각 모션 신호와 캐릭터의 정체성에 명시적인 포인터(네임택)를 매핑해버리는 짓입니다. 이로써 A의 움직임이 B의 얼굴에 반영되는 ‘컨트롤 모호성(Control Ambiguity)’을 원천 차단합니다.
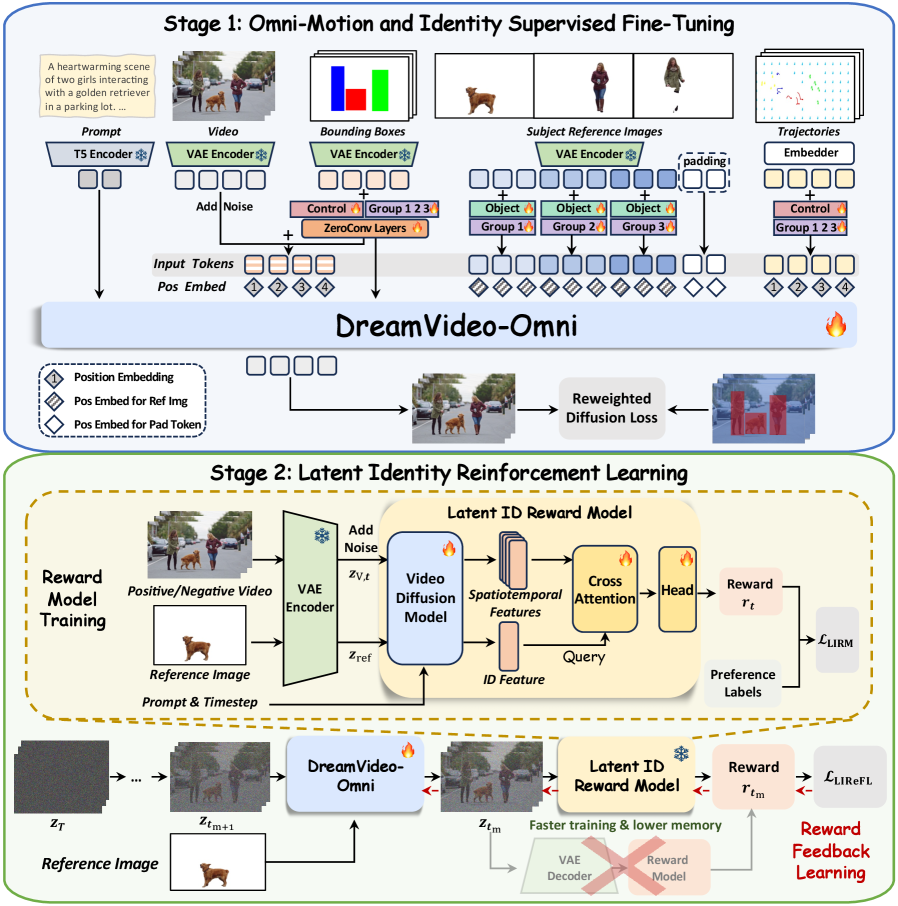
- 그림 2. DreamVideo-Omni의 뼈대 (특히 Stage 2를 주목하세요): Stage 1에서 멀티 조건이 통합된 Video DiT를 거친 후, Stage 2에서 무거운 VAE 디코더를 완전히 바이패스하고 Latent 상태의 텐서를 직접 평가해 Reward를 주는 구조입니다. 여기서 연산량이 극적으로 절감됩니다.*
🔹 Stage 2: 얼굴이 녹아내리기 전에 Latent에서 명치를 때린다 (Latent Identity RL) 개인적으로 이 논문의 진짜 하이라이트는 여기라고 봅니다. 캐릭터가 크게 움직이면 Identity가 무너집니다. 기존에는 이걸 막기 위해 생성된 결과를 픽셀 이미지로 디코딩한 다음, 얼굴 인식 모델을 돌려서 Loss를 계산해 페널티를 줬습니다. 근데 비디오 생성에서 매 스텝마다 VAE 디코더를 태운다? OOM(Out of Memory) 터지고 학습 속도는 나락으로 갑니다. 그래서 이들은 Latent Identity Reward Feedback Learning이라는 기가 막힌 우회로를 팠습니다. 아예 VAE 디코딩을 생략하고, Diffusion 프로세스 중간의 Latent(잠재) 텐서 자체를 읽어내어 “이 녀석 지금 A 캐릭터의 특징을 잃어버리고 있군” 하고 점수를 매기는 보상 모델(Reward Model)을 따로 학습시킨 겁니다. 쉽게 말해, 클럽 입구에서 민증 검사(픽셀 변환)를 하는 게 아니라, 이미 클럽 안에서 놀고 있는 애들의 관상(Latent)만 보고 쫓아내는 전담 기도(Bouncer)를 고용한 격입니다. 우아하면서도 무식하게 효율적이죠.
