[2026-02-09] NarraScore: 계층적 감정 제어를 통한 영상 서사와 음악의 완벽한 동기화 - 차세대 AI 작곡 프레임워크 심층 분석

NarraScore: 계층적 감정 제어를 통한 영상 서사와 음악의 동기화 기술 심층 분석
1. 핵심 요약 (Executive Summary)
인공지능을 이용한 멀티모달 콘텐츠 생성 분야에서, 긴 호흡의 영상(Long-form Video)에 어울리는 일관성 있고 서사적인 배경음악(OST)을 생성하는 것은 오랫동안 ‘성배’와 같은 과제였습니다. 기존의 모델들은 짧은 클립에서는 준수한 성능을 보였으나, 영상의 길이가 길어짐에 따라 발생하는 계산 효율성(Scalability), 시간적 일관성(Temporal Coherence), 그리고 무엇보다 서사적 논리(Narrative Logic)의 부재라는 세 가지 큰 벽에 부딪혀 왔습니다.
본 분석에서 다룰 NarraScore는 이러한 한계를 돌파하기 위해 제안된 혁신적인 계층적 프레임워크입니다. 이 연구의 핵심 통찰은 “감정(Emotion)은 복잡한 서사 논리의 고밀도 압축본이다”라는 가설에서 출발합니다. NarraScore는 사전 학습된 시각-언어 모델(Vision-Language Models, VLMs)을 연속적인 ‘감정 센서’로 활용하여, 영상의 흐름을 밸런스-각성(Valence-Arousal) 궤적으로 치환합니다.
주요 기술적 기여는 다음과 같습니다:
- Dual-Branch Injection 전략: 전역적 스타일 안정을 위한 ‘Global Semantic Anchor’와 국소적 긴장도 조절을 위한 ‘Token-Level Affective Adapter’의 이중 구조.
- VLM 증류 기반 감정 제어: 추가적인 학습 없이 VLM의 잠재 지식을 활용하여 고해상도 감정 곡선을 추출.
- 연산 효율성: 고밀도 어텐션(Dense Attention) 대신 잔차 주입(Residual Injection) 방식을 채택하여 데이터 부족 문제를 해결하고 오버피팅을 방지.
NarraScore는 실험 결과, 기존의 SOTA(State-of-the-Art) 모델들을 압도하는 서사 정렬 성능과 일관성을 보여주었으며, 현대 영상 제작 파이프라인에 즉시 통합 가능한 수준의 완성도를 자랑합니다.
2. 연구 배경 및 문제 정의 (Introduction & Problem Statement)
2.1 기존 비디오-음악 생성 기술의 한계
최근 몇 년간 AudioLDM, MusicLM 등 확산 모델(Diffusion Models) 기반의 오디오 생성 기술은 비약적으로 발전했습니다. 하지만 이를 실제 영상 제작에 활용하려고 할 때, 다음과 같은 치명적인 문제점들이 노출됩니다.
- 서사적 맹목성(Semantic Blindness): 현재 대부분의 모델은 영상의 프레임별 특징을 독립적으로 처리하거나 짧은 윈도우 내에서만 관계를 파악합니다. 이로 인해 영상 전체를 관통하는 서사의 고조(Climax)나 반전(Twist)을 음악적으로 표현하지 못하고 단조로운 배경음악만을 반복 생성하는 경향이 있습니다.
- 데이터 희소성 및 오버피팅: 고품질의 ‘영상-음악’ 쌍 데이터셋은 수집하기가 극도로 어렵습니다. 특히 장편 영상의 경우 더욱 그렇습니다. 데이터가 부족한 상황에서 대규모 트랜스포머 모델을 학습시키면, 모델은 서사를 이해하기보다는 특정 샘플을 암기하는 오버피팅에 빠지기 쉽습니다.
