[2026-03-17] VLM 환각 탈출구: HopChain, 단일 홉의 한계를 깨는 멀티홉 RLVR 합성 파이프라인 해부

VLM 환각 탈출구: HopChain, 단일 홉의 한계를 깨는 멀티홉 RLVR 합성 파이프라인 해부
Metadata
- Paper ID: 2603.17024
- Authors: HopChain Research Team
- Date: March 2026
- Tags: #VLM #RLVR #HopChain #DataSynthesis #Qwen
솔직해집시다. 최근 나오는 VLM(Vision-Language Model)들 데모 영상 보면 기가 막히죠. 하지만 프로덕션 환경에서 조금만 복잡한 추론을 요구하면 어떨까요? “이미지 우측 하단에 있는 파란색 상자 안에 든 물건들 중, 가장 무거운 것의 재질은 뭐야?” 같은 질문을 던지면 여지없이 무너집니다.
초반 몇 단계(Hop)는 잘 따라가는 척하다가, 어느 순간부터 이미지는 쳐다보지도 않고 언어 모델의 ‘상상력’만으로 그럴싸한 소설(Hallucination)을 써 내려갑니다. 왜 이런 일이 발생할까요? 우리가 VLM을 학습시킬 때 먹이는 RLVR(Reinforcement Learning from Verifiable Rewards) 데이터셋이 대부분 얄팍한 ‘단일 홉(Single-hop)’ 구조이기 때문입니다.
이 문제를 해결하기 위해 등장한 녀석이 바로 HopChain입니다. 모델이 딴짓하지 못하도록, 시각적 단서에 끊임없이 의존해야만 풀 수 있는 ‘멀티홉(Multi-hop) 데이터’를 공장처럼 찍어내는 프레임워크죠.
TL;DR: 기존 VLM이 긴 CoT(Chain-of-Thought) 추론에서 눈을 감고 소설을 쓰는 문제를 해결하기 위해, 논리적으로 완벽히 종속된 다단계 시각 추론 데이터를 합성해내는 파이프라인입니다. Qwen3.5 모델에 태워보니 초장기 추론에서 정확도가 최대 50점이나 폭등합니다. 데이터 파이프라인 구축 난이도는 높지만, 파급력은 압도적입니다.
⚙️ VLM의 눈과 뇌를 연결하는 ‘멀티홉’ 연성 파이프라인 해부
HopChain의 핵심은 아주 단순하면서도 악랄합니다. 이전 단계(Hop)의 시각적 추론을 완벽하게 해내지 못하면, 다음 단계의 질문조차 이해할 수 없도록 논리적 종속성(Logical Dependency)을 강제해버리는 거죠.
어떻게 이런 데이터를 대량으로 합성할까요? 논문은 4단계 파이프라인을 제시합니다.
🔹 카테고리 식별(Category Identification): 이미지 내의 모든 객체와 그 속성을 파악합니다. 🔹 인스턴스 분할(Instance Segmentation): 단순 바운딩 박스를 넘어, 각 객체의 픽셀 단위 마스크를 추출합니다. 🔹 멀티홉 쿼리 생성(Multi-hop Query Gen): 여기서부터가 진짜입니다. 앞서 뽑아낸 인스턴스들을 역추적하며 질문 트리를 만듭니다. 🔹 정답 및 난이도 보정(GT Annotation & Calibration): 최종 정답이 모호한 텍스트가 아닌 ‘숫자(Number)’로 떨어지도록 유도합니다. 그래야 RLVR에서 검증 가능한 보상(Verifiable Reward)을 줄 수 있거든요.
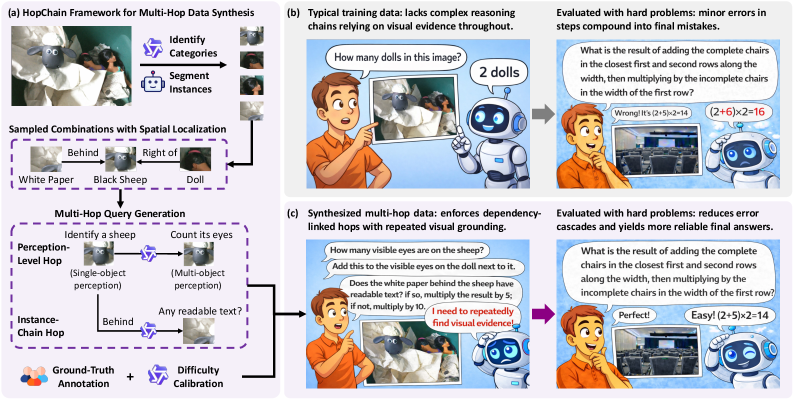
- [그림 설명] HopChain의 전체 4단계 합성 과정과 기존 데이터와의 차별점입니다. 단순히 질문-답변 쌍이 아니라, 각 단계가 이전 단계의 ‘시각적 단서’를 물고 늘어지는 구조를 명확히 보여줍니다.
