[2026-03-25] 멀티모달 LLM이 FPS 게임에서 박살나는 이유: GameplayQA로 파헤치는 3D 에이전트 인지 한계와 아키텍처

Link: arXiv:2603.24329 Date: 2026-03-29
요즘 로보틱스나 3D 가상 환경에 LLaVA나 GPT-4V를 통째로 얹어서 자율 에이전트(Autonomous Agent)를 만드는 게 유행이죠. 데모 영상 보면 그럴싸합니다. “사과 집어줘” 하면 잘 집으니까요. 그런데 조금만 환경이 동적으로 변하거나 다른 에이전트가 개입하면 어떨까요? 모델은 순식간에 멍청해집니다.
자기가 한 행동인지 남이 한 행동인지 구분도 못 하고, 빠르게 변하는 FPS 게임 같은 환경에서는 프레임의 맥락을 완전히 놓쳐버립니다. 우리가 프로덕션 레벨에서 필요한 건 정지된 이미지에서 “고양이가 있네”를 맞추는 능력이 아닙니다. 여러 객체가 동시에 움직이는 시끄러운 환경에서 ‘누가, 언제, 무엇을’ 했는지 밀도 있게 추론하는 능력이죠. GameplayQA는 바로 이 지독한 Pain point를 정조준합니다.
TL;DR: 시점을 1인칭(POV)으로 고정하고 자아(Self), 타자(Other), 세계(World)를 초당 1.22개의 라벨로 쪼개어 MLLM의 동적 비전 인지 능력을 평가하는 극악의 벤치마크 프레임워크입니다.
⚙️ 픽셀 뭉치를 3D 공간으로 연성하는 파이프라인 해부
솔직히 기존 데이터셋들은 라벨링이 너무 성깁니다. 비디오 하나 던져주고 두리뭉실한 질문 하나 툭 던지는 식이죠. 모델 입장에서는 그냥 프레임 몇 개 샘플링해서 때려 맞추면 그만입니다. 하지만 GameplayQA는 아예 접근법을 바꿨습니다. 영상을 3차원으로 쪼개고, 그 위에 환각을 유도하는 ‘오답(Distractor)’ 지뢰를 촘촘하게 깔아뒀습니다.

- [그림 설명] 자아(Self), 타인(Other), 세계(World)라는 3원적 관점으로 시야를 분리합니다. 에이전트가 누구의 행동인지 정확히 귀인(Attribution)하도록 강제하는 핵심 구조죠.
가장 흥미로운 부분은 데이터 플로우입니다. 멀티모달 모델의 어텐션 메커니즘을 뜯어보면 현재의 Vision Transformer(ViT) 기반 인코더들이 왜 실패하는지 명확해집니다. 이들은 프레임 간의 미세한 시간차(Temporal Delta)를 포착하는 데 특화되어 있지 않아요. 단순히 공간적(Spatial) 피처만 뽑아서 LLM에 던져주거든요. 그래서 GameplayQA는 초당 1.22개의 고밀도 라벨링을 통해 시간적 추론 능력을 극도로 쥐어짭니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 기존 LLaVA 스타일의 멍청한 비전 인코딩 방식 (환각의 주범)
def process_video_dumb(video_frames):
# 프레임별로 공간적 특징만 퉁쳐서 추출하고 시간적 순서는 LLM의 상상에 맡김
features = vit_encoder(video_frames)
return llm_generate(features, "What happened?")
# GameplayQA를 통과하기 위해 요구되는 3D/Temporal 인지 아키텍처 (Mock)
class POV_Synced_Agent(nn.Module):
def __init__(self):
self.spatial_encoder = ViT_3D_Encoder()
# Self, Other, World를 분리해서 처리하는 전문가 라우팅 모델 도입 필수
self.temporal_router = MoE_Router(experts=["Self", "Other", "World"])
def forward(self, sync_frames):
# 1. 1인칭 시점의 동기화된 다중 뷰 인코딩
spatial_feat = self.spatial_encoder(sync_frames)
# 2. 주체별로 어텐션을 강제 분리 (여기서 Temporal Distractor 필터링)
entity_tokens = self.temporal_router(spatial_feat)
# 3. 초당 1.22개의 고밀도 상태 변화 추론
return dense_state_decoder(entity_tokens)
코드에서 보이듯, 주체를 명확히 분리하는(Routing) 아키텍처가 없다면 모델은 대충 프레임에 총이 보인다고 “총을 쏘고 있다”고 퉁치게 됩니다. 단순한 객체 인식을 넘어 시간적 선후 관계를 추론해야만 정답을 맞출 수 있도록 네거티브 라벨을 교묘하게 섞어버린 것이죠.
