[2026-03-19] 포인트 클라우드 노가다 끝. 비디오 생성 모델에서 3D 공간 지각력을 날먹하는 VEGA-3D 아키텍처 해부

[Metadata]
- Paper ID: 2603.19235
- Arxiv Link: Generation Models Know Space: Unleashing Implicit 3D Priors for Scene Understanding
- Github: https://github.com/H-EmbodVis/VEGA-3D
멀티모달 LLM(MLLM)이 아무리 똑똑해졌다고 한들, 물리적 세계 앞에서는 여전히 심각한 방향치입니다. 이미지 안의 객체가 무엇인지는 기가 막히게 맞추지만, “저 컵이 키보드보다 앞에 있나? 로봇 팔이 닿을 수 있는 거리인가?” 같은 공간 지각 능력을 물어보면 바보가 되죠. 그래서 우리는 지금까지 라이다(LiDAR)를 달고, 포인트 클라우드를 찍어내고, 3D 바운딩 박스를 수작업으로 깎는 고통스러운 라벨링 노가다를 반복해 왔습니다.
하지만 생각해보면 이럴 필요가 없었어요. 영상 생성 AI(Sora 등)가 프레임 사이에서 자연스러운 움직임을 만들어내려면, 이미 모델 내부적으로 3D 물리 법칙과 공간 구조를 완벽하게 이해하고 있어야만 하니까요. 이번에 공개된 VEGA-3D는 바로 이 지점을 파고듭니다. 거대한 비디오 디퓨전 모델을 일종의 ‘잠재 세계 시뮬레이터(Latent World Simulator)’로 취급하고, 그 안에서 3D 공간 지각력을 날로 먹겠다는 발칙한 접근이죠.
TL;DR: 비디오 디퓨전 모델의 중간 노이즈 레이어에서 3D 구조적 사전 지식(Prior)을 추출해 MLLM에 꽂아 넣는 플러그앤플레이 프레임워크. 단, 백본 두 개를 굴려야 하니 VRAM 청구서는 미리 각오해야 합니다.
⚙️ 비디오 모델의 뇌수를 뽑아내는 ‘잠재 세계 시뮬레이터’ 파이프라인
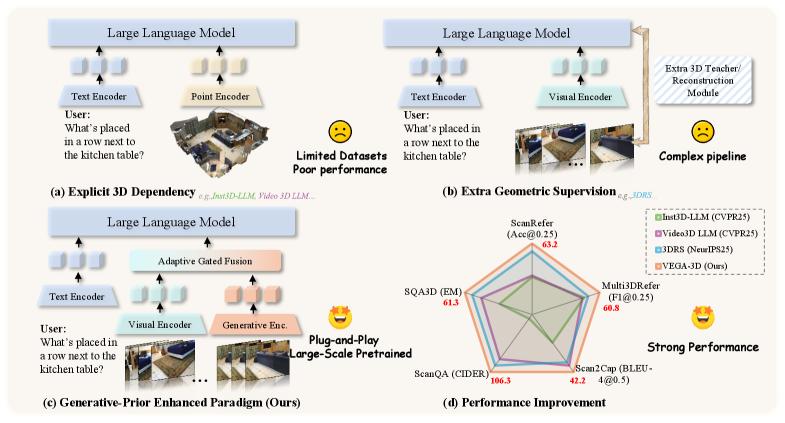 Figure 1: 명시적인 3D 데이터를 떠먹여야 했던 기존 방식(a, b)과 달리, 비디오 생성 모델에서 암시적 3D 지식을 추출해버리는 VEGA-3D(c)의 패러다임 전환을 보여줍니다.
Figure 1: 명시적인 3D 데이터를 떠먹여야 했던 기존 방식(a, b)과 달리, 비디오 생성 모델에서 암시적 3D 지식을 추출해버리는 VEGA-3D(c)의 패러다임 전환을 보여줍니다.
