[2026-02-13] 3B 모델의 한계를 넘어서: Nanbeige4.1-3B, 추론과 에이전트 기능을 극대화한 초소형 범용 AI의 탄생

1. 핵심 요약 (Executive Summary)
오늘날 인공지능 연구의 흐름은 단순히 거대 언어 모델(LLM)의 크기를 키우는 것을 넘어, 제한된 자원 내에서 얼마나 효율적이고 강력한 성능을 발휘할 수 있는가(Efficiency vs. Capability)로 이동하고 있습니다. 이러한 흐름 속에서 등장한 Nanbeige4.1-3B는 30억(3B) 파라미터라는 매우 작은 크기임에도 불구하고, 복잡한 추론(Reasoning), 정교한 코드 생성(Code Generation), 그리고 장기적 에이전트 행동(Agentic Behavior)을 동시에 달성한 기념비적인 모델입니다.
이 모델은 특히 ‘딥 서치(Deep Search)’ 데이터 합성 파이프라인과 ‘시간 복잡도 인지형 강화학습(Complexity-aware RL)’을 통해 기존 소형 모델(SLM)들이 가졌던 한계를 정면으로 돌파했습니다. 본 분석 보고서에서는 Nanbeige4.1-3B가 어떻게 600회의 도구 호출(Tool-call)을 견뎌내는 안정성을 확보했는지, 그리고 왜 이 모델이 Qwen3-30B-A3B와 같은 대형 모델보다 특정 도메인에서 우위에 서는지 기술적으로 심층 분석합니다.
2. 연구 배경 및 문제 정의 (Introduction & Problem Statement)
2.1 소형 모델(SLM)의 딜레마
기존의 3B급 모델들은 모바일 기기나 엣지 컴퓨팅 환경에 적합한 가벼움을 장점으로 내세웠으나, 성능 면에서는 명확한 한계가 존재했습니다. 구체적으로는 다음과 같은 세 가지 고질적인 문제에 직면해 있었습니다.
- 범용성의 결여: 특정 작업(예: 대화)에는 능숙하지만, 코드 작성이나 복잡한 논리 추론에서는 성능이 급격히 저하됨.
- 에이전트 능력의 한계: 외부 도구를 사용할 때, 대화의 맥락이 길어지면(Long-horizon) 환각 증상(Hallucination)이 발생하거나 도구 호출의 형식을 잃어버림.
- 코드의 비효율성: 단순히 작동하는 코드를 짜는 데 급급하며, 알고리즘의 최적화(시간 및 공간 복잡도)를 고려하지 못함.
2.2 Nanbeige4.1의 도전 과제
Nanbeige 팀은 이러한 한계를 극복하기 위해 “Small yet Mighty”라는 철학 아래, 모델의 아키텍처 최적화보다는 데이터의 질과 학습 전략의 정교화에 집중했습니다. 이들은 단일 모델이 추론, 코드, 에이전트라는 세 마리 토끼를 잡을 수 있음을 증명하고자 했으며, 이를 위해 강화학습(RL)과 데이터 합성(Synthesis) 기법을 극단으로 끌어올렸습니다.
3. 핵심 기술 및 아키텍처 심층 분석 (Core Methodology)
3.1 딥 서치(Deep Search) 및 데이터 합성 파이프라인
Nanbeige4.1-3B의 가장 큰 강점 중 하나는 복잡한 추론 경로를 스스로 생성하고 학습하는 능력입니다. 이를 위해 연구진은 고도화된 데이터 구성 파이프라인을 설계했습니다.
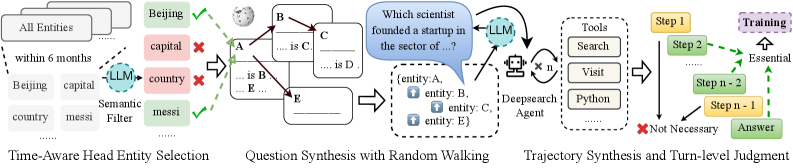 이 그림은 다중 홉(Multi-hop) 질의응답 샘플링과 장기 추론 궤적 합성을 포함하는 딥 서치용 데이터 구축 파이프라인을 보여줍니다.
이 그림은 다중 홉(Multi-hop) 질의응답 샘플링과 장기 추론 궤적 합성을 포함하는 딥 서치용 데이터 구축 파이프라인을 보여줍니다.
연구팀은 단순히 정답만 학습시키는 것이 아니라, 정답에 도달하기 위한 ‘사고의 과정(Chain-of-Thought)’을 체계적으로 합성했습니다. 특히 Multi-hop QA 샘플링을 통해 정보 간의 연결 고리를 추적하게 함으로써, 모델이 복잡한 질문에 대해 단계적으로 사고할 수 있는 능력을 배양했습니다. 이는 모델이 단순히 패턴을 암기하는 것이 아니라, 논리적 구조를 이해하도록 유도합니다.
3.2 정렬(Alignment) 전략: Point-wise & Pair-wise Reward Modeling
모델의 응답 품질을 높이기 위해 Nanbeige는 두 가지 보상 모델링 기법을 혼합했습니다.
