[2026-02-24] 5분 연속 생성의 비밀: 짧게 배우고 길게 써먹는 Video-to-Audio (MMHNet 리뷰)

5분 연속 생성의 비밀: 짧게 배우고 길게 써먹는 Video-to-Audio (MMHNet 리뷰)
[Metadata]
- 📖 논문: Echoes Over Time: Unlocking Length Generalization in Video-to-Audio Generation Models
- 🖥️ Github/Project: https://echoesovertime.github.io
- 📅 발표일: 2026년 2월 24일
- ✍️ 저자/기관: Christian Simon, Masato Ishii 외
최근 Sora부터 Kling까지, AI 영상 생성 기술이 미친 듯이 발전하고 있습니다. 그런데 여러분, 여기서 한 가지 뼈아픈 문제가 있죠. 오디오는요?
현재 대부분의 Video-to-Audio (V2A) 모델은 10초 남짓한 짧은 클립에서는 기가 막히게 작동합니다. 하지만 영상 길이가 1분을 넘어가면? 마치 고장 난 라디오처럼 똑같은 소리가 반복되거나, 화면 속 자동차가 폭발하는데 새 지저귀는 소리가 나는 등 싱크가 완전히 박살납니다.
이 논문에서는 이 지긋지긋한 ‘길이 일반화(Length Generalization)’ 문제를 해결하기 위해 MMHNet(Multimodal Hierarchical Networks) 이라는 새로운 아키텍처를 들고나왔습니다.
💡 한 마디로? 짧은 영상 데이터로만 학습해도, 무려 5분 이상의 긴 영상에 완벽히 싱크가 맞는 고음질 오디오를 생성해내는 마법 같은 방법론입니다.
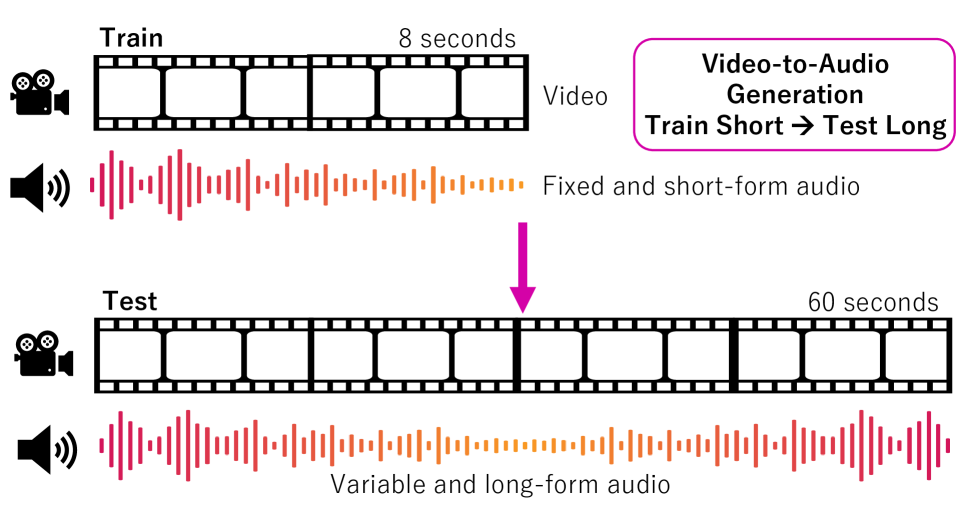 솔직히 처음 이 태스크 구조를 봤을 때, ‘이게 진짜 된다고?’ 싶었습니다. 학습과 추론의 길이를 분리하다니, 데이터 수집 비용을 극단적으로 낮출 수 있는 매우 도전적이고 실용적인 접근입니다.
솔직히 처음 이 태스크 구조를 봤을 때, ‘이게 진짜 된다고?’ 싶었습니다. 학습과 추론의 길이를 분리하다니, 데이터 수집 비용을 극단적으로 낮출 수 있는 매우 도전적이고 실용적인 접근입니다.