VEGA-3D의 아키텍처는 놀라울 정도로 직관적이고 뻔뻔합니다. 기존의 무거운 3D 인코더나 뎁스 카메라 데이터를 전부 치워버립니다. 대신 이미 사전 학습이 끝난 거대한 비디오 생성 모델(Frozen Video Generation Model)을 파이프라인 중간에 떡하니 올려놓죠.
🔹 Step 1: 잠재 세계 시뮬레이션 (Implicit 3D Prior) 비디오 디퓨전 모델은 시간에 따라 변하는 픽셀을 예측하기 위해 필연적으로 ‘객체의 깊이’와 ‘카메라 앵글’을 잠재 공간(Latent Space)에 인코딩합니다. VEGA-3D는 이 비디오 모델에 입력 이미지를 던져주고, 영상 생성 과정의 중간 노이즈 레벨에서 시공간 특징(spatiotemporal features)을 강제로 추출해 냅니다.
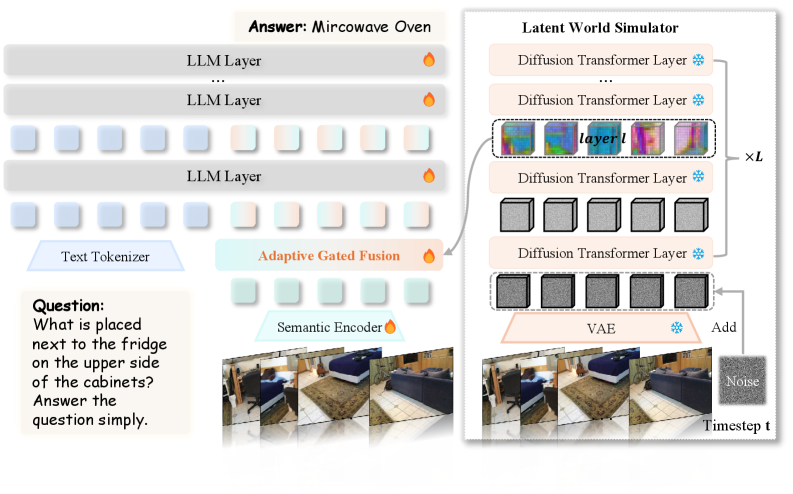 Figure 4: 얼어있는 비디오 생성 모델(위쪽)에서 3D 피처를 뽑아내고, 이를 아래쪽 시맨틱 스트림과 동적으로 융합하는 전체 데이터 플로우입니다.
Figure 4: 얼어있는 비디오 생성 모델(위쪽)에서 3D 피처를 뽑아내고, 이를 아래쪽 시맨틱 스트림과 동적으로 융합하는 전체 데이터 플로우입니다.
🔹 Step 2: 적응형 게이트 융합 (Adaptive Gated Fusion) 이제 문제는 “이 거대하고 낯선 3D 피처 덩어리를 어떻게 MLLM의 언어 토큰과 섞을 것인가?” 입니다. 무식하게 Concat 해버리면 모델이 원래 가지고 있던 의미론적(Semantic) 추론 능력이 박살 나거든요. 여기서 그들이 꺼내든 카드가 바로 토큰 단위의 적응형 게이트 융합(Adaptive Gated Fusion)입니다.