- Point-wise Reward: 개별 응답의 절대적인 품질을 평가하여 점수를 부여합니다. 이는 응답의 정확성과 사실 관계를 확인하는 데 효과적입니다.
- Pair-wise Reward: 두 가지 이상의 응답 후보를 비교하여 더 나은 응답을 선택하게 합니다. 이는 인간의 선호도(Human Preference)를 미세하게 반영하는 데 유리합니다.
이러한 하이브리드 접근법은 모델이 인간의 의도를 더 정확하게 파악하고, 무조건 긴 답변이 아닌 ‘가장 가치 있는 답변’을 생성하도록 돕습니다.
3.3 코드 생성의 혁신: 시간 복잡도 인지형 강화학습(Code RL)
일반적인 코드 생성 모델은 유닛 테스트(Unit Test) 통과 여부만을 보상으로 삼습니다. 하지만 Nanbeige4.1-3B는 여기서 한 걸음 더 나아가 시간 복잡도(Time Complexity)를 보상 체계에 통합했습니다.
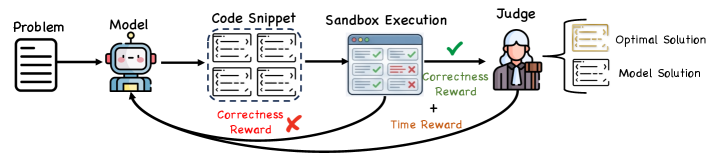 그림 3은 코드 강화학습에서의 게이트형 시간 복잡도 보상 설계를 보여줍니다. 시간 보상은 모든 테스트 케이스를 통과했을 때만 활성화되며, 최적의 복잡도와 비교하여 피드백을 제공합니다.
그림 3은 코드 강화학습에서의 게이트형 시간 복잡도 보상 설계를 보여줍니다. 시간 보상은 모든 테스트 케이스를 통과했을 때만 활성화되며, 최적의 복잡도와 비교하여 피드백을 제공합니다.
이 구조의 핵심은 $R_{time}$ 보상입니다. 모델이 짠 코드가 정답을 맞혔더라도(PassRate=1), 실행 시간이 최적의 알고리즘(Reference Bound)보다 느리면 낮은 보상을 받습니다. 이는 모델이 효율적인 알고리즘(예: $O(n^2)$ 대신 $O(n \log n)$)을 선택하도록 강제하며, 실질적인 소프트웨어 개발 역량을 비약적으로 향상시킵니다.
4. 구현 및 실험 환경 (Implementation Details & Experiment Setup)
4.1 2단계 코드 강화학습(Two-stage Code RL)
모델의 학습은 점진적으로 진행되었습니다. 첫 번째 단계에서는 일반적인 코드 정확도를 높이는 데 집중하고, 두 번째 단계에서는 앞서 설명한 시간 복잡도 보상을 추가하여 성능을 최적화했습니다.
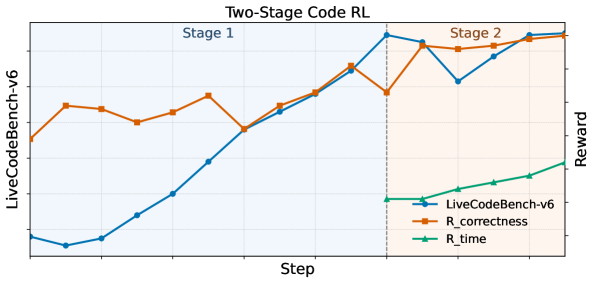 그림 4는 2단계 코드 강화학습의 역동성을 보여줍니다. 단계 1에서 2로 넘어가며 보상과 LiveCodeBench 성능이 지속적으로 향상되는 것을 확인할 수 있습니다.
그림 4는 2단계 코드 강화학습의 역동성을 보여줍니다. 단계 1에서 2로 넘어가며 보상과 LiveCodeBench 성능이 지속적으로 향상되는 것을 확인할 수 있습니다.
4.2 에이전트 학습: Turn-level Supervision
장기적인 도구 사용 능력을 위해, 연구진은 ‘턴 단위 지도 학습(Turn-level Supervision)’을 도입했습니다. 에이전트가 도구를 호출할 때마다 매 순간의 결정이 올바른지를 평가함으로써, 최대 600회의 턴이 지속되더라도 목표를 잃지 않고 작업을 수행할 수 있는 안정성을 확보했습니다. 이는 3B 모델로서는 전례 없는 수준의 에이전트 안정성입니다.
5. 성능 평가 및 비교 (Comparative Analysis)
Nanbeige4.1-3B는 벤치마크 평가에서 놀라운 결과를 보여주었습니다.
- 범용 추론: Qwen3-4B와 같은 동급 모델을 가볍게 압도할 뿐만 아니라, 일부 추론 벤치마크에서는 수십 배 큰 Qwen3-30B-A3B 모델과 대등하거나 그 이상의 성능을 발휘했습니다.
