[2026-02-15] Experiential Reinforcement Learning (ERL): 언어 모델의 '경험-성찰-내재화' 루프를 통한 강화학습의 새로운 지평

Experiential Reinforcement Learning (ERL): 언어 모델의 ‘경험-성찰-내재화’ 루프를 통한 강화학습의 새로운 지평
1. 핵심 요약 (Executive Summary)
최근 대규모 언어 모델(LLM)의 성능 향상을 위한 핵심 동력으로 강화학습(Reinforcement Learning, RL)이 주목받고 있습니다. 그러나 기존의 RL 방식은 보상이 희소(Sparse)하고 지연(Delayed)된 환경에서 학습 효율이 급격히 저하되는 고질적인 문제를 안고 있습니다. 본 고에서는 이러한 한계를 극복하기 위해 제안된 Experiential Reinforcement Learning (ERL) 방법론을 심층 분석합니다.
ERL의 핵심은 인간의 학습 과정과 유사한 ‘시도-성찰-교정-내재화’ 루프를 학습 알고리즘 내부에 직접 삽입한 것입니다. 모델은 단순히 성공과 실패의 스칼라 보상만을 받는 것이 아니라, 자신의 실패 원인을 스스로 분석(Reflection)하고 이를 바탕으로 수정한 두 번째 시도를 수행합니다. 이 과정에서 얻은 성공적인 경로를 원래의 정책(Policy)에 내재화함으로써, 추론 비용의 증가 없이도 복잡한 환경에서의 탐험 성능을 극대화합니다. 본 분석에서는 ERL이 어떻게 복잡한 다단계 환경에서 최대 81%의 성능 향상을 이끌어냈는지, 그리고 이것이 차세대 AI 에이전트 설계에 어떤 시사점을 주는지 기술적 관점에서 조명합니다.
2. 연구 배경 및 문제 정의 (Introduction & Problem Statement)
기존 강화학습의 한계: ‘왜’ 실패했는지 모르는 모델
언어 모델이 도구 사용(Tool-using), 추론(Reasoning), 그리고 복잡한 제어 작업에 투입될 때 가장 큰 걸림돌은 신용 할당 문제(Credit Assignment Problem)입니다. 예를 들어, 소코반(Sokoban) 게임이나 복잡한 멀티홉 QA(HotpotQA)에서 모델이 수십 단계의 추론 끝에 잘못된 답을 내놓았을 때, 기존의 강화학습(예: PPO, RLVR)은 단순히 ‘0점’이라는 보상만을 전달합니다.
이러한 방식은 다음과 같은 치명적인 단점이 있습니다:
- 희소 보상의 늪: 모델이 우연히 성공하기 전까지는 학습에 유의미한 신호를 전혀 받지 못합니다.
- 비효율적 탐험: 실패했을 때 무엇을 고쳐야 할지 모르기 때문에, 다음 시도에서도 유사한 실수를 반복하게 됩니다.
- 불안정한 최적화: 보상 신호가 불연속적이고 변동성이 커서 정책 수렴이 느립니다.
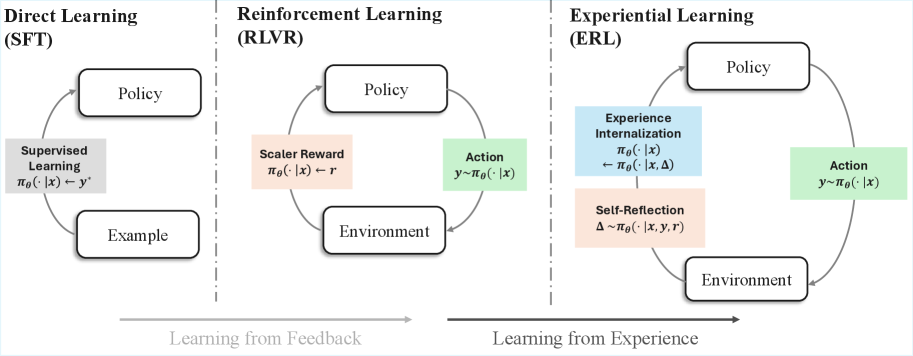 그림 1: ERL은 피드백으로부터 직접 배우는 대신, 경험과 결과를 언어적으로 성찰하고 이를 행동 변화로 내재화하는 과정을 거칩니다.