말로만 하면 와닿지 않죠. 이 파이프라인이 생성해내는 데이터 구조를 JSON 형태로 역설계해 볼까요? 실제 VLM이 학습하게 될 멀티홉 프롬프트의 백엔드 데이터 플로우입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
{
"query_id": "hopchain_eval_092",
"image_path": "s3://dataset/complex_scene_01.jpg",
"reasoning_chain": [
{
"hop": 1,
"instruction": "Find all the cylindrical objects on the wooden table.",
"required_grounding": ["obj_12", "obj_15", "obj_22"], // Segmentation ID
"type": "set_establishment"
},
{
"hop": 2,
"instruction": "Among those objects, filter out the ones that have a metallic texture.",
"required_grounding": ["obj_15"], // Logical dependency on Hop 1
"type": "condition_filtering"
},
{
"hop": 3,
"instruction": "How many red stripes are on that specific metallic object?",
"required_grounding": ["obj_15_region_stripes"],
"expected_answer": 3,
"type": "verifiable_counting"
}
]
}
보이시나요? 모델이 Hop 2를 건너뛰거나 대충 언어적 확률로 때려 맞추려 하면, Hop 3에서 정확한 숫자 3을 절대 도출할 수 없습니다. 매 홉마다 이미지로 돌아가서(Visual Re-grounding) 확인해야만 하죠.

- [그림 설명] 실제 생성된 멀티홉 데이터의 예시입니다. 보라색 텍스트가 인스턴스 체인을 의미하며, 텍스트와 이미지 영역(바운딩 박스)이 어떻게 논리적으로 맞물려 있는지 보여주는 핵심 자료입니다.
⚔️ 기존 RLVR 스택 vs HopChain 패러다임: 진짜 갈아탈 가치가 있나?
이쯤 되면 의문이 듭니다. “어차피 요즘 VLM들 컨텍스트 윈도우 빵빵한데, 굳이 이런 복잡한 합성 데이터까지 써야 해? 컴퓨팅 리소스만 낭비하는 거 아냐?”
숫자로 비교해봅시다. Qwen3.5-35B 모델 기준으로 기존 Single-hop 데이터와 HopChain 멀티홉 데이터를 태웠을 때의 트레이드오프입니다.
| Metrics | Standard Single-hop RLVR | HopChain Multi-hop RLVR | Developer Impact (개발자 관점) |
|---|---|---|---|
| 데이터 합성 파이프라인 난이도 | 낮음 (GPT-4V API 몇 번 호출하면 끝) | 매우 높음 (Instance Seg & Logic Graph 필요) | 초기 인프라 구축에 엔지니어링 리소스 대거 투입 필요. |
| 학습 시 VRAM 요구량 (35B 기준) | 보통 (짧은 CoT) | 높음 (긴 CoT + 다중 이미지 참조) | 8x H100 노드에서의 학습 단가 상승. 배치 사이즈 최적화 필수. |
| Ultra-long CoT 정확도 상승폭 | Baseline | +50 Points (압도적) | 복잡한 도큐먼트 파싱, 도면 분석 등 B2B 태스크에서 게임체인저. |
| 환각(Hallucination) 억제율 | 낮음 (중간에 상상력 발휘) | 매우 높음 (Grounding 강제로 방지) | 고객 불만 폭주의 주원인인 ‘환각’을 아키텍처 레벨에서 차단. |
| Reward Verification | 모호함 (텍스트 매칭 위주) | 명확함 (Final answer is specific number) | RL 파이프라인의 보상 함수 설계가 극도로 깔끔해짐. |
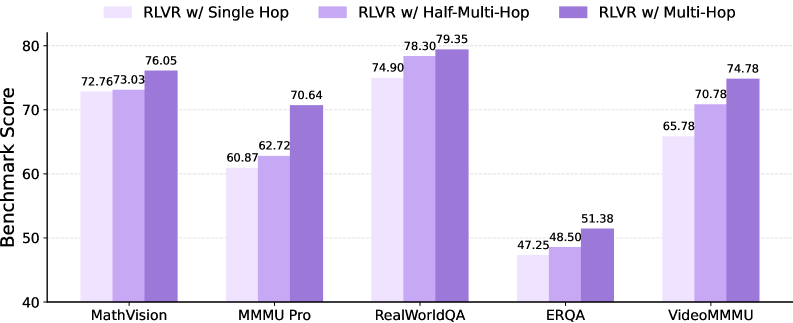
- [그림 설명] 데이터의 홉을 절반으로 자르거나(Half-Multi-Hop) 단일 홉(Single Hop)으로 축소했을 때의 성능 폭락을 보여주는 그래프입니다. 체인이 길고 완전할수록 모델의 뼈대가 튼튼해짐을 증명합니다.