1. 도대체 뭐가 다른 건데? (What is it?)
이 논문이 제안하는 방식을 한마디로 비유하자면, ‘1인분 요리법만 배워서 100인분 뷔페를 완벽하게 차려내는 셰프’와 같습니다.
기존 모델들은 긴 오디오를 생성하려면 길고 방대한 데이터로 직접 학습해야만 했습니다. 하지만 5분짜리 고품질 오디오-비디오 페어 데이터를 구하는 건 현실적으로 엄청난 비용이 듭니다. 이 논문에서는 짧은 길이(Fixed-length)의 데이터만으로 학습하고도 긴 길이(Long-form)의 추론을 가능하게 만들었습니다.
🔹 학습은 짧게, 실전은 길게: 고비용의 긴 비디오 데이터 없이도 5분 이상의 오디오 생성이 가능합니다. 🔹 비인과적(Non-causal) Mamba 도입: 기존 모델들의 병목을 해결하기 위해 Mamba 구조를 활용, 전체적인 맥락(Global receptive field)을 유지합니다. 🔹 계층적 라우팅(Hierarchical Routing): 비디오, 텍스트, 오디오 토큰을 영리하게 쪼개고 합쳐 연산 효율성을 극대화합니다.
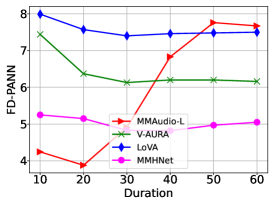
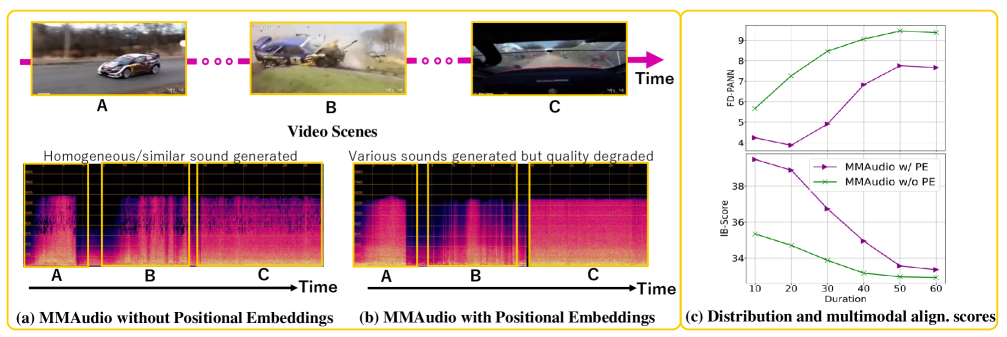 기존 모델(MMAudio)이 시간이 지날수록 어떻게 무너지는지 보여주는 뼈아픈 지표입니다. PE(Positional Embedding)를 없애면 시간적 흐름 자체를 놓치고, 억지로 조정하면 사운드 퀄리티가 박살 나는 한계를 보여줍니다.
기존 모델(MMAudio)이 시간이 지날수록 어떻게 무너지는지 보여주는 뼈아픈 지표입니다. PE(Positional Embedding)를 없애면 시간적 흐름 자체를 놓치고, 억지로 조정하면 사운드 퀄리티가 박살 나는 한계를 보여줍니다.
2. 핵심 기능 및 비교 (이게 왜 실무에서 중요할까?)
