[2026-03-10] 로봇 여러 대가 보내는 1인칭 영상, AI는 과연 이해할까? 'MA-EgoQA'와 다중 에이전트의 한계

[로봇 여러 대가 보내는 1인칭 영상, AI는 과연 이해할까? ‘MA-EgoQA’와 다중 에이전트의 한계]
Metadata
- Paper: MA-EgoQA: Question Answering over Egocentric Videos from Multiple Embodied Agents
- Arxiv ID: 2603.09827
- Project Page: https://ma-egoqa.github.io
요즘 ‘Embodied AI(물리적 실체가 있는 AI)’가 대세라느니, 곧 휴머노이드 여러 대가 집안일이나 물류 센터 업무를 알아서 나눠서 할 거라느니 하는 핑크빛 미래에 대한 이야기 많이 들으시죠? 저도 최근 프로젝트에서 로컬 VLM(Vision-Language Model)을 여러 카메라 스트림에 동시에 물려보는 작업을 하다가 말 그대로 ‘지옥’을 맛봤습니다.
단일 카메라 영상 하나 처리하는 것도 토큰과 메모리를 엄청나게 잡아먹는데, 5~6대의 움직이는 에이전트(로봇이나 사람)가 각자의 1인칭 시점(Egocentric)으로 찍은 영상을 실시간으로 이해하고 서로의 상황을 파악하게 만드는 건 현재 기술력으로는 억지에 가깝습니다. 각 에이전트의 시야각도 다르고, 시간대도 꼬이고, 심지어 영상 속 공간이 겹칠 때 이를 하나의 맥락으로 묶어내는 메타 인지 능력 자체가 현재 SOTA 모델들에는 턱없이 부족하거든요.
이러한 현업의 고통을 정확히 찌르며 등장한 연구가 바로 MA-EgoQA입니다. 이 논문은 단순히 “우리 모델 짱이다”를 외치는 게 아니라, “너희들 지금 모델로 멀티 에이전트 환경 테스트해보면 처참하게 깨질걸?”이라며 현실의 벽을 보여주는 매우 도발적이고 실용적인 벤치마크와 베이스라인 모델(EgoMAS)을 제안합니다.
한 줄 요약: 단순한 비디오 이어붙이기를 넘어, 여러 에이전트의 1인칭 시점 비디오를 통합해 ‘공유 메모리’를 구축하는 시스템적 접근. 하지만 이를 실무에 쓰기엔 연산량의 압박이 너무나도 거대하다.
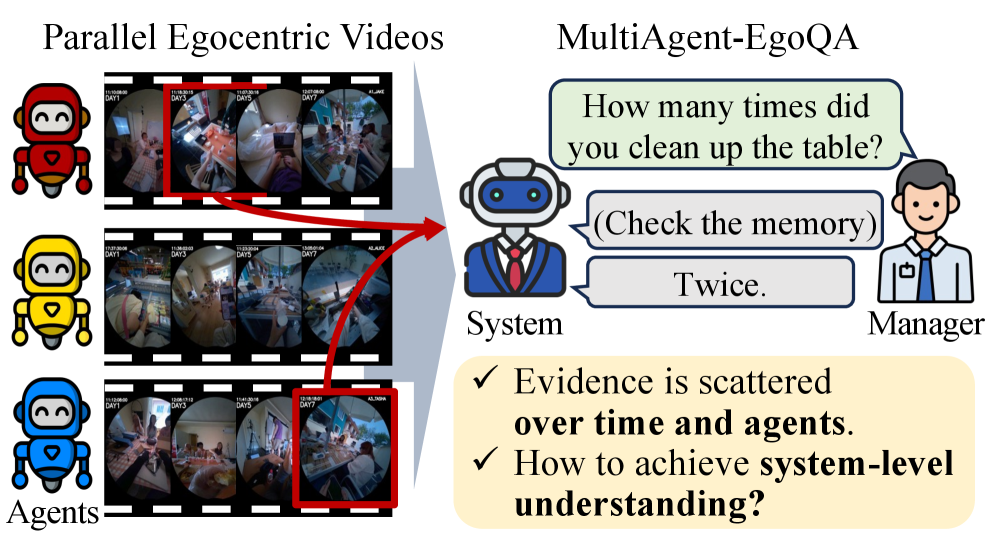
- 멀티 에이전트 시스템에서 발생할 수 있는 데이터 폭발과, 각 에이전트의 분절된 시야를 시스템 레벨에서 하나로 통합해야 하는 극한의 난이도를 시각화한 다이어그램입니다.
🧠 수많은 1인칭 비디오를 어떻게 하나의 뇌(Memory)로 엮어낼 것인가?