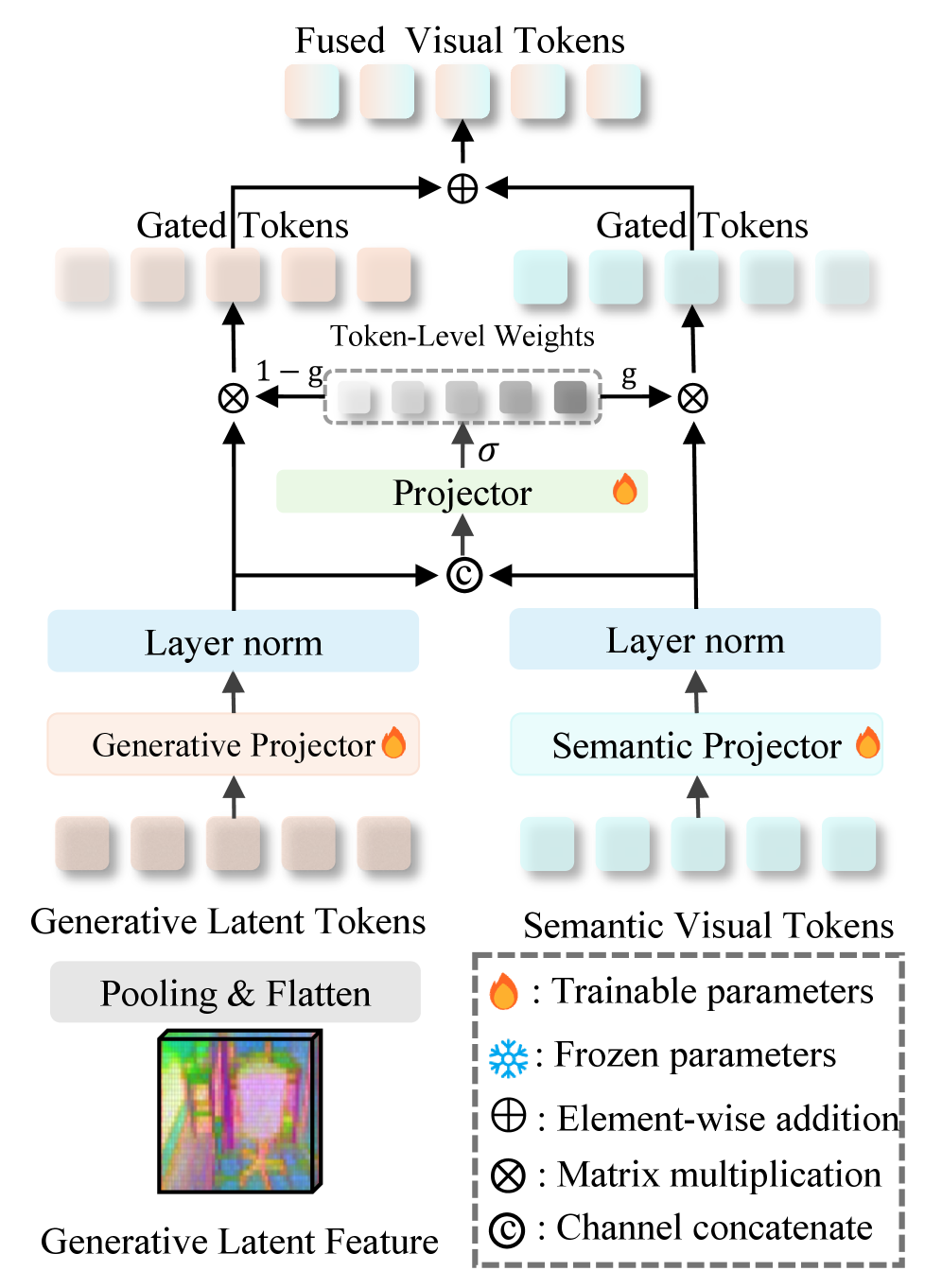 Figure 5: 시맨틱 토큰과 3D 사전 지식 토큰이 만나는 교차점. 토큰 단위로 게이트를 열고 닫아 정보의 과적합을 막는 핵심 레이어입니다.
Figure 5: 시맨틱 토큰과 3D 사전 지식 토큰이 만나는 교차점. 토큰 단위로 게이트를 열고 닫아 정보의 과적합을 막는 핵심 레이어입니다.