연구진은 자신들의 MMHNet을 기존 SOTA 모델인 MMAudio 등과 직접 비교했습니다. 성능 비교를 표로 정리해 봤습니다.
| 비교 항목 | 기존 V2A 모델 (예: MMAudio) | MMHNet (제안 모델) |
|---|---|---|
| 최대 생성 길이 | 보통 10~30초 (길어지면 품질 붕괴) | 5분 이상 (안정적 유지) |
| 학습 데이터 요구사항 | 긴 오디오 생성을 위해 긴 데이터 필수 | 짧은(Fixed-length) 데이터만으로 충분 |
| 핵심 아키텍처 | Standard Attention (MMDiT) | Hierarchical method + Non-causal Mamba |
| 오디오-비디오 정렬 | 시간이 지날수록 싱크가 어긋남 | 장시간에도 완벽한 모달리티 정렬 유지 |
왜 이 결과가 중요할까요? 실제 서비스 환경을 생각해 봅시다. 유저가 3분짜리 브이로그 영상을 올렸는데, 자동 배경음악을 입히려면 기존에는 10초씩 끊어서 수십 번을 추론하고 그걸 억지로 이어 붙여야 했습니다. 당연히 이음새가 어색할 수밖에 없죠. MMHNet은 이 과정을 한 번의 흐름으로 매끄럽게 처리해 버린다는 점에서 산업적 파급력이 큽니다.
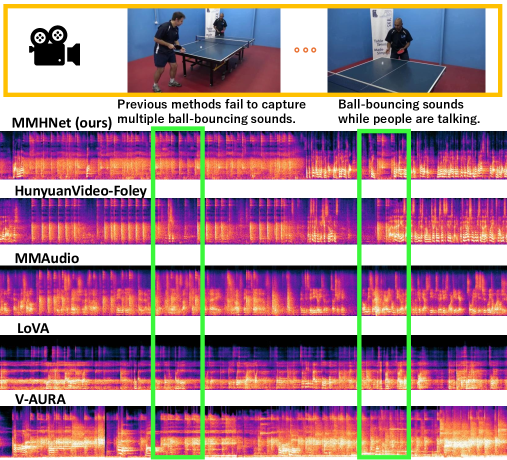 스펙트로그램 시각화만 봐도 MMHNet의 결과물(아래쪽)이 훨씬 촘촘하고 일관성 있게 유지되는 것을 볼 수 있습니다. 노이즈 없이 선명한 패턴, 실무자라면 여기서 기립 박수를 칠 수밖에 없죠.
스펙트로그램 시각화만 봐도 MMHNet의 결과물(아래쪽)이 훨씬 촘촘하고 일관성 있게 유지되는 것을 볼 수 있습니다. 노이즈 없이 선명한 패턴, 실무자라면 여기서 기립 박수를 칠 수밖에 없죠.
3. 기술적 Deep Dive: 도대체 어떻게 구현했나?
이 논문에서는 복잡한 수식과 구조를 설명하지만, 핵심 아이디어는 생각보다 직관적입니다. Flow-matching 모델 기반 위에, Temporal Routing과 Multimodal Routing을 영리하게 결합했습니다.
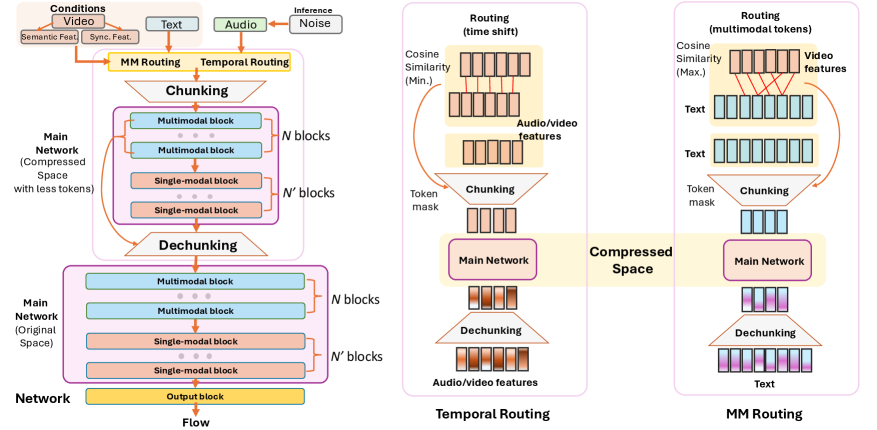 구조를 보면 복잡해 보이지만, 요점은 ‘시간(Temporal)과 모달리티(Multimodal)를 어떻게 쪼개고 효율적으로 엮을 것인가’에 있습니다. 압축된 공간에서 연산을 수행해 자원 낭비도 줄였네요.