여러 대의 로봇이 돌아다니는 환경을 상상해 보세요. A 로봇은 주방에서 설거지를 하고 있고, B 로봇은 거실을 치우고 있습니다. 이때 사용자가 “아까 A가 컵을 어디에 뒀는지 B가 보고 있었어?” 같은 질문을 던진다고 해보죠. 이걸 해결하려면 시스템은 A의 비디오와 B의 비디오를 동시에 인덱싱하고, 공간적/시간적 접점을 찾아내 추론해야 합니다.
MA-EgoQA 연구진은 이를 해결하기 위해 단순한 벤치마크를 넘어 EgoMAS라는 베이스라인 아키텍처를 제시합니다. 13만 줄짜리 거대한 프레임워크는 아니지만, 꽤나 영리하게 데이터 병목을 피하는 구조를 취하고 있습니다. 무식하게 모든 비디오 프레임을 LLM 컨텍스트에 욱여넣는(Context stuffing) 방식이 아니라, 일종의 멀티 에이전트 전용 RAG(Retrieval-Augmented Generation) 구조를 그립니다.
🔹 Agent-wise Dynamic Retrieval (에이전트별 동적 검색) 가장 핵심적인 로직입니다. 6개의 카메라 영상을 하나의 거대한 벡터 DB에 때려 넣으면 노이즈가 폭발합니다. 대신 EgoMAS는 쿼리가 들어오면, 각 에이전트의 타임라인에서 현재 질문과 관련된 클립(Clip)을 독립적으로 검색합니다. 개발자 관점에서 보면, 마치 분산 데이터베이스에서 샤딩(Sharding)된 각 노드에 병렬로 SELECT 쿼리를 날려 가장 연관성 높은 타임스탬프를 뽑아내는 것과 같습니다.
🔹 System-Level Shared Memory (시스템 단위 공유 메모리) 각 에이전트에서 파편적으로 검색된 비디오 클립들은 그대로 LLM에 던져지지 않습니다. 이 클립들은 ‘공유 메모리 버퍼’로 모여 시공간적 정렬을 거칩니다. A의 2분 30초 시점과 B의 2분 32초 시점이 같은 공간을 다르게 보고 있다는 것을 토큰 임베딩 단계에서 매핑해 주는 것이죠. 이를 통해 VLM은 각기 다른 에이전트의 행동이 어떻게 교차(Interaction)하는지 이해할 수 있는 기반을 얻게 됩니다.

- 단순한 객체 인식을 넘어, 다른 에이전트의 의도(Theory-of-Mind)나 협동 작업(Task Coordination)까지 묻는 실제 벤치마크의 질문들입니다. 현존하는 거의 모든 VLM이 여기서 바보가 됩니다.
⚔️ 기존 VLM 떡칠 방식 vs 새로운 EgoMAS 패러다임
그렇다면 기존에 우리가 흔히 쓰던 LLaVA나 GPT-4V를 이용한 단순 비디오 이어붙이기(Concatenation) 방식과 이번 연구의 접근 방식은 어떤 차이가 있을까요? 지표와 체감 성능 면에서 비교해 보겠습니다.
| 비교 항목 | 기존 방식 (Flat VLM Concatenation) | 새로운 접근법 (EgoMAS Architecture) |
|---|---|---|
| 아키텍처 철학 | “비디오 프레임 전부 LLM 컨텍스트에 넣어. 알아서 보겠지.” | “에이전트별로 필요 구간만 병렬 검색한 뒤 메모리에 올려.” |
| 메모리 효율 (VRAM) | O(N×T) – 에이전트 수(N)와 시간(T)에 비례해 터짐 (OOM 발생 빈번) | O(N×k) – 검색된 top-k 프레임만 로드하므로 메모리 상한 관리 가능 |
| 추론 속도 (Latency) | 컨텍스트 윈도우 초과로 인한 막대한 TTFT (Time To First Token) | 초기 검색 오버헤드는 있으나, LLM 입력 토큰이 줄어들어 최종 응답 빠름 |
| 공간 인지력 | 누가 어느 시점의 영상을 찍었는지 환각(Hallucination) 현상 극심함 | 에이전트 ID와 타임스탬프가 구조화되어 교차 검증(Cross-reference) 용이 |
| Developer Experience | 컨텍스트 길이에만 의존하므로 디버깅 불가능 (어디서 틀렸는지 모름) | 각 에이전트별 Retrieval 로그를 확인할 수 있어 원인 분석 및 튜닝 가능 |
기존 방식은 말 그대로 ‘운에 맡기는’ 수준이었습니다. 컨텍스트 윈도우가 1M 토큰 시대라지만, 시각 정보가 무작위로 섞여 들어가면 LLM은 그 안에서 인과관계를 조립하지 못합니다. 반면 EgoMAS 방식은 개발자에게 제어권(Control)을 쥐여줍니다. Retrieval 단계에서 필터링이 되기 때문에, 최소한 에이전트 B의 영상을 A의 행동으로 오해하는 치명적인 버그는 줄일 수 있죠.