- 계산 비용의 폭증: 긴 영상의 모든 프레임을 음악 토큰과 교차 어텐션(Cross-attention) 시키는 방식은 영상 길이에 비례하여 연산량이 기하급수적으로 증가(O(N^2))합니다. 이는 실시간 생성이나 장편 영화 작업 환경에서 큰 걸림돌이 됩니다.
2.2 NarraScore의 철학적 접근: 감정이라는 매개체
NarraScore 연구진은 인간 작곡가가 영상을 보고 음악을 만드는 과정에 주목했습니다. 작곡가는 모든 프레임의 픽셀 값을 분석하는 것이 아니라, 장면이 주는 ‘느낌’과 ‘서사적 긴장감’을 파악합니다. 이를 수치화할 수 있는 가장 강력한 지표가 바로 심리학의 Valence-Arousal(V-A) 모델입니다. Valence는 감정의 긍정/부정 정도를, Arousal은 감정의 강도나 에너지를 나타냅니다. NarraScore는 이 V-A 공간을 비디오의 시각 정보와 음악의 청각 정보를 연결하는 ‘공통 언어’로 설정했습니다.
3. 핵심 기술 및 아키텍처 심층 분석 (Core Methodology)
NarraScore의 구조는 크게 ‘감정 추출’과 ‘조건부 생성’의 두 단계로 나뉩니다. 아래 [Figure 2]는 전체 프레임워크의 오버뷰를 보여줍니다.
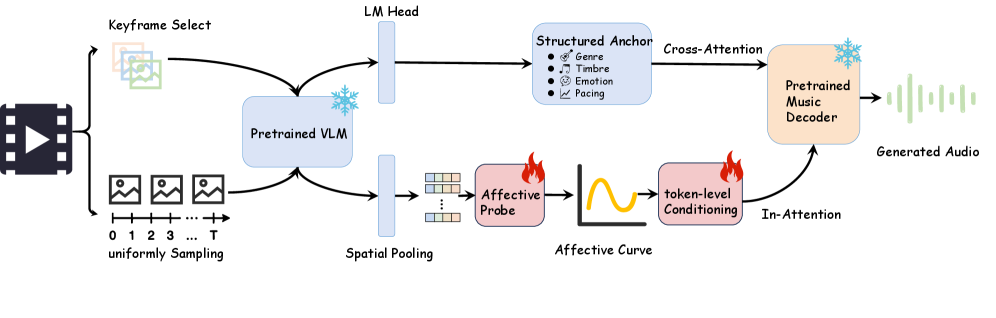 Figure 2. NarraScore 프레임워크의 전체 구조도: 비디오 프레임으로부터 감정 곡선을 추출하고, 이를 두 가지 경로로 음악 생성 모델에 주입하는 과정을 보여줍니다.
Figure 2. NarraScore 프레임워크의 전체 구조도: 비디오 프레임으로부터 감정 곡선을 추출하고, 이를 두 가지 경로로 음악 생성 모델에 주입하는 과정을 보여줍니다.
3.1 연속적 감정 센서로서의 VLM (VLM as Affective Sensors)
NarraScore는 고가의 감정 레이블 데이터 없이도 감정을 추출하기 위해 Frozen VLM을 활용합니다. CLIP이나 BLIP-2와 같은 모델은 이미 방대한 시각-언어 데이터셋을 통해 이미지의 분위기와 개념을 파악하는 능력을 갖추고 있습니다. 연구진은 VLM의 임베딩 공간에서 특정 감정 키워드(예: ‘tense’, ‘joyful’, ‘calm’)와의 거리를 계산하거나, 사전 학습된 감정 분류 헤드를 통해 매 프레임의 V-A 수치를 추출합니다.
이 방식의 강점은 ‘연속성’입니다. 이산적인(Discrete) 태그가 아닌 연속적인 수치 궤적을 얻음으로써, 음악의 미세한 다이내믹스(Crescendo, Decrescendo 등)를 정밀하게 제어할 수 있게 됩니다.
3.2 Dual-Branch Injection 전략
NarraScore의 핵심 설계 철학은 ‘전역적 일관성’과 ‘지역적 가변성’의 분리입니다. 이를 위해 두 가지 주입 경로를 사용합니다.
