[2026-02-25] 미드저니도 못하는 물리 법칙 이해? PhysicEdit: 이미지 편집의 판도를 바꾸다

📖 논문: From Statics to Dynamics: Physics-Aware Image Editing with Latent Transition Priors
🖥️ Github/Project: TBA
📅 발표일: 2026년 2월
✍️ 저자/기관: Anonymous
요즘 핫한 AI 이미지 편집기들, 써보셨나요? 텍스트로 명령만 내리면 마법처럼 이미지를 바꿔주죠. 하지만 ‘유리잔에 물을 채워줘’라거나 ‘금속 파이프를 구부려줘’ 같은 물리적 변화가 동반되는 명령을 내리면 어떨까요? 모양은 그럴싸한데, 굴절률이나 빛의 반사 같은 물리 법칙은 완전히 무시된 엉망진창인 결과물이 나오기 일쑤입니다.
도대체 왜 이런 일이 발생하는 걸까요? 오늘 소개할 PhysicEdit 논문은 바로 이 근본적인 질문에서 출발합니다.
💡 한 마디로? 기존 모델들이 이미지 편집을 ‘단순한 픽셀의 순간 이동(정적)’으로 취급했다면, PhysicEdit은 이를 ‘물리적 상태의 전이 과정(동적)’으로 재정의하여 현실 세계의 물리 법칙을 완벽히 모사하는 프레임워크입니다.
1. 대체 무엇이 다른가요? (What is it?)
기존 모델의 방식을 ‘순간 이동’에 비유해 볼게요. A라는 상태(빈 잔)에서 B라는 상태(물이 찬 잔)로 이동할 때, 중간 과정은 완전히 블랙박스에 맡긴 채 결과만 강제로 끼워 맞춥니다. 인과관계가 없으니 물리적 오류(Hallucination)가 발생할 수밖에 없죠.
반면 PhysicEdit은 ‘직접 걸어가는 법’을 학습합니다. 이를 위해 연구진은 비디오를 활용했습니다. 동영상의 프레임 변화를 통해 ‘물이 차오르는 과정’ 자체를 AI에게 가르친 것이죠.
🔹 기존 방식의 한계: A상태에서 B상태로 이산적(Discrete) 점프 ➡️ 물리 법칙 무시 🔹 PhysicEdit의 핵심: 비디오 데이터셋(PhysicTran38K)을 통해 중간의 동역학(Dynamics) 학습 ✅ 결과: 빛의 굴절, 재질의 변형 등 복잡한 물리적 인과관계를 이해하는 이미지 편집 달성
 솔직히 이 접근법은 정말 영리하네요. 기존 모델들이 보여주는 환각(Hallucination)과 물리적 상태 전이의 차이를 극명하게 보여주는 장표입니다. 물리 엔진 없이 시각 데이터만으로 이걸 구현하다니 놀랍습니다.
솔직히 이 접근법은 정말 영리하네요. 기존 모델들이 보여주는 환각(Hallucination)과 물리적 상태 전이의 차이를 극명하게 보여주는 장표입니다. 물리 엔진 없이 시각 데이터만으로 이걸 구현하다니 놀랍습니다.
2. 성능 비교와 실무적 가치 (Key Features & Comparisons)
그렇다면 실제 성능은 어떨까요? 논문에 따르면 기존 오픈소스 SOTA였던 Qwen-Image-Edit과 비교해 압도적인 우위를 보입니다.
| 비교 항목 | 기존 모델 (Qwen-Image-Edit 등) | PhysicEdit (본 논문) | SOTA 상용 모델 (Proprietary) |
|---|---|---|---|
| 물리적 사실주의 | 낮음 (의미적 변환에 치중) | 매우 높음 (+5.9%) | 높음 |
| 지식 기반 편집 | 보통 | 우수 (+10.1%) | 매우 우수 |
| 접근 방식 | Discrete mapping (이산 매핑) | Continuous dynamics (연속적 동역학) | Black box |
| 오픈소스 | 지원 | 지원 (오픈소스 SOTA 달성) | 미지원 |
왜 이 결과가 중요할까요? 실무에서 상품 이미지를 합성하거나 시각 효과(VFX) 초안을 잡을 때, 물리 법칙이 깨지면 결국 디자이너가 포토샵으로 한 땀 한 땀 리터칭을 해야 합니다. 시간과 비용의 낭비죠. PhysicEdit은 이 수작업 비용을 획기적으로 줄일 수 있는 가능성을 보여줍니다. 오픈소스 모델임에도 불구하고 폐쇄형 상용 모델(Proprietary models)과 경쟁할 수 있는 수준까지 올라왔다는 점이 특히 고무적입니다.