그림 1: ERL은 피드백으로부터 직접 배우는 대신, 경험과 결과를 언어적으로 성찰하고 이를 행동 변화로 내재화하는 과정을 거칩니다.
ERL의 제안: 경험을 구조화된 데이터로 전환
ERL 연구팀은 모델이 실패를 ‘학습의 기회’로 전환할 수 있는 구조적 장치를 제안합니다. 이는 인간이 오답 노트를 작성하며 성적을 올리는 과정과 매우 흡사합니다. 모델은 자신의 첫 번째 시도를 관찰하고, 환경의 피드백을 수용하며, ‘어떤 행동이 잘못되었는지’를 텍스트로 추론합니다. 이 ‘성찰(Reflection)’ 데이터는 단순한 스칼라 보상보다 훨씬 밀도 높은 정보를 담고 있으며, 이는 정책 최적화의 강력한 가이드가 됩니다.
3. 핵심 기술 및 아키텍처 심층 분석 (Core Methodology)
ERL은 크게 시도(Attempt) - 성찰(Reflection) - 정제(Refinement) - 내재화(Internalization)의 4단계 프로세스로 구성됩니다.
3.1. 경험-성찰-교정 루프 (The Experience-Reflection-Refinement Loop)
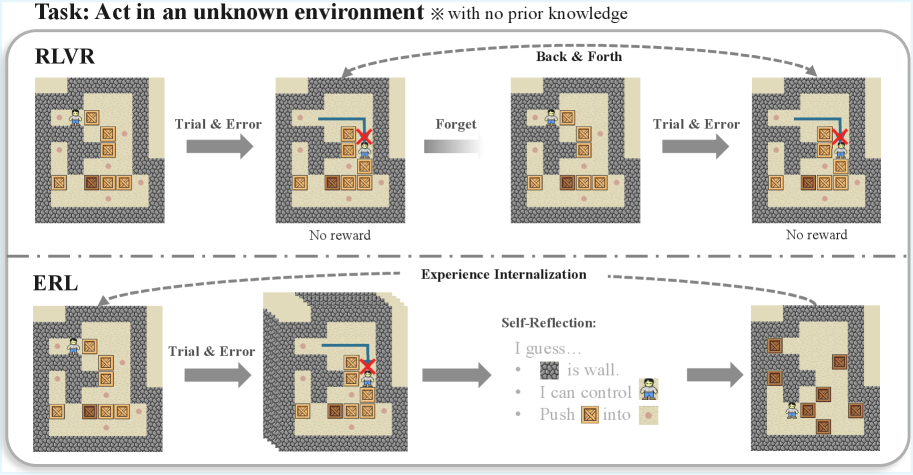 그림 2: RLVR과 ERL의 학습 동역학 비교. RLVR이 단순 시행착오에 의존하는 반면, ERL은 성찰 루프를 통해 지속적인 행동 개선을 이끌어냅니다.
그림 2: RLVR과 ERL의 학습 동역학 비교. RLVR이 단순 시행착오에 의존하는 반면, ERL은 성찰 루프를 통해 지속적인 행동 개선을 이끌어냅니다.
기존의 RLVR(Reinforcement Learning with Verifiable Rewards)이 단순히 여러 번의 시도를 독립적으로 수행하고 성공한 시도에 가중치를 두는 방식이라면, ERL은 시도 간의 인과관계를 설정합니다.
- Initial Attempt ($a_1$): 모델 $P_\theta$가 작업 $x$에 대해 첫 번째 결과물을 생성합니다.
- Environmental Feedback ($y_1$): 환경으로부터 성공 여부나 오류 메시지를 받습니다.
**Self-Reflection ($r$ $x, a_1, y_1$)**: 동일한 모델이 자신의 행동 $a_1$과 결과 $y_1$을 보고 무엇이 문제였는지 언어적으로 설명합니다. **Refined Attempt ($a_2$ $x, a_1, y_1, r$)**: 성찰 $r$을 조건부로 하여 더 나은 해결책 $a_2$를 생성합니다.
