[2026-02-23] 아이폰에서 3초 만에 보고 그린다? 온디바이스 통합 멀티모달 AI 'Mobile-O' 심층 분석

🚀 이제 아이폰이 직접 보고 그립니다: 온디바이스 통합 멀티모달 Mobile-O의 혁명
현대 AI의 가장 큰 화두는 ‘통합(Unified)’과 ‘효율(Efficiency)’입니다. 하지만 거대 언어 모델(LLM)과 확산 모델(Diffusion Model)을 하나로 합쳐 모바일 기기에서 돌리는 것은 지금까지 불가능에 가까운 영역이었습니다.
과연 AI가 클라우드 비용 없이, 지연 시간 없이 내 스마트폰 안에서 완벽하게 작동하여 비즈니스 가치를 창출할 수 있을까요?
💡 한 마디로?
Mobile-O는 독자적인 Mobile Conditioning Projector(MCP)를 통해 시각적 이해와 이미지 생성을 단일 모델로 통합, 아이폰에서 3초 만에 구동되는 최초의 실용적 온디바이스 통합 멀티모달 프레임워크입니다.
📖 논문: https://huggingface.co/papers/2602.20161
🖥️ 프로젝트 페이지: https://amshaker.github.io/Mobile-O/
[1] 🎯 Executive Summary
- 통합 모델의 경량화: 시각적 이해(VLM)와 생성(Diffusion)을 하나의 초경량 아키텍처로 통합.
- 압도적 속도: 기존 모델(Show-O, JanusFlow) 대비 6배에서 11배 빠른 속도.
- 성능 우위: GenEval 74% 달성 및 7개 벤치마크 평균 이해 성능에서 경쟁 모델을 5.1~15.3% 상회.
- 실제 구동: 아이폰 17 프로에서 512x512 이미지를 단 3초 만에 생성.
- 데이터 효율성: 수십억 개가 아닌, 단 몇 백만 개의 샘플만으로 학습 성공.
[2] 🤔 왜 ‘Mobile-O’가 필요한가?
기존의 멀티모달 모델들은 두 가지 치명적인 한계가 있었습니다.
- 데이터 기아(Data-hungry): 성능을 내기 위해 천문학적인 양의 데이터와 연산 자원이 필요했습니다.
- 엣지 배포의 어려움: 모델이 너무 무거워 클라우드 인프라(A100, H100) 없이는 작동이 불가능했습니다.
이는 기업 입장에서 높은 클라우드 추론 비용(Inference Cost)과 개인정보 보호 문제로 직결됩니다. Mobile-O는 이러한 병목 현상을 해결하여 B2B AI SaaS 및 개인형 AI 비서 시장의 게임 체인저가 되려 합니다.
[3] 🔥 핵심 방법론: 어떻게 모바일에서 이게 가능한가?
Mobile-O의 핵심은 Mobile Conditioning Projector (MCP)라는 혁신적인 브릿지 구조에 있습니다.
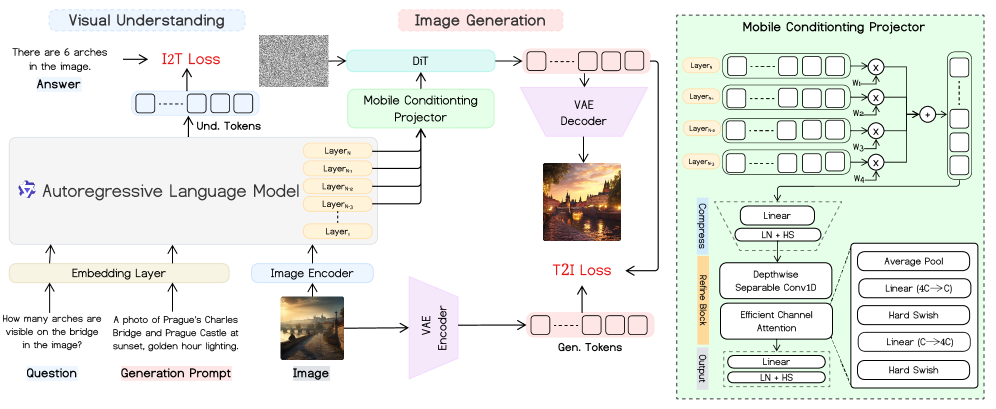 Figure 1: Mobile-O의 전체 아키텍처. 이해(VLM)와 생성(DiT)을 MCP가 정교하게 연결합니다.