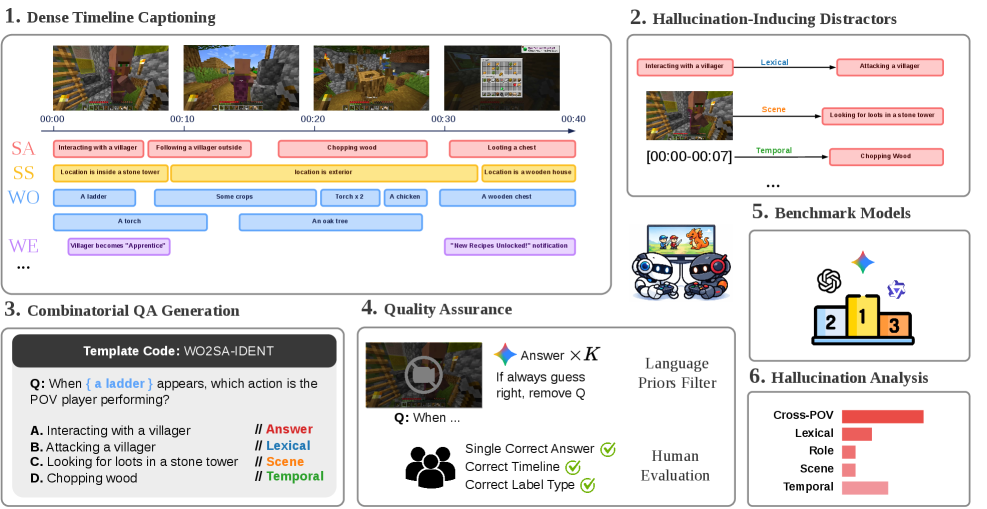
- [그림 설명] 원본 비디오에서 다중 트랙 캡셔닝을 거쳐 네거티브 라벨을 섞고 QA를 생성하는 전체 파이프라인 데이터 플로우입니다. 라벨링 엔지니어들의 피와 땀이 느껴지는 구간입니다.
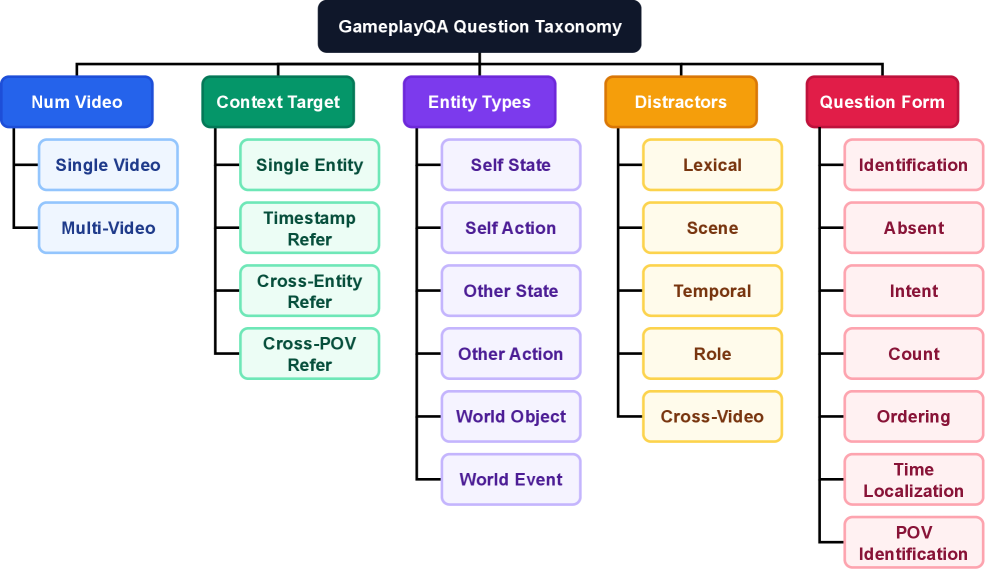
- [그림 설명] 인지 복잡도를 L1(단순 인지)부터 L3(교차 비디오 추론)까지 15개 태스크로 나눈 분류 체계입니다. 모델이 어디서 병목을 겪는지 정확히 타겟팅합니다.