동작 원리는 코드로 보면 훨씬 명확합니다. 아래는 제가 논문의 수식을 바탕으로 대략적인 데이터 흐름을 재구성해 본 PyTorch 스타일의 의사 코드(Pseudo Code)입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# [Mock Code] VEGA-3D의 핵심 융합 로직
class AdaptiveGatedFusion(nn.Module):
def __init__(self, hidden_dim):
super().__init__()
self.spatial_proj = nn.Linear(video_dim, hidden_dim)
# 정보를 얼마나 섞을지 결정하는 게이트 네트워크
self.gate_network = nn.Sequential(
nn.Linear(hidden_dim * 2, hidden_dim),
nn.Sigmoid()
)
def forward(self, semantic_tokens, video_latents):
# 1. 비디오 모델에서 뽑은 3D 피처를 투영
spatial_tokens = self.spatial_proj(video_latents)
# 2. 시맨틱 피처와 3D 피처를 기반으로 게이트 값(0~1) 계산
concat_features = torch.cat([semantic_tokens, spatial_tokens], dim=-1)
gate_values = self.gate_network(concat_features)
# 3. 토큰 단위로 필요한 만큼만 3D 지식을 주입!
fused_tokens = semantic_tokens + gate_values * spatial_tokens
return fused_tokens
이렇게 하면 MLLM은 텍스트를 읽다가 “오른쪽에 있는 컵” 같은 공간 정보가 필요할 때만 비디오 모델이 던져준 3D 피처를 쏙쏙 빼먹을 수 있습니다.
⚔️ 명시적 3D 노가다 vs 암시적 3D 무임승차: 진짜 쓸만한가?
이쯤 되면 기존의 3D 비전 파이프라인과 비교해 인프라 레벨에서 어떤 트레이드오프가 있는지 따져봐야 합니다. 세상에 공짜는 없으니까요.
| 비교 항목 | 전통적 3D MLLM (예: LLaVA-3D) | VEGA-3D (본 프레임워크) |
|---|---|---|
| 3D 지식 출처 | 포인트 클라우드, Depth Map, 3D Bounding Box | 사전 학습된 비디오 확산 모델의 잠재 공간 |
| 데이터 구축 비용 | 최악 (고가의 LiDAR 장비 및 노가다 라벨링 필수) | 무료 (인터넷의 방대한 영상 데이터에 이미 녹아있음) |
| 일반화 성능(OOD) | 학습 데이터 셋 범위를 벗어나면 급격히 바보가 됨 | 제로샷(Zero-shot)에 강함. 생성 모델의 추론 능력 상속 |
| 런타임 메모리(VRAM) | 중간 (별도의 가벼운 3D 인코더만 띄우면 됨) | 최악 (MLLM과 동결된 디퓨전 모델을 동시에 메모리에 올려야 함) |
| 파이프라인 복잡도 | 전처리/후처리 지옥 (Mesh 변환 등) | 플러그 앤 플레이 (추출기만 꽂으면 끝) |
표를 보면 아시겠지만, 이 방식은 전형적인 “데이터셋 구축 비용을 컴퓨팅 자원(VRAM)으로 퉁치는” 전략입니다. 라벨링 팀을 꾸리는 대신, 차라리 A100 GPU를 몇 대 더 사겠다는 개발자 친화적(?) 마인드죠.
 Figure 2: 기존 방식(Baseline)은 객체의 공간 위치를 헷갈려 하지만, VEGA-3D는 생성 모델의 공간 일관성(PCA 맵 참조)을 바탕으로 정확한 좌표에 어텐션을 찍습니다.
Figure 2: 기존 방식(Baseline)은 객체의 공간 위치를 헷갈려 하지만, VEGA-3D는 생성 모델의 공간 일관성(PCA 맵 참조)을 바탕으로 정확한 좌표에 어텐션을 찍습니다.
🚀 내일 당장 프로덕션에 도입한다면?
실제 프로덕션에서 이 프레임워크가 빛을 발할 수 있는, 혹은 한계에 부딪힐 두 가지 엣지 케이스를 상상해 봅시다.
1. 로봇 팔 제어 (Embodied AI) 물류 창고에 로봇 팔을 배치해야 하는데 3D 스캐너나 고가의 카메라를 달 예산이 없다고 칩시다. 싼 맛에 RGB 웹캠 하나만 달아두고 VEGA-3D를 물립니다. 로봇은 들어오는 평면 이미지를 비디오 모델의 잠재 공간에 태워, 눈앞에 있는 박스들의 깊이감과 가려진 영역(Occlusion)을 환각(Hallucinate)해 냅니다. 라이다 없이도 피킹 작업을 수행할 수 있죠. 단점은 지연 시간(Latency)입니다. 디퓨전 파이프라인을 거치기 때문에 60fps 실시간 제어는 꿈도 꾸지 마세요. 무거운 GPU 서버로 API 통신을 해야 하니 딜레이 튜닝에 골머리를 앓게 될 겁니다.