데이터 합성 자체는 골치 아픕니다. 하지만 24개 벤치마크 중 20개에서 성능이 올랐고, 무려 5~7점의 평균 정확도 하락이 홉을 줄였을 때 발생했습니다. 프로덕션에서 모델 서빙 시 발생하는 ‘환각으로 인한 재처리 비용’을 생각하면, 데이터 합성 단계에서 이 정도 비용을 태우는 것은 충분히 남는 장사입니다.
🚀 내일 당장 프로덕션에 도입한다면?
이 논문의 접근법을 실무에 적용하면 어떤 일이 벌어질까요? 단순히 벤치마크 점수 놀음이 아니라, 실제 비즈니스 로직에 어떻게 녹일 수 있을지 2가지 시나리오로 뽑아봤습니다.
시나리오 1: 이커머스 상품 불량 검수 파이프라인 (Automated QA)
- 현재 병목: 기존 VLM은 “운동화 밑창에 실밥이 터졌니?”라고 물으면, 대충 실밥 비슷한 것만 보고 “네”라고 환각을 일으킵니다.
- HopChain 적용:
신발의 좌측면 식별->해당 면의 밑창 엣지 라인 크롭->엣지 라인 내 불규칙 픽셀 덩어리(실밥) 카운팅형태의 합성 데이터로 모델을 파인튜닝합니다. - 주의할 점: 인스턴스 세그멘테이션 모델(예: SAM)의 품질이 구리면 데이터 파이프라인 자체가 오염됩니다. 합성 데이터의 Quality Control(QC)이 전체 프로젝트의 명운을 가릅니다.
시나리오 2: 복잡한 금융/의료 문서 분석 (Document Understanding)
- 현재 병목: 표, 그래프, 깨알 같은 주석이 섞인 재무제표에서 VLM은 행렬(Row/Column)을 매핑하다가 길을 잃습니다.
- HopChain 적용: 데이터 합성 시 “Q3 매출액 막대그래프 찾기 -> Y축 범례 스케일 확인 -> 해당 막대의 정확한 수치 계산”의 체인을 강제합니다.
- 주의할 점: RLVR 학습 시 긴 CoT로 인해 Context Window가 터져나갑니다. FlashAttention-2 최적화와 더불어, 중간 추론 단계를 캐싱(KV Cache)하는 서빙단 설계가 선행되어야 합니다.
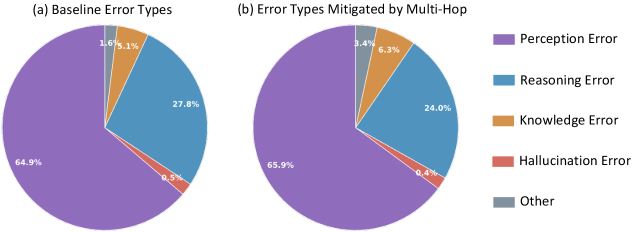
- [그림 설명] HopChain 적용 전후의 에러 타입 분포입니다. 인지(Perception)와 추론(Reasoning) 에러가 근본적으로 완화되는 패턴을 보여주며, 이는 모델이 특정 태스크에 과적합된 것이 아니라 일반화된 추론 능력을 얻었음을 시사합니다.

- [그림 설명] 기존 모델(Baseline)이 긴 추론 도중 시각적 단서를 놓치고 엉뚱한 결론을 내리는 전형적인 실패 사례들입니다. 빨간색 텍스트가 모델이 눈을 감고 소설을 쓰기 시작한 지점입니다.
🧐 Tech Lead’s Honest Verdict
👍 Pros: 이거 진짜 물건입니다. 무엇보다 VLM 학습의 가장 큰 골칫거리인 “어떻게 하면 이 녀석이 끝까지 이미지를 쳐다보게 만들까?”에 대한 구조적인 해답을 내놓았습니다. 최종 보상을 숫자로 떨어뜨리도록 설계한 점은 RL 엔지니어들의 십년묵은 체증을 내려가게 합니다.
👎 Cons: 인프라 담당자는 울고 있습니다. 데이터를 텍스트로만 뚝딱 만들어내는 LLM의 합성 프레임워크와는 궤가 다릅니다. 비전 모델 기반의 식별, 분할, 추적 로직을 데이터 생성 파이프라인에 전부 올려야 합니다. 파이프라인 자체가 거대한 모노리스(Monolith)가 되어 유지보수 지옥이 열릴 수 있습니다.
🔥 Final Verdict: “데이터 팀 당장 소집하세요.” 만약 당신의 팀이 VLM을 파인튜닝해서 B2B 도메인에 팔 생각이라면, 기존의 평면적인 데이터셋은 전부 쓰레기통에 넣으셔도 좋습니다. 당장 HopChain 파이프라인을 클론해서 내부 데이터 파이프라인의 베이스라인으로 삼으세요. 인프라 비용이 더 들더라도, 환각 1%를 줄이는 게 고객사 이탈을 막는 유일한 길이니까요.