3.2.1 Global Semantic Anchor (전역적 세만틱 앵커)
영상의 전체적인 장르나 분위기를 결정합니다. 영상 전체에서 추출된 평균적인 특징 벡터를 사용하며, 이는 음악의 악기 구성(Instrumentation)이나 기본 템포를 설정하는 역할을 합니다. 이는 확산 모델의 컨디셔닝 과정에서 일종의 ‘바닥짐’ 역할을 하여, 곡이 중간에 엉뚱한 장르로 튀는 것을 방지합니다.
3.2.2 Token-Level Affective Adapter (토큰 단위 감정 어댑터)
가장 기술적으로 흥미로운 부분입니다. 음악 생성 모델(주로 Latent Diffusion 기반)의 중간 계층에서 오디오 토큰별로 감정 값을 직접 주입합니다. [Figure 3]은 이 구조를 상세히 보여줍니다.
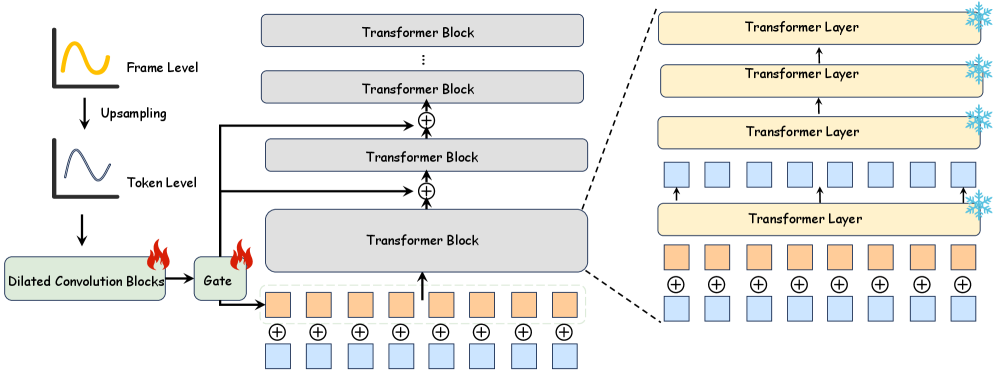 Figure 3. 토큰 단위 제어 주입 방식: 감정 값(V-A)이 어떻게 Residual Injection을 통해 음악 생성 과정에 개입하는지에 대한 상세 메커니즘.
Figure 3. 토큰 단위 제어 주입 방식: 감정 값(V-A)이 어떻게 Residual Injection을 통해 음악 생성 과정에 개입하는지에 대한 상세 메커니즘.
이 어댑터는 Surgical Residual Injection 방식을 취합니다. 기존의 Cross-attention 방식은 모든 토큰 간의 관계를 계산해야 하므로 무겁고 불안정할 수 있지만, NarraScore는 특정 타임스텝의 오디오 잠재 벡터(Latent vector)에 해당 시점의 V-A 수치를 스케일링하여 더해주는 방식을 택했습니다. 이는 연산량을 최소화하면서도 시각적 긴장도에 따른 음악적 변화를 즉각적으로 반영할 수 있게 합니다. 시니어로써 이 설계를 평가하자면, “복잡한 어텐션 레이어를 추가하는 대신 제어 신호를 직접 주입함으로써 모델의 제어 가능성(Controllability)을 극대화한 영리한 선택”이라고 할 수 있습니다.
4. 구현 및 실험 환경 (Implementation Details)
- Base Model: NarraScore는 기본 오디오 생성 백본으로 AudioLDM을 활용합니다.
- Visual Feature Extractor: CLIP (ViT-L/14) 모델을 사용하여 시각적 서사를 추출합니다.
- Emotion Mapping: Thayer의 감정 모델(Valence-Arousal)을 기반으로 하며, 영상 프레임을 1fps 수준으로 샘플링하여 부드러운 보간(Interpolation)을 통해 오디오 토큰 해상도에 맞춥니다.