- 코드 생성: LiveCodeBench 및 HumanEval에서 3B 모델 중 최고 수준의 점수를 기록했습니다. 특히 시간 복잡도를 고려한 학습 덕분에 작성된 코드의 실제 실행 효율성이 매우 높았습니다.
- 에이전트 성능: 복잡한 API 호출이 필요한 환경에서 Nanbeige4.1-3B는 600턴 이상의 상호작용을 성공적으로 완수하며, 소형 모델도 복잡한 워크플로우를 자동화할 수 있음을 입증했습니다.
전문가 소견: “단순히 파라미터 수가 적다고 해서 지능이 낮다는 편견을 깨버린 결과입니다. 데이터의 밀도(Data Density)와 보상 함수의 정교함이 모델 규모의 차이를 극복할 수 있음을 극명하게 보여줍니다.”
6. 실제 적용 분야 및 글로벌 파급력 (Real-World Application & Impact)
Nanbeige4.1-3B의 등장은 산업계에 다음과 같은 실질적인 변화를 가져올 수 있습니다.
6.1 온디바이스 AI (On-device AI)의 고도화
3B 모델은 최신 스마트폰이나 노트북에서 인터넷 연결 없이 로컬로 구동 가능합니다. Nanbeige4.1-3B를 탑재한 기기는 사용자의 개인 데이터를 외부로 유출하지 않으면서도 고도의 논리 추론과 개인 비서(Agent) 기능을 수행할 수 있습니다. 이는 프라이버시가 중시되는 기업용(B2B) 보안 단말기에 최적입니다.
6.2 자율형 데브옵스(Autonomous DevOps) 에이전트
600회의 도구 호출 능력은 모델이 단순히 코드를 짜는 수준을 넘어, 서버에 접속하고 로그를 분석하며 라이브러리 의존성을 해결하는 ‘자율 문제 해결사’ 역할을 할 수 있음을 의미합니다. 소형 모델이기 때문에 CI/CD 파이프라인에 가볍게 통합하여 실시간 코드 리뷰 및 버그 수정을 자동화할 수 있습니다.
6.3 경제적 효율성 및 지속 가능성
거대 모델을 운영하는 데 소요되는 GPU 비용과 전력 소모는 환경적, 경제적으로 큰 부담입니다. Nanbeige4.1-3B는 30B급 모델의 성능을 1/10 수준의 자원으로 제공함으로써, 스타트업이나 중소기업도 고성능 AI 서비스를 낮은 비용으로 구축할 수 있는 길을 열어주었습니다.
7. 한계점 및 기술적 비평 (Discussion: Limitations & Critical Critique)
본 연구가 놀라운 성취를 이루었음에도 불구하고, 몇 가지 비판적 시각을 유지할 필요가 있습니다.
- 시간 복잡도 보상의 일반화 문제: 연구에서 사용된 시간 복잡도 보상($R_{time}$)은 테스트 케이스와 레퍼런스 코드가 존재하는 환경(Competitive Programming)에서는 강력하지만, 정답이 모호한 실무 비즈니스 로직 작성 시에도 동일한 효과를 거둘 수 있을지는 미지수입니다.
- 데이터 합성의 편향성: 딥 서치 파이프라인이 생성한 합성 데이터(Synthetic Data)에 지나치게 의존할 경우, 모델이 실제 인간의 언어적 뉘앙스보다는 ‘기계가 생성한 논리 구조’에 매몰될 위험이 있습니다. 이는 창의적 글쓰기나 감성적 상호작용에서의 성능 저하로 이어질 수 있습니다.
- 600턴의 실질적 가치: 600회의 도구 호출이 가능하다는 수치는 인상적이지만, 실제 사용자 환경에서 600번의 상호작용이 일어날 동안 오차가 누적(Error Accumulation)되지 않고 최종 목적지에 도달하는 ‘성공률(Success Rate)’에 대한 더 세밀한 분석이 필요합니다.
8. 결론 (Conclusion & Insight)
Nanbeige4.1-3B는 “작은 모델도 위대할 수 있다”는 사실을 기술적으로 증명했습니다. 3B 파라미터라는 제약 조건 하에서 강화학습의 설계와 데이터의 질적 개선을 통해 도달한 성취는, 향후 SLM 개발의 새로운 표준(New Normal)을 제시하고 있습니다.
특히 시간 복잡도를 고려한 코드 RL과 장기 에이전트 시뮬레이션 기법은 단순히 성능 지표를 높이는 것을 넘어, AI가 실질적인 업무 현장에서 ‘도구’로서 얼마나 유능하게 쓰일 수 있는지를 보여줍니다. 우리는 이제 모델의 ‘크기’가 아닌 ‘밀도’와 ‘정렬’의 시대에 살고 있으며, Nanbeige4.1-3B는 그 시대를 여는 가장 앞선 주자 중 하나가 될 것입니다.
개발자와 기업 경영자들은 이제 거대 모델에만 매달릴 것이 아니라, Nanbeige4.1-3B와 같은 고성능 소형 모델을 어떻게 자사 서비스에 특화(Fine-tuning)하여 경제적이고 강력한 에이전트를 구축할지 고민해야 할 시점입니다.