3.2. 자기 내재화 (Self-Internalization) 메커니즘
ERL의 진정한 혁신은 이 ‘성찰을 통한 개선’ 과정을 다시 모델의 원래 정책에 녹여낸다는 점에 있습니다. 추론 시점(Inference time)에 매번 성찰 루프를 돌리는 것은 비용이 너무 많이 듭니다. 따라서 ERL은 학습 과정에서 성공한 두 번째 시도($a_2$)의 데이터를 사용하여 첫 번째 시도($a_1$)를 생성하는 정책을 직접 업데이트합니다.
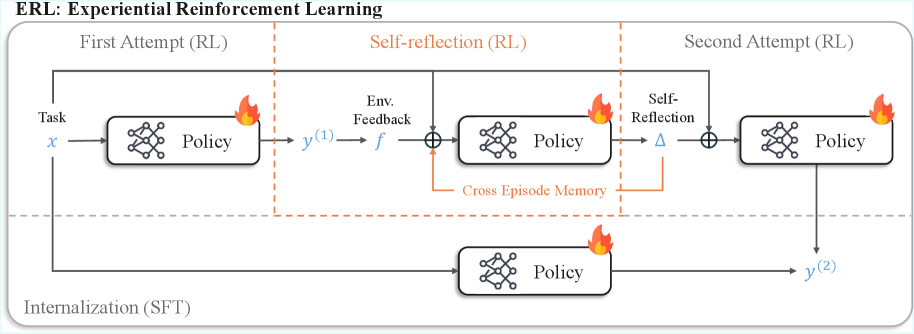 그림 3: ERL의 전체 개요. 첫 번째 시도와 성찰, 두 번째 시도가 모두 강화학습으로 최적화되며, 특히 성공한 두 번째 시도는 자기 증류를 통해 모델에 내재화됩니다.
그림 3: ERL의 전체 개요. 첫 번째 시도와 성찰, 두 번째 시도가 모두 강화학습으로 최적화되며, 특히 성공한 두 번째 시도는 자기 증류를 통해 모델에 내재화됩니다.
이 과정은 수학적으로 정책 경사(Policy Gradient)와 자기 증류(Self-Distillation)의 조합으로 볼 수 있습니다. 모델은 성찰 없이도 한 번에 정답($a_2$의 수준)에 도달할 수 있도록 지름길을 배우게 되는 것입니다. 이는 ‘생각의 사슬(CoT)’을 학습 데이터로 사용하는 것과 유사하지만, 환경과의 실제 상호작용을 통해 검증된 데이터만을 사용한다는 점에서 차별화됩니다.
4. 구현 및 실험 환경 (Implementation Details & Experiment Setup)
대상 모델 및 벤치마크
본 연구에서는 두 가지 오픈소스 모델을 베이스라인으로 삼았습니다:
- Qwen3-4B-Instruct-2507: 중소규모 모델에서의 효율성 검증.
- Olmo-3-7B-Instruct: 중간 규모 모델에서의 성능 확장성 확인.
실험은 다음 세 가지 난이도가 높은 환경에서 진행되었습니다:
- FrozenLake: 극도로 희소한 보상을 가진 그리드 월드 환경 (제어 능력 측정).
- Sokoban: 복잡한 계획 수립이 필요한 퍼즐 게임 (추론 및 계획 능력 측정).
- HotpotQA: 여러 단계를 거쳐야 정보를 찾을 수 있는 멀티홉 질의응답 (도구 활용 및 지식 통합 측정).
학습 파라미터
- 알고리즘: RLVR 기반의 강화학습 프레임워크.
- 보상 체계: 최종 결과의 정답 여부에 따른 바이너리 보상(0 또는 1).
- Internalization Loss: 성공한 $a_2$에 대한 Negative Log-Likelihood (NLL) 손실을 추가하여 $a_1$ 정책을 가이드.