⚔️ 기존 비디오 제어 스택(ControlNet 등) vs DreamVideo-Omni의 뼈때리는 비교
현재 우리가 실무에서 자주 쓰는 파이프라인과 이 새로운 녀석을 비교해 봅시다.
| 비교 지표 | 기존 SOTA (IP-Adapter + 멀티 ControlNet) | DreamVideo-Omni | 실무적 의미 (Developer DX) |
|---|---|---|---|
| 멀티 객체 제어 | 마스킹 분리 등 파이프라인 복잡도 극상 | 네임택(Role Embedding)으로 네이티브 지원 | 노드 스파게티 탈출. 레퍼런스 2개 넣으면 알아서 분리됨. |
| 정체성(Identity) 유지 | 동선이 겹치거나 커지면 50% 확률로 얼굴 뭉개짐 | 모션 궤적을 철저히 따라가며 얼굴 형태 방어 | 재현율(Reproducibility) 상승. 가챠 뽑기 횟수 감소. |
| RL 학습 비용 (VRAM) | 픽셀 기반 RLHF. 노드 터지는 소리 들림 | Latent 기반 RL. VAE 스킵으로 극적 단축 | 컴퓨팅 예산을 절반 이하로 깎으면서도 디테일 강화. |
| Cold Start (데이터 준비) | 오픈 데이터셋 활용이 그나마 용이함 | [단점] 고도로 정제된 공간/시간 어노테이션 필수 | 프레임워크는 좋으나, 이걸 파인튜닝하려면 데이터 라벨링 지옥이 예상됨. |
기존 방식은 IP-Adapter로 얼굴 따오고, ControlNet으로 OpenPose 입히고, 거기에 AnimateDiff를 끼워 넣는 누더기 골렘 같은 방식이었습니다. 반면 DreamVideo-Omni는 아키텍처 레벨에서 멀티 조건과 모션을 통합 처리하기 때문에, 추론(Inference) 단계의 아키텍처가 훨씬 깔끔합니다.
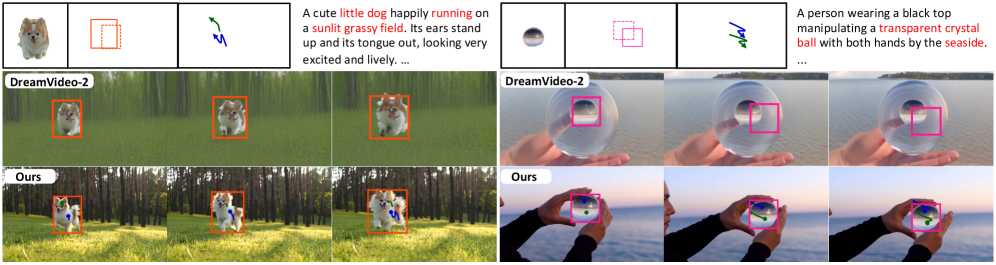
- 그림 3. 타 모델과의 피도 눈물도 없는 퀄리티 비교: 상단 궤적(빨간 선)을 따라 움직일 때, 기존 모델들은 뒤로 돌거나 겹칠 때 완전히 다른 사람으로 변해버리지만, Omni는 끝까지 이목구비의 일관성을 유지합니다.*
🚀 내일 당장 프로덕션에 쓸 수 있을까? (Use Cases)
이런 무거운 아키텍처 논문을 읽을 때마다 우리 머릿속을 스치는 질문이 있죠. “그래서 이걸로 우리 팀 KPI를 채울 수 있는가?” 저는 두 가지 명확한 씬(Scene)에서 이 기술이 폭발력을 가질 거라 봅니다.