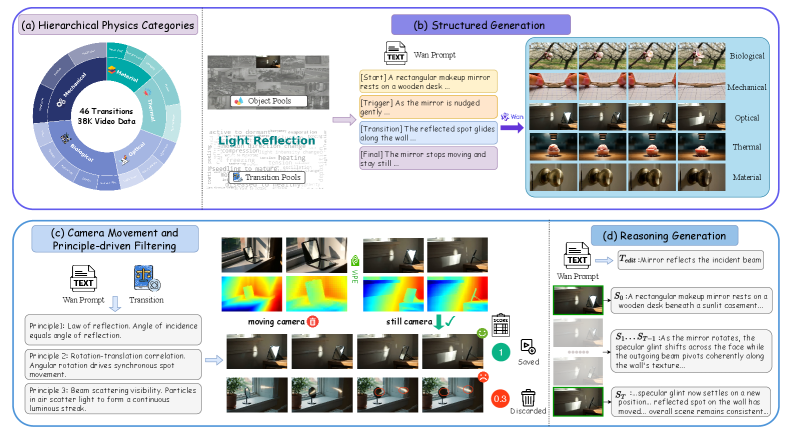 데이터셋 구축 파이프라인입니다. Wan2.2로 비디오를 생성하고 GPT-5-mini로 깐깐하게 검증한 뒤 Qwen2.5-VL로 주석을 다는 과정은 데이터 품질에 얼마나 집착했는지 보여줍니다. 다만, 이 정도 규모의 구축 비용은 스타트업 입장에선 꽤 부담스러울 수 있겠네요.
데이터셋 구축 파이프라인입니다. Wan2.2로 비디오를 생성하고 GPT-5-mini로 깐깐하게 검증한 뒤 Qwen2.5-VL로 주석을 다는 과정은 데이터 품질에 얼마나 집착했는지 보여줍니다. 다만, 이 정도 규모의 구축 비용은 스타트업 입장에선 꽤 부담스러울 수 있겠네요.
3. 기술 톺아보기 (Technical Deep Dive)
기술적으로 가장 흥미로운 부분은 시각-텍스트 이중 사고 메커니즘(textual-visual dual-thinking mechanism)입니다. 단순히 텍스트 프롬프트만 디퓨전(Diffusion) 모델에 밀어 넣는 게 아닙니다.
- 동결된 Qwen2.5-VL이 먼저 물리적 근거에 기반한 텍스트 추론(Reasoning)을 수행합니다.
- 학습 가능한 Transition Queries(전이 쿼리)가 중간 단계의 시각적 가이드라인을 동적으로 제공합니다.
- 이 두 가지가 결합되어 디퓨전 백본의 조건(Condition)으로 작용합니다.
이를 코드로 간단히 유추해보면 아래와 같은 흐름이 될 것입니다.
1
2
3
4
5
6
7
8
9
10
def physic_edit_inference(image, instruction):
# 1. Qwen2.5-VL을 통한 물리적 상태 변화 추론
physical_reasoning = qwen2_5_vl.reason(image, instruction)
# 2. 전이 쿼리를 통해 타임스텝에 맞는 시각적 가이드라인(Priors) 추출
transition_condition = get_transition_queries(image, physical_reasoning)
# 3. 디퓨전 백본이 물리 법칙이 반영된 최종 이미지 생성
edited_image = diffusion_backbone.generate(image, transition_condition)
return edited_image
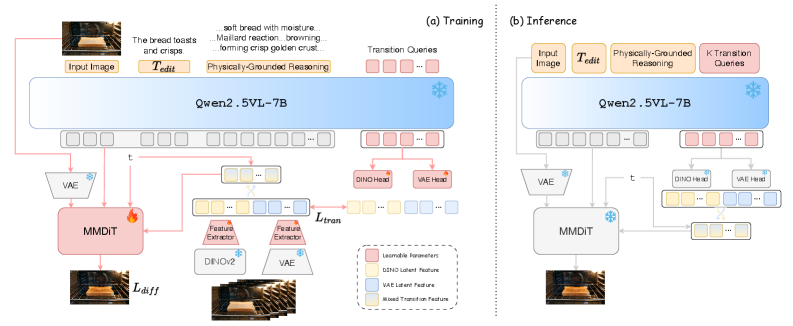 훈련 과정(위)에서 비디오의 중간 프레임을 사용해 물리적 전이 사전 지식(Priors)을 증류(Distill)하는 아이디어가 이 논문의 핵심 백미입니다. ‘정적’인 이미지를 ‘동적’ 비디오로 풀었다는 점에 박수를 쳐주고 싶네요.
훈련 과정(위)에서 비디오의 중간 프레임을 사용해 물리적 전이 사전 지식(Priors)을 증류(Distill)하는 아이디어가 이 논문의 핵심 백미입니다. ‘정적’인 이미지를 ‘동적’ 비디오로 풀었다는 점에 박수를 쳐주고 싶네요.
🔥 에디터의 생각 (Editor’s Verdict)
장점 (Pros): 비디오 데이터를 활용해 정적인 이미지 편집의 물리적 한계를 돌파했다는 발상의 전환이 돋보입니다. 오픈소스 환경에서 이 정도의 물리적 정합성을 달성했다는 것은 관련 커뮤니티에 엄청난 기여입니다.
아쉬운 점 (Cons): 아키텍처 자체가 꽤 무겁습니다. 추론 과정에서 거대한 MLLM(Qwen2.5-VL)을 거쳐야 하기 때문에, 실시간 처리가 필요한 모바일 서비스나 빠른 응답이 생명인 프로덕션 환경(Production)에 바로 적용하기에는 지연 시간(Latency) 문제가 발목을 잡을 것으로 보입니다. 추후 v2에서는 경량화 모델에 대한 고민이 필요해 보입니다.
💡 최종 평가: 4.5 / 5.0 “이미지 편집 AI를 다루는 엔지니어와 연구자라면 반드시 읽어봐야 할 올해의 필독 논문입니다. 오픈소스 진영의 반격은 이제부터 시작이네요!”