5. 성능 평가 및 비교 (Comparative Analysis)
학습 효율성 및 수렴 속도
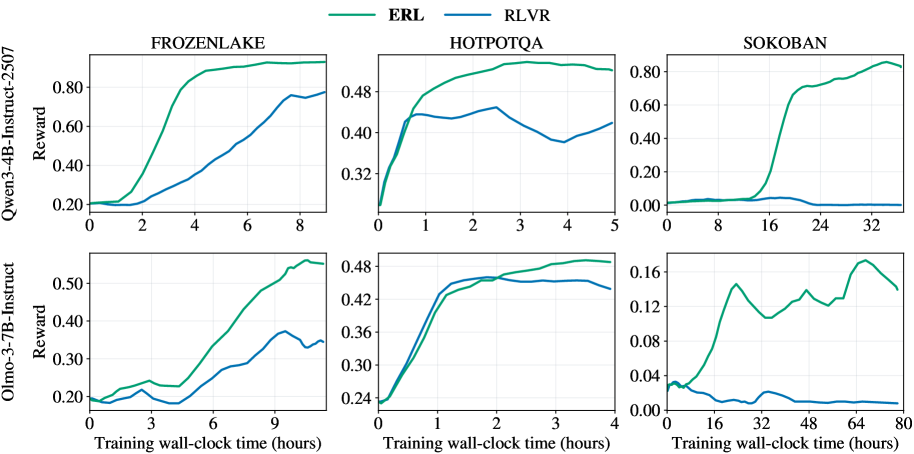 그림 4: 학습 시간 대비 검증 보상 궤적. ERL은 모든 작업에서 RLVR보다 압도적으로 빠른 수렴 속도와 높은 보상을 보여줍니다.
그림 4: 학습 시간 대비 검증 보상 궤적. ERL은 모든 작업에서 RLVR보다 압도적으로 빠른 수렴 속도와 높은 보상을 보여줍니다.
그림 4에서 알 수 있듯이, ERL은 학습 초기 단계부터 가파른 상승 곡선을 그립니다. 특히 FrozenLake와 같이 탐험이 어려운 환경에서 RLVR이 0 근처에서 머물 때, ERL은 이미 성찰을 통해 성공 경로를 찾아내기 시작합니다. 이는 ‘성찰’이 무작위 탐험을 ‘의도적인 시도’로 바꾸어 놓았기 때문입니다.
최종 성능 비교
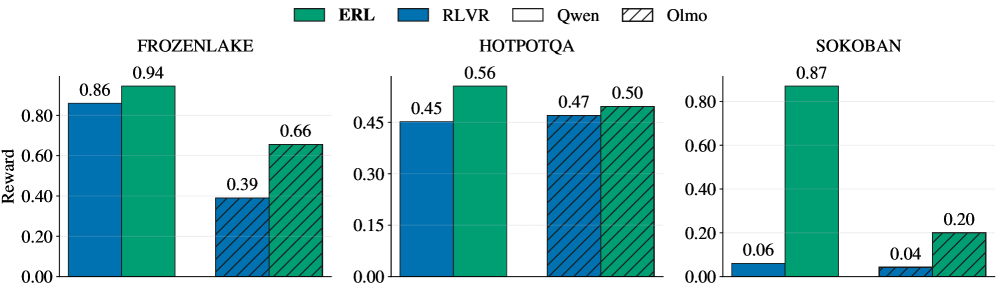 그림 5: 최종 평가 결과. ERL은 거의 모든 벤치마크에서 기존 RLVR 대비 유의미한 성능 향상을 달성했습니다.
그림 5: 최종 평가 결과. ERL은 거의 모든 벤치마크에서 기존 RLVR 대비 유의미한 성능 향상을 달성했습니다.
가장 눈에 띄는 결과는 Sokoban 환경에서의 81% 성능 향상입니다. 소코반은 한 번의 잘못된 움직임이 게임을 회복 불가능한 상태로 만들 수 있는 ‘치명적 실수’가 잦은 게임입니다. ERL은 모델이 실패 후 “내가 상자를 구석으로 밀어서 더 이상 움직일 수 없게 되었구나”라는 성찰을 하게 함으로써, 동일한 패턴의 실수를 비약적으로 줄였습니다.
6. 실제 적용 분야 및 글로벌 파급력 (Real-World Application & Impact)
ERL은 단순한 벤치마크 성능 향상을 넘어, 산업계에 다각도로 적용될 수 있는 잠재력을 가집니다.