🚀 당장 현업에서 어떻게 써먹을 수 있을까?
이 논문이 단순 학술용 벤치마크에서 끝나지 않고 실제 아키텍처에 영감을 주는 부분은 명확합니다. 저는 아래 두 가지 시나리오에서 이 구조를 당장 벤치마킹해볼 가치가 있다고 봅니다.
스마트 팩토리/물류 센터의 다중 AGV (무인 운반차) 관제 시스템 현재 물류 창고에는 수십 대의 AGV가 각자의 카메라를 달고 돌아다닙니다. 만약 특정 구역에서 충돌 사고나 물품 누락이 발생했을 때, 관리자가 “오후 2시에 3번 통로에서 떨어진 박스를 지나친 로봇들이 누구누구야?”라고 슬랙 봇에 묻는다면 어떨까요? 중앙 서버에서 50대의 24시간 비디오를 다 돌려보는 건 미친 짓입니다. EgoMAS의 에이전트별 동적 검색 로직을 적용하면, 사고 구역을 지나간 로봇들의 시점만 빠르게 병렬 추출하여 중앙 LLM에 던져 사고 리포트를 생성하게 만들 수 있습니다.
건설 현장 및 재난 구조 현장의 드론-작업자 협업 체계 재난 구조 현장에서는 구조 대원의 바디캠(1인칭 시점)과 상공을 도는 드론(3인칭/탑다운 시점) 영상이 동시에 수집됩니다. 이기종 에이전트가 섞인 환경이죠. 구조 지휘 본부에서 “드론 A가 발견한 붕괴 지점을 대원 B가 진입하면서 확인했는가?”를 파악해야 할 때, 이러한 시스템 레벨의 다중 에이전트 메모리 아키텍처가 필수적입니다.
🧐 Tech Lead’s Verdict
이 논문과 코드를 뜯어보면서 느낀 감정은 ‘반가움’ 반, ‘막막함’ 반이었습니다. 멀티 에이전트 시스템에서 발생할 수 있는 데이터 구조의 근본적인 문제를 짚어낸 점은 박수받아 마땅합니다.
장점 (Pros):
- 뜬구름 잡는 AGI 타령이 아니라, 다수의 로봇이 투입되는 현실적인 미래 환경을 위한 날카로운 문제 제기.
- 에이전트의 ‘Theory-of-Mind(다른 에이전트의 상태나 의도를 파악하는 능력)’까지 평가 카테고리로 넣은 데이터셋(MA-EgoQA)의 치밀함.
- 단순하고 우아한 Retrieval 기반 베이스라인 모델(EgoMAS) 제공.
단점 (Cons):
- 결국 돈과 컴퓨팅 파워의 문제: 에이전트별로 동적 검색을 한다고는 하지만, 영상 임베딩을 지속적으로 뽑아내고 인덱싱하는 과정 자체가 엣지(Edge) 디바이스에서는 감당 불가능한 수준입니다. 막대한 클라우드 GPU 비용이 강제됩니다.
- 여전히 높은 오답률: 논문 내 실험 결과를 보면 알겠지만, EgoMAS를 적용해도 정답률이 현업 프로덕션에 쓰기엔 한참 모자랍니다. 데이터 정렬의 한계라기보다는 현재 VLM 자체의 시공간 추론 능력의 한계가 명백하게 드러납니다.
최종 평가: “영감(Inspiration)용으로 Clone 해두되, 프로덕션 도입은 VLM 발전 속도를 더 지켜봐라.”
MA-EgoQA는 멀티 에이전트 환경의 VLM 한계를 밑바닥까지 까발린 훌륭한 스트레스 테스트 도구입니다. 당신이 로봇 공학이나 차세대 멀티 모달 RAG 시스템을 설계하고 있다면, 이들이 제시한 파이프라인과 문제 정의는 반드시 숙지해야 합니다. 하지만 내일 당장 이 코드를 사내 시스템에 올려서 완벽하게 동작하길 기대한다면… 팀장님께 GPU 예산을 10배로 늘려달라고 먼저 결재를 올리시길 바랍니다.