1. 버추얼 인플루언서 및 브랜드 콜라보 광고 자동화 브랜드 마스코트(캐릭터 A)와 유명 셀럽(캐릭터 B)이 같이 걸어가며 특정 액션을 취하는 짧은 숏폼을 양산해야 한다고 가정해 봅시다. 기존에는 VFX 팀이 붙거나, 운에 맡기고 수백 번 프롬프트를 돌려야 했습니다. 이 프레임워크를 적용하면 BBox 궤적과 카메라 Panning 값만 JSON으로 던져주고, 두 명의 레퍼런스 이미지를 고정값으로 박아버리면 됩니다. 에이전시나 마케팅 자동화 팀의 워크플로우를 혁명적으로 단축시킬 수 있습니다.
2. 텍스트/스크립트 기반 스토리보드 자동 렌더링 (게임 프리비즈/영화 감독용) 단순히 “남자가 걷는다”가 아니라, “A는 뒤로 빠지면서 총을 쏘고, B는 오른쪽으로 구르는데, 카메라는 줌아웃된다” 수준의 미세한 동선(Fine-grained motion)이 필요한 게임 트레일러 프리비전이나 영화 프리비즈(Pre-viz) 단계. 기존 비디오 AI는 철저히 버림받았던 영역입니다. 이 모델은 BBox와 로컬 다이내믹스(Local dynamics)를 직접 주입받기 때문에 감독의 의도대로 정확히 씬을 블로킹(Blocking)할 수 있습니다.

- 그림 4. 데이터셋 구축의 고통(DreamOmni Bench): 이 엄청난 제어력의 이면에는 이토록 변태적으로 라벨링된(BBox, 마스크, 멀티 레퍼런스, 상세 캡션) 데이터셋이 존재합니다. 모델의 성능은 결국 양질의 데이터에서 나옵니다.*
🧐 Tech Lead’s Verdict: 과대포장인가, 진짜 혁신인가?
- 👍 Pros (진짜 칭찬할 점): VAE 디코딩을 스킵하고 Latent Space에서 직접 RLHF 보상을 먹인다는 발상은 엔지니어링 적으로 완벽에 가깝습니다. 이건 단순히 이 논문뿐만 아니라, 향후 우리가 사내에서 비디오 디퓨전 모델을 파인튜닝할 때 반드시 훔쳐와야 할 핵심 아이디어입니다. Group & Role 임베딩으로 컨텍스트 오염을 막은 것도 영리했습니다.
- 👎 Cons (까놓고 말해서): 늘 그렇듯 페인포인트는 데이터입니다. (그림 4 참고) 이 프레임워크가 제대로 동작하려면 학습 데이터 자체가 엄청나게 세밀한 시공간적 어노테이션(BBox, 궤적, 인스턴스 마스크 등)을 가지고 있어야 합니다. 우리 팀이 보유한 수만 시간의 ‘날것(Raw)’ 비디오 데이터를 이 모델에 당장 밀어 넣을 수는 없다는 뜻입니다. DreamOmni Bench 수준의 전처리 파이프라인을 구축하는 것 자체가 또 다른 거대한 프로젝트가 될 겁니다.