Figure 1: Mobile-O의 전체 아키텍처. 이해(VLM)와 생성(DiT)을 MCP가 정교하게 연결합니다.
🛠️ 아키텍처의 3대 핵심 기둥
- Mobile Conditioning Projector (MCP):
- 기존 모델들이 복잡한 ‘쿼리 토큰’을 생성하여 정보를 전달했다면, MCP는 VLM의 레이어별 은닉 상태(Hidden States)를 직접 확산 모델(DiT)에 주입합니다.
- 비유하자면: 통역사를 거치지 않고 뇌의 신호를 근육에 직접 전달하는 것과 같습니다. Depthwise-separable convolution을 사용해 연산량을 최소화했습니다.
- Quadruplet Post-training:
- (생성 프롬프트, 이미지, 질문, 답변)이라는 4중주 형태의 데이터 포맷을 사용합니다.
- 이 덕분에 생성과 이해라는 두 마리 토끼를 동시에 잡는 Multi-task Learning이 극대화됩니다.
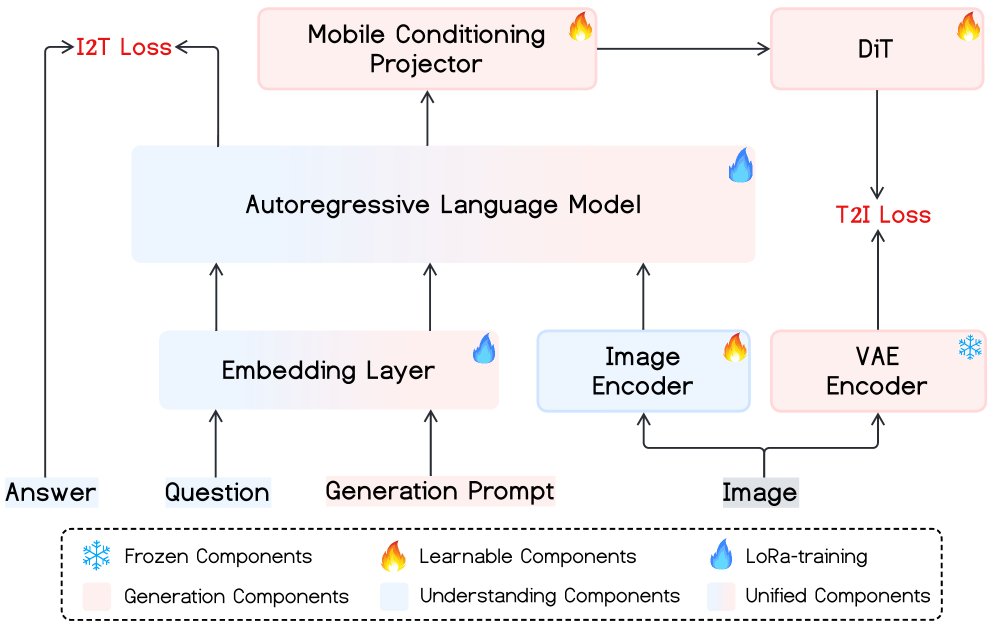 Figure 2: 생성과 이해 손실 함수를 동시에 최적화하는 쿼드러플렛 학습 파이프라인.
Figure 2: 생성과 이해 손실 함수를 동시에 최적화하는 쿼드러플렛 학습 파이프라인.