Additional Figures
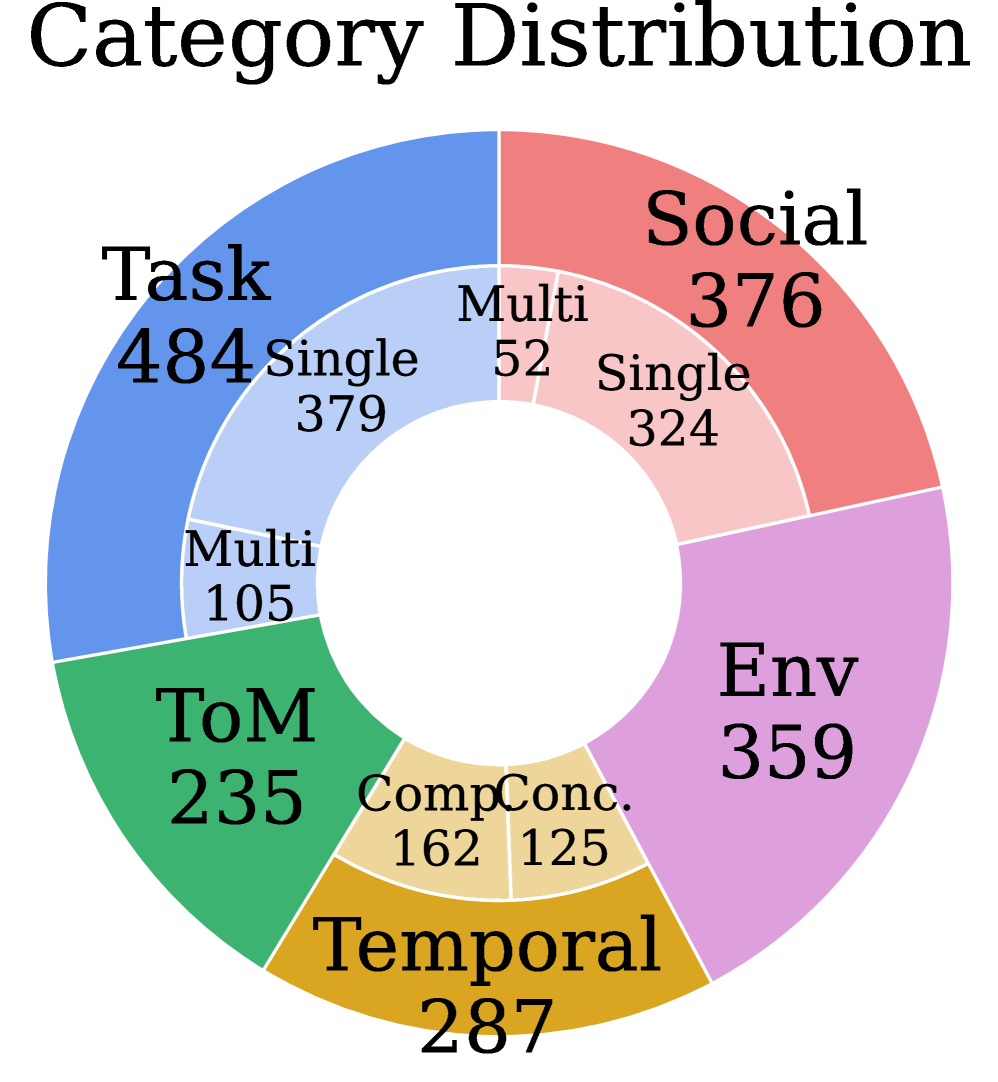 Figure 3:Statistics for MA-EgoQA;(Left)number of samples per category;(Center)day/agent reference counts of all categories;(Right)question type distribution.
Figure 3:Statistics for MA-EgoQA;(Left)number of samples per category;(Center)day/agent reference counts of all categories;(Right)question type distribution.
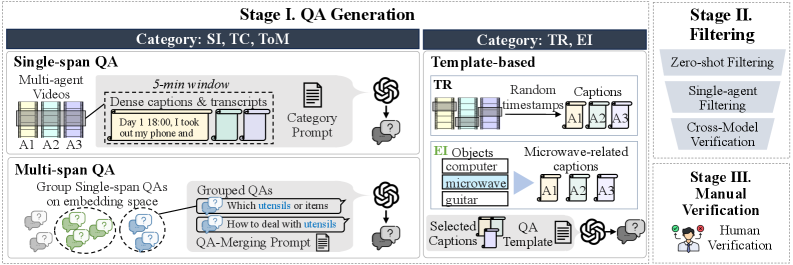 Figure 4:Benchmark construction pipeline. QA pairs are generated for each category through its dedicated process, and refined through LLM filtering and manual check.
Figure 4:Benchmark construction pipeline. QA pairs are generated for each category through its dedicated process, and refined through LLM filtering and manual check.