🔥 최종 판정 (Final Verdict): Wait for the code drop & ComfyUI Port. 당장 프로덕션 파이프라인을 갈아엎을 필요는 없습니다. 하지만 이 팀이 체크포인트 가중치(Weights)와 코드를 깃허브에 시원하게 공개하고, 발 빠른 오픈소스 생태계(특히 ComfyUI 노드 개발자들)가 이를 워크플로우로 포팅하는 순간, 비디오 생성 씬의 게임 체인저가 될 확률이 매우 높습니다. 일단 GitHub 레포지토리에 별(Star)부터 박아두고, ‘Latent Reward Model’ 개념은 여러분의 개인 노션에 꼭 메모해 두시길 바랍니다. 언젠가 VRAM 부족으로 울고 있을 때, 이 아이디어가 여러분의 퇴근 시간을 앞당겨 줄 겁니다. ```
Additional Figures
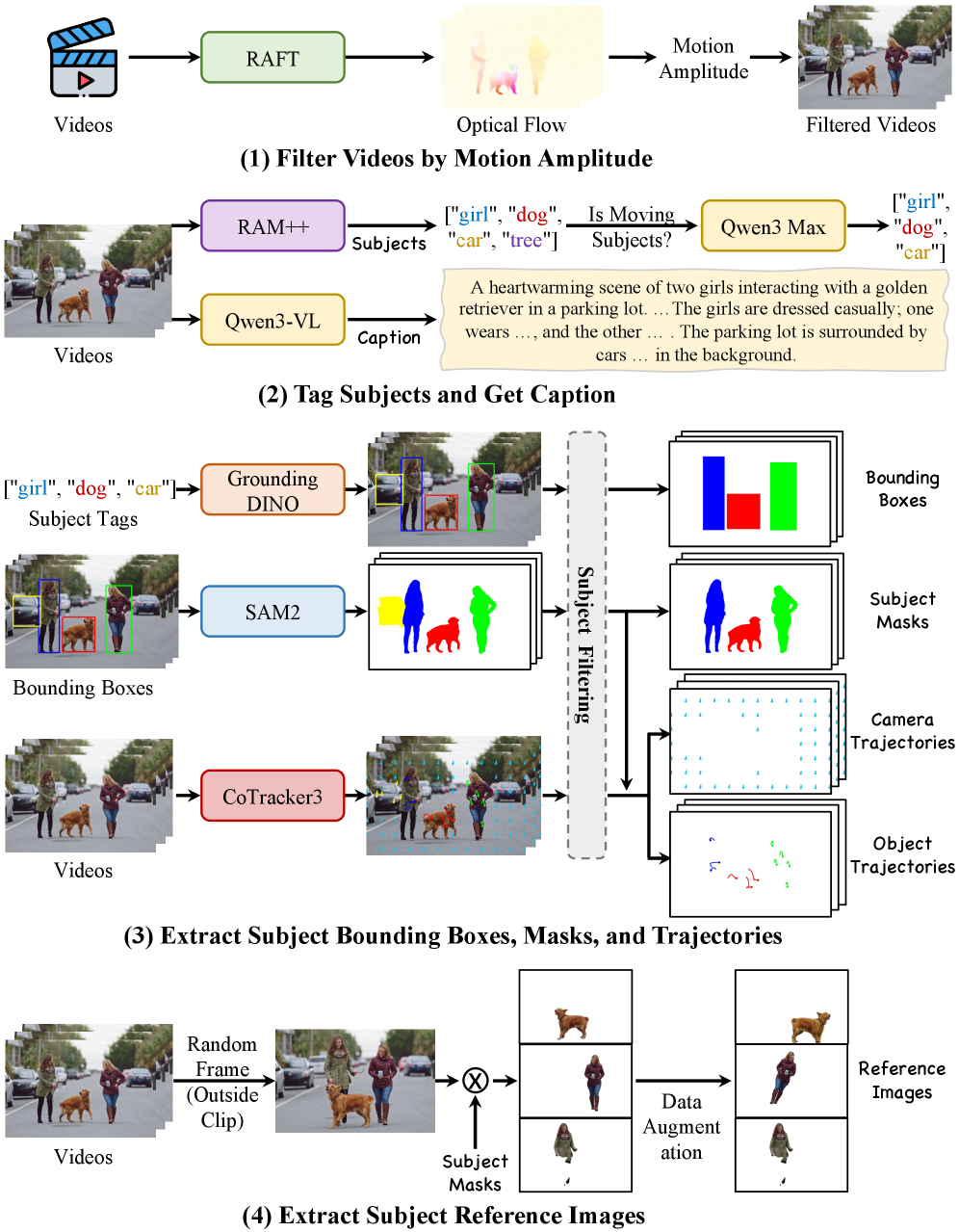 Figure 3:Pipeline of dataset construction.
Figure 3:Pipeline of dataset construction.