- Lightweight DiT & VAE:
- Linear Diffusion Transformer를 채택하여 모바일 NPU(Neural Processing Unit)에 최적화된 연산 구조를 갖췄습니다.
[4] 💼 비즈니스 임팩트 및 시장 전망
Mobile-O는 단순한 기술 시연을 넘어 실질적인 ROI(투자 대비 수익)를 제공합니다.
- 인프라 비용 0원: 모든 추론이 사용자 기기에서 발생하므로 서버 유지비가 발생하지 않습니다.
- 프라이버시 최우선: 사용자의 데이터가 외부로 유출되지 않아 기업용 보안 메신저나 헬스케어 서비스에 적합합니다.
- 실시간 창작 도구: 모바일 이미지 에디팅 앱에서 대기 시간 없이 AI 기능을 제공할 수 있습니다.
![Figure 4:Qualitative image editing results of Mobile-O-0.5B. Given a source image and a textual editing instruction, Mobile-O-0.5B produces the edited output. The model is fine-tuned on only 46k editing samples from ShareGPT4V[6]](https://www.opsoai.com/assets/img/papers/2602.20161/x7.png) Figure 4: 단 4.6만 개의 샘플 학습만으로 구현된 고성능 모바일 이미지 편집 결과.
Figure 4: 단 4.6만 개의 샘플 학습만으로 구현된 고성능 모바일 이미지 편집 결과.
| 비교 지표 | JanusFlow | Show-O | Mobile-O (Ours) |
|---|---|---|---|
| GenEval (생성) | 63% | 69% | 74% |
| 추론 속도 | 1x (기준) | 1.8x | 11x |
| 아이폰 구동 시간 | 불가 | 수십 초 | ~3초 |
[5] 🧑💻 전문가의 시선: 비평 및 구현 가이드
⚡ 1줄 Verdict
“Mobile-O는 ‘거대함’이 정답이 아니라는 것을 증명한, 엣지 AI 시대의 가장 현실적인 이정표입니다.”
🚧 기술적 한계 및 과제
- 해상도 한계: 현재 512x512 해상도 위주로 최적화되어 있어, 더 높은 고해상도 생성 시 메모리 병목이 발생할 수 있습니다.
- 에너지 효율: 3초라는 빠른 속도에도 불구하고 연속적인 추론 시 발열 및 배터리 소모에 대한 최적화가 추가로 필요합니다.
🛠️ 개발자를 위한 구현 팁
- NPU 최적화: CoreML이나 TFLite로 변환 시 MCP 레이어의 Depthwise Conv 연산이 하드웨어 가속을 제대로 받는지 확인해야 합니다.
- 데이터 커스텀: 특정 도메인(예: 패션, 인테리어)에 특화된 쿼드러플렛 데이터를 수집하여 파이인튜닝하면 비즈니스 특화 모델로 즉시 전환 가능합니다.