2. 자율주행 블랙박스 엣지 케이스 분석 수천 시간 분량의 테슬라나 웨이모 주행 영상에서 특정 공간적 위협(예: “트럭 뒤에 숨어있다가 튀어나오는 보행자”)을 텍스트로 검색하고 싶을 때 완벽합니다. 이미 녹화된 영상이므로 실시간 추론 압박도 없고, 거대한 서버에서 배치(Batch)로 돌리면 됩니다. 기존 2D 기반 MLLM은 원근감을 무시해서 엉뚱한 결과를 뱉지만, VEGA-3D는 비디오 모델의 공간 지각력 덕분에 정확하게 찾아낼 겁니다.
🧐 Tech Lead’s Honest Verdict
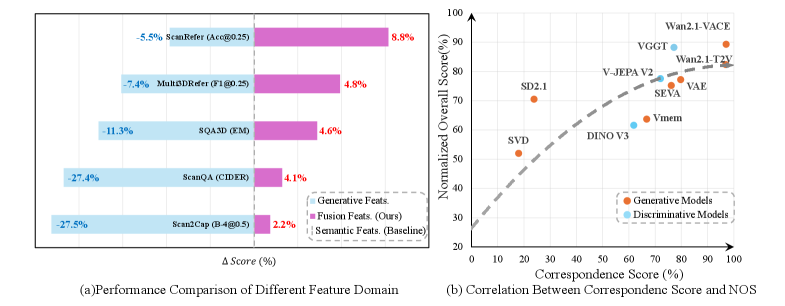 Figure 3: 제너러티브 3D 피처를 섞었을 때(Fuse) 성능이 무조건적으로 향상되는 것을 보여주는 지표. 이 모델의 핵심 가설이 맞았다는 증거입니다.
Figure 3: 제너러티브 3D 피처를 섞었을 때(Fuse) 성능이 무조건적으로 향상되는 것을 보여주는 지표. 이 모델의 핵심 가설이 맞았다는 증거입니다.
장점 (Pros):
- 3D 라벨링이라는 최악의 병목을 우회하는 천재적인 발상입니다. 비디오 생성 모델들이 앞으로 Sora 급으로 발전하면, VEGA-3D의 성능도 아무런 코드 수정 없이 자동으로 스케일업 될 겁니다.
- 기존 MLLM 파이프라인을 거의 부수지 않고, 플러그인 형태로 갖다 붙일 수 있는 모듈화가 훌륭합니다.
단점 (Cons):
- 무겁습니다. 진짜 끔찍하게 무겁습니다. 논문을 보면 알 수 있듯, 추론 타임에도 Video Diffusion Model을 띄워놔야 합니다. 엣지 디바이스(Jetson 등)에 올리려는 분들은 당장 뒤로 가기를 누르세요.
- 추출된 3D 특징이 말 그대로 ‘암시적(Implicit)’이므로,
x: 12.5cm, y: 5.2cm같은 정밀한 수치적 거리 측정이 필요한 도메인에는 부적합합니다.
최종 판정 (Final Verdict): 서버 환경이라면 당장 클론 (Clone Immediately) 만약 당신이 로봇 제어나 3D 씬 이해(Scene Understanding) 프로젝트를 진행 중인데 3D 데이터 수집에 지쳐있다면, 이 레포지토리는 구세주가 될 수 있습니다. 엣지 디바이스 배포가 목적이라면 경량화 버전이 나올 때까지 숨 참으시고요. 어쨌든 비디오 생성 AI의 잠재력을 단순히 ‘영상 만들기’에서 ‘세상을 이해하는 엔진’으로 확장했다는 점에서, 올해 본 논문 중 가장 해커스러운 접근이었습니다.