⚔️ 기존 스택 vs 새로운 패러다임: 진짜 갈아탈 가치가 있나?
우리가 쓰는 SOTA 멀티모달 모델들이 진짜로 똑똑할까요? 벤치마크 자체가 모델의 환각을 숨겨주는 역할을 하고 있었다면 믿으시겠습니까? 표를 하나 보시죠. 이 숫자들은 여러분의 인프라 비용과 디버깅 시간에 직결됩니다.
| 비교 지표 | 기존 VideoQA (e.g., Ego4D, MSRVTT) | GameplayQA (New) | 💡 Dev Impact (개발자 관점) |
|---|---|---|---|
| 주체 구분 (Entity Attribution) | 단일 주체 / 배경 위주 | Self, Other, World 완전 분리 | 멀티 에이전트 상호작용 로직 구현 시 치명적인 상태 버그 방지 |
| 라벨 밀도 (Label Density) | 클립당 1~2개 듬성듬성 | 초당 1.22개의 초고밀도 | 드론이나 로봇 등 빠른 상태 변화 환경에 배포 가능한지 검증 가능 |
| 디스트랙터 (Hallucination Trap) | 거의 없음 (운 좋으면 맞춤) | 정교한 오답 (Taxonomy) 떡칠 | 프로덕션 환경에서 모델이 헛소리(Hallucination)하는 빈도 정확히 예측 |
| 다중 뷰 동기화 (Multi-Video) | 지원 안 함 | L3 레벨 동기화 추론 | 다중 CCTV나 로봇 군집 제어 시 발생하는 VRAM 컨텍스트 병목 확인 |
기존 벤치마크로 평가한 모델을 실무에 배포하면, 모델은 ‘팀원이 수류탄을 던지는 것’과 ‘적이 총을 쏘는 것’을 섞어서 끔찍한 환각을 만들어냅니다. GameplayQA는 이런 엉성한 어텐션(Attention) 분배를 절대 용납하지 않습니다.
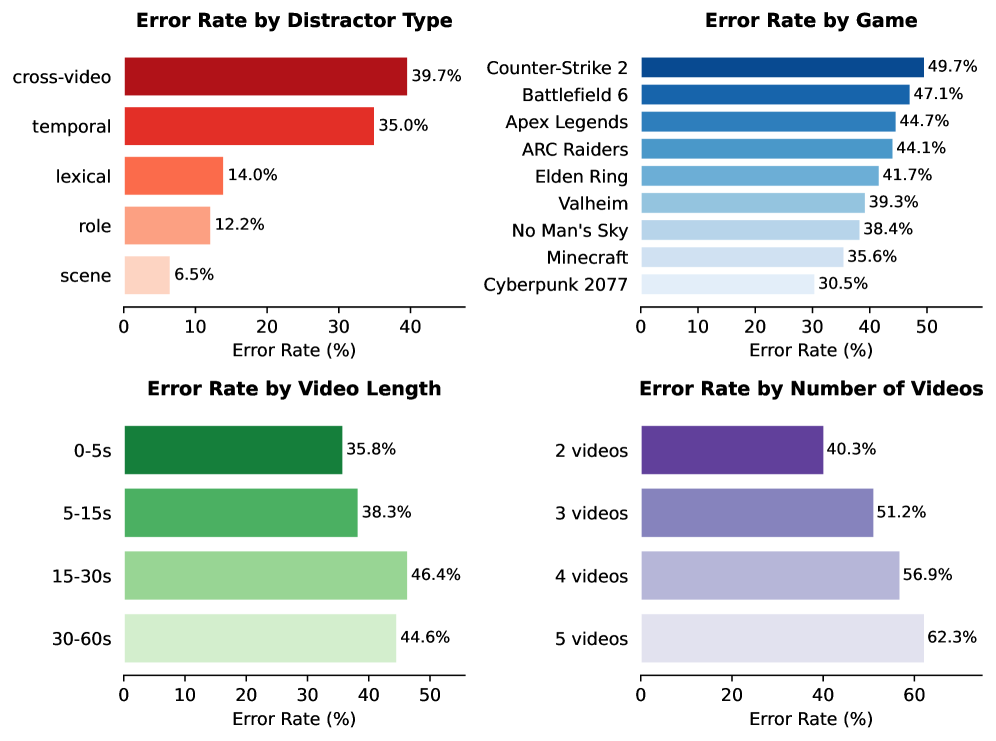
- [그림 설명] 현재 최신 MLLM들이 교차 비디오(Cross-video)와 시간적 디스트랙터(Temporal) 앞에서 처참하게 무너지는 에러율 지표입니다. 빠르고 긴 영상일수록 모델은 완전히 붕괴합니다.