6.1. 자율 코딩 에이전트 (Autonomous Coding Agents)
현재 코딩 어시스턴트(예: GitHub Copilot, Cursor)의 가장 큰 문제는 컴파일 에러나 런타임 에러가 발생했을 때 이를 수정하는 과정이 번거롭다는 점입니다. ERL을 적용하면, 모델이 테스트 코드를 돌려보고 실패 원인을 분석한 뒤, 스스로 코드를 고치는 과정을 학습할 수 있습니다. 이는 최종적으로 모델이 ‘한 번에’ 작동하는 코드를 짤 확률을 높여줍니다.
6.2. 로봇 공학 및 제어 (Robotics and Control)
물리적 환경에서의 로봇은 시행착오 비용이 매우 큽니다. ERL의 ‘내재화’ 방식은 시뮬레이션 환경에서 얻은 수많은 실패 경험을 압축하여 모델의 기본 정책에 심어줄 수 있습니다. 이는 로봇이 실제 현장에 투입되었을 때, 긴 생각(Inference latency) 없이도 즉각적이고 정확한 반응을 할 수 있게 돕습니다.
6.3. 의료 진단 및 법률 자문 (High-stakes Reasoning)
복잡한 진단 과정에서 모델이 내놓은 초기 가설이 틀렸을 때, 왜 틀렸는지를 성찰하고 수정하는 프로세스는 신뢰성을 높이는 핵심 요소입니다. ERL은 이러한 ‘전문가적 사고 과정’을 모델의 파라미터 자체에 학습시킬 수 있는 방법론적 토대를 제공합니다.
7. 한계점 및 기술적 비평 (Discussion: Limitations & Critical Critique)
고위 전문가로서 본 연구를 비판적으로 평가하자면, 몇 가지 해결해야 할 과제가 보입니다.
- 성찰의 질(Quality of Reflection) 문제: 만약 모델의 초기 성능이 너무 낮아 성찰 자체가 환각(Hallucination)에 가득 차 있다면 어떨까요? 잘못된 성찰에 기반한 ‘성공’은 모델에게 잘못된 인과관계를 학습시킬 위험이 있습니다. 즉, “운 좋게 성공해놓고 엉뚱한 이유로 성찰”하는 경우(False correlations)에 대한 견고성(Robustness) 검증이 더 필요합니다.
- 계산 복잡도의 증가: 학습 시점에 모델은 $a_1, r, a_2$라는 최소 3배 이상의 시퀀스를 생성해야 합니다. 이는 기존 RLVR 대비 학습 비용을 상당히 높입니다. 성능 향상폭이 81%라면 수용 가능하겠지만, 소규모 태스크에서는 가성비 문제가 대두될 수 있습니다.
- 내재화의 한계: 복잡한 성찰 과정을 통해 도달한 깊은 사고의 결론을 단 한 번의 시도($a_1$)에 완벽히 녹여낼 수 있는가에 대한 이론적 상한선(Theoretical upper bound)이 명확하지 않습니다. 일정 수준 이상의 복잡성을 가진 문제는 결국 추론 시점의 CoT가 여전히 필요할 것입니다.
8. 결론 (Conclusion & Insights)
Experiential Reinforcement Learning (ERL)은 언어 모델 학습에 있어 ‘경험의 질적 가공’이 얼마나 중요한지를 증명한 연구입니다. 단순히 더 많은 데이터를 붓거나 더 많은 컴퓨팅 자원을 사용하는 것이 아니라, 모델이 가진 언어적 능력을 활용해 자신의 행동을 스스로 감독(Self-supervision)하게 만든 설계는 매우 우아합니다.
이 기술은 특히 추론 비용은 최소화하면서 성능은 극대화해야 하는 엣지 디바이스용 AI나 실시간 반응이 필요한 에이전트 시스템에 강력한 솔루션이 될 것입니다. 앞으로의 연구는 성찰의 정확도를 높이는 방법과, 보다 적은 학습 비용으로 내재화 효율을 극대화하는 방향으로 전개될 것으로 보입니다. 우리는 이제 ‘많이 시도하는 모델’이 아닌, ‘제대로 반성하는 모델’이 승리하는 시대를 맞이하고 있습니다.