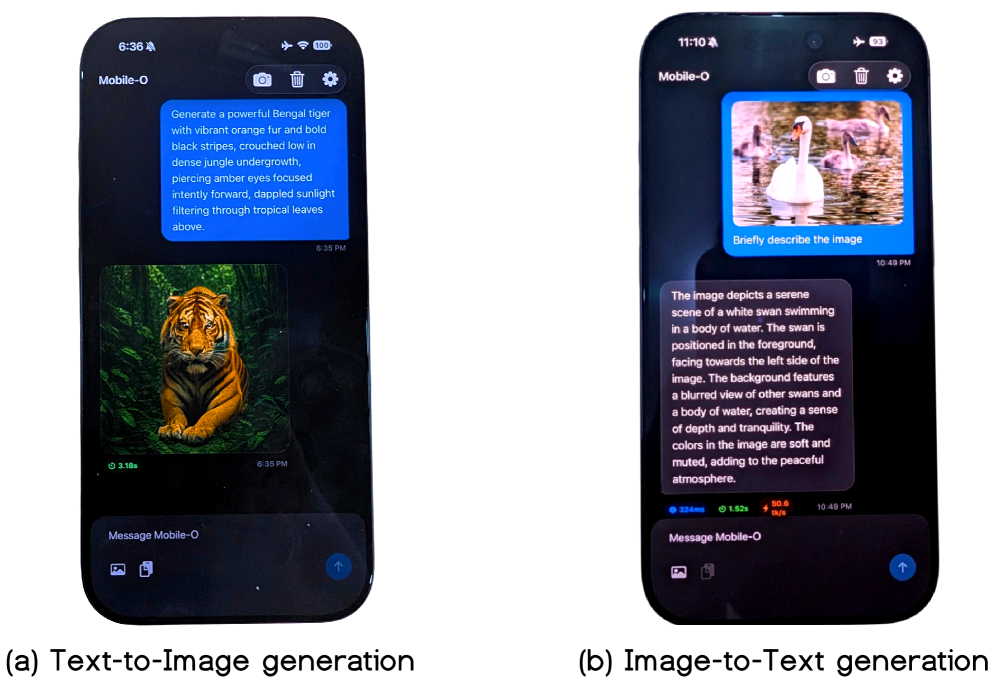 Figure 5: 실제 아이폰 17 Pro에서 구동되는 Mobile-O의 모습. 이해와 생성이 한 기기에서 동시에 이루어집니다.
Figure 5: 실제 아이폰 17 Pro에서 구동되는 Mobile-O의 모습. 이해와 생성이 한 기기에서 동시에 이루어집니다.
Mobile-O의 등장은 클라우드 종속적인 AI 생태계에 큰 변화를 예고합니다. 저사양 기기에서도 강력한 멀티모달 기능을 구현하고 싶은 스타트업이라면, Mobile-O의 MCP 구조를 반드시 연구해 보시기 바랍니다.
Additional Figures
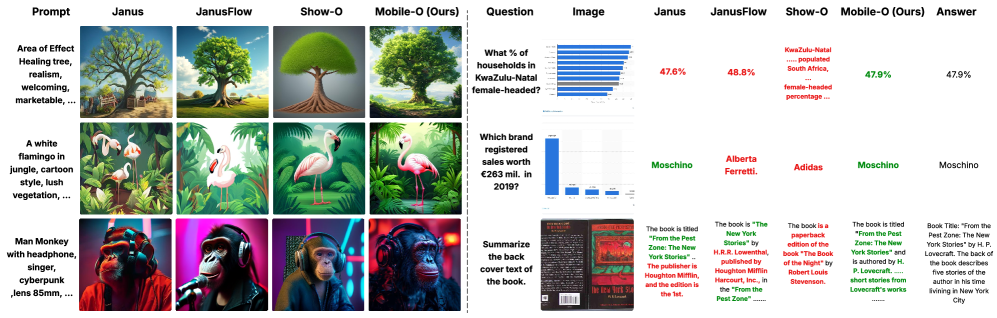 Figure 3:Qualitative comparison of text-to-image generation (left) and visual understanding (right) across unified multimodal models. Each column shows Janus, JanusFlow, Show-O, and Mobile-O (ours) for the same prompts/questions. Mobile-O yields more consistent, detailed, and semantically faithful images with high fidelity and style diversity for image generation. For visual understanding, it delivers more accurate and contextually coherent responses. Additional results are presented in suppl. material. Best viewed zoomed in.
Figure 3:Qualitative comparison of text-to-image generation (left) and visual understanding (right) across unified multimodal models. Each column shows Janus, JanusFlow, Show-O, and Mobile-O (ours) for the same prompts/questions. Mobile-O yields more consistent, detailed, and semantically faithful images with high fidelity and style diversity for image generation. For visual understanding, it delivers more accurate and contextually coherent responses. Additional results are presented in suppl. material. Best viewed zoomed in.