🚀 내일 당장 프로덕션에 도입한다면? (Edge Cases)
좋습니다. 이론은 훌륭해요. 그렇다면 이 프레임워크나 평가 방식을 내일 당장 우리 서비스에 도입하면 어떤 일이 벌어질까요?
1. 다중 드론 군집 감시 시스템 (Multi-Agent Surveillance) 드론 4대가 각각 다른 각도에서 촬영한 동기화된 POV 영상을 MLLM에 밀어넣는다고 가정해봅시다. GameplayQA의 L3(Cross-video) 평가 기준을 빌리면, 모델은 4개의 시점을 동시에 분석해야 합니다. 🔥 병목 현상: 영상 4개를 30fps로 동기화해서 토큰화하면 Context Window가 순식간에 터져버립니다. LLaVA-1.5 기준으로 프레임당 약 576토큰인데, 1분 분량의 4채널 영상이면 수백만 토큰을 가뿐히 넘깁니다. 프레임 샘플링 비율을 낮추면? 이번엔 초당 1.22개의 액션을 놓쳐서 시스템이 위협을 감지하지 못하겠죠. VRAM과 지연 시간(Latency) 사이의 피말리는 트레이드오프를 겪게 될 겁니다.
2. 자동화된 게임 QA 및 AI 플레이어 (Automated Game Testing) QA 테스터 대신 MLLM 에이전트가 게임을 플레이하며 버그 리포트를 작성하는 시나리오입니다. 🔥 병목 현상: 빠른 화면 전환(Motion Blur)이 발생하는 FPS 게임에서 현재의 MLLM은 시각 정보를 거의 소화하지 못합니다. 해상도를 올리면 API 비용이 감당 안 되고, 낮추면 총알이 날아오는 걸 인지하지 못하죠. 게다가 프레임이 1프레임만 밀려도(Drift) 시간적 선후 관계를 묻는 프롬프트에서 모델이 오답을 뱉어내기 시작합니다.

- [그림 설명] L1부터 L3까지의 실제 QA 예시입니다. 인간에게는 직관적이지만 모델에게는 어텐션 헤드를 찢어놓고 VRAM을 터뜨리는 주범이 됩니다.
🧐 Tech Lead’s Honest Verdict
장점 (Pros): 단순한 VQA를 넘어서, 에이전트가 3D 공간에서 “어떻게 행동을 이해하고 귀인(Attribution)하는가”를 벤치마크하는 명확한 기준을 세웠습니다. 디스트랙터(Distractor) 텍소노미 설계는 정말 천재적입니다. 모델이 얼마나 멍청하게 환각을 일으키는지 발가벗겨주거든요. 멀티 에이전트 스택을 구축 중이라면 이 논문의 분류 체계를 설계도구로 써먹어도 좋습니다.
단점 (Cons): 실무자 입장에서 한숨이 나오는 부분은 비용입니다. 초당 1.22개의 라벨을, 그것도 타임싱크를 맞춰서 수동에 가깝게 어노테이션하는 건 미친 짓입니다. 여러분의 도메인(예: 공장 자동화, 로보틱스)에 이 프레임워크를 그대로 파인튜닝용으로 적용하려면 라벨링 비용 파산에 직면할 수도 있습니다. 철저히 ‘평가(Eval)’ 용도로만 접근해야 합니다.
최종 판정 (Final Verdict): “3D 에이전트나 물리적 AI를 개발한다면 무조건 벤치마크 파이프라인에 이 놈을 포함시킬 것.” 단순 챗봇이 아니라 현실 세계나 3D 환경과 상호작용하는 모델을 만들고 계신가요? 기존 벤치마크 점수 높다고 데모 찍고 좋아하지 마시고, 모델을 이 극악무도한 GameplayQA에 올려보세요. 진짜 실력이 탄로 날 테니까요. 프로덕션 배포 전 필수 관문으로 강력히 추천합니다.