구조를 보면 복잡해 보이지만, 요점은 ‘시간(Temporal)과 모달리티(Multimodal)를 어떻게 쪼개고 효율적으로 엮을 것인가’에 있습니다. 압축된 공간에서 연산을 수행해 자원 낭비도 줄였네요.
이 구조의 동작 방식을 직관적인 파이썬 의사 코드(Pseudo-code)로 표현하자면 이렇습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# MMHNet의 개념적 동작 원리
class MMHNet:
def __init__(self):
self.temporal_router = TemporalRouter(method="dynamic_chunking")
self.mamba_block = NonCausalMamba()
self.multimodal_fusion = MultimodalRouting()
def generate_long_audio(self, video_frames, text_prompt):
# 1. 긴 비디오를 처리 가능한 짧은 청크로 나눔 (Dynamic Chunking)
chunks = self.temporal_router.chunk(video_frames)
audio_features = []
for chunk in chunks:
# 2. Non-causal Mamba를 통해 전체 맥락 유지
context_aware_feat = self.mamba_block(chunk)
# 3. 비디오, 텍스트, 오디오 간의 강력한 연관성 통합
fused_feat = self.multimodal_fusion(context_aware_feat, text_prompt)
audio_features.append(fused_feat)
# 4. 끊김 없이 부드럽게 연결 (Smoothing)
smooth_long_audio = apply_smoothing(audio_features)
return smooth_long_audio
단순히 데이터를 이어 붙이는 게 아니라, Dynamic Chunking으로 쪼개고 Non-causal Mamba로 앞뒤 문맥을 모두 살피며 매끄럽게 이어 붙입니다. 이래서 짧은 데이터만으로도 긴 추론이 가능해진 것입니다.
🔥 에디터의 생각 (Editor’s Verdict)
✅ 장점 (Pros)
- 미친 데이터 가성비: 긴 비디오-오디오 페어 데이터셋을 구축하는 건 악몽 그 자체입니다. 짧은 데이터로 긴 추론을 해냈다는 건, 당장 스타트업이나 리소스가 부족한 연구실에서도 충분히 시도해볼 만한 길을 열어준 셈입니다.
- 실제 프로덕트 적용 가능성: 5분 연속 생성이 가능하다는 건, 영화 트레일러나 유튜브 브이로그용 AI BGM/효과음 생성기로 바로 투입될 여지가 크다는 뜻입니다.
❌ 아쉬운 점 / 한계 (Cons)
- 실무 적용엔 여전히 무리가 있어 보이는 지점도 있습니다. Mamba와 Hierarchical Network를 결합한 복잡한 구조 특성상, 파인튜닝 파라미터가 꽤나 민감할 것으로 예상됩니다.
- 5분 이상 안정적이라고는 하나, 화자가 대화하거나 매우 미세한 타이밍의 효과음(Foley)이 수백 개씩 들어가는 복잡한 도메인에서는 퀄리티가 어떻게 요동칠지 더 가혹한 제로샷 검증이 필요합니다.
총평: ⭐️⭐️⭐️⭐️ (4.5/5.0) *“비디오 생성 모델이 1분을 넘어 10분을 향해 가는 지금, 오디오 생성 진영에서 반드시 읽어야 할 필독서. 아이디어가 훌륭하니 오픈소스로 풀릴 V2를 강력히 기대해 보겠습니다.”
오늘 리뷰한 MMHNet은 AI 오디오 분야에 꽤나 신선한 충격을 던져주었습니다. 솔직히 이 부분은 놀랍네요. 긴 영상에도 찰떡같이 어울리는 사운드가 입혀질 날이 머지않은 것 같습니다. 여러분의 생각은 어떠신가요?
Additional Figures
 (a)
(a)