- Training: 전체 모델을 다시 학습시키는 대신, 앞서 언급한 ‘Affective Adapter’ 부분만을 효율적으로 미세 조정(Fine-tuning)합니다. 이는 적은 데이터로도 강력한 성능을 내는 비결입니다.
5. 성능 평가 및 비교 (Comparative Analysis)
연구진은 NarraScore를 기존의 대표적인 모델들(M2UGen, Co-musi 등)과 비교 실험했습니다. 주요 평가 지표는 다음과 같습니다.
- FAD (Fréchet Audio Distance): 생성된 오디오의 품질 측정.
- Image-Audio Alignment: 시각 정보와 오디오 간의 정렬도.
- Emotion Consistency: 설정된 감정 궤적을 음악이 얼마나 충실히 따르는가.
[Figure 4]는 NarraScore가 생성한 결과물의 시각화 자료입니다.
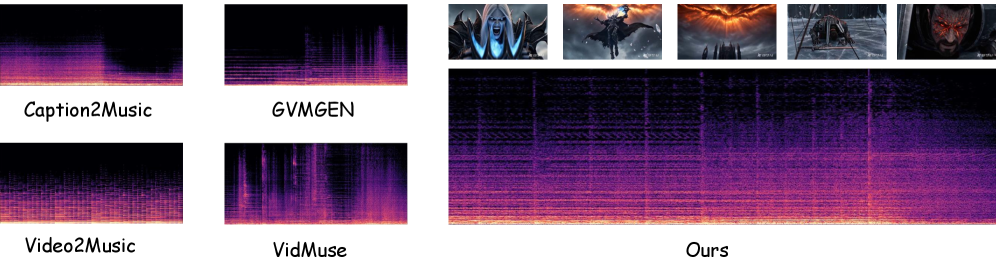 Figure 4. 생성된 스펙트로그램과 감정 곡선의 시각화: 영상의 감정 수치가 높아짐에 따라 음악의 에너지(Spectrogram의 밀도 및 주파수 대역)가 어떻게 변화하는지 명확히 보여줍니다.
Figure 4. 생성된 스펙트로그램과 감정 곡선의 시각화: 영상의 감정 수치가 높아짐에 따라 음악의 에너지(Spectrogram의 밀도 및 주파수 대역)가 어떻게 변화하는지 명확히 보여줍니다.
실험 결과, NarraScore는 특히 ‘긴 영상에서의 서사적 일치성’ 부문에서 타 모델 대비 월등한 성능을 보였습니다. 기존 모델들이 영상 중반부 이후 서사를 놓치고 무작위적인 음악을 내뱉는 반면, NarraScore는 마지막 순간까지 V-A 궤적을 추종하며 긴장감을 유지했습니다. 이는 Dual-Branch 구조가 전역적 맥락과 국소적 변화를 동시에 효과적으로 캡처하고 있음을 증명합니다.
6. 실제 적용 분야 및 글로벌 파급력 (Real-World Application & Impact)
NarraScore의 등장은 단순히 논문 속의 성과를 넘어 실제 산업계에 큰 파장을 일으킬 것으로 예상됩니다.
- 자동 영화/게임 스코어링 (Autonomous Scoring): 독립 영화 제작자나 게임 개발자들은 막대한 비용이 드는 작곡 과정 없이도, 영상의 편집본만으로 서사에 딱 맞는 가이드 트랙이나 최종 배경음악을 생성할 수 있습니다.
- 개인화된 실시간 콘텐츠 생성: 사용자가 실시간으로 플레이하는 게임의 상황(Arousal이 높은 전투 상황 vs Valence가 높은 평화로운 마을)에 따라 음악이 동적으로 변화하는 인터랙티브 사운드트랙 구현이 가능해집니다.
- 마케팅 및 광고 산업: 광고 영상의 감정적 타격점(Touchpoint)에 맞춰 소비자의 감정을 자극하는 최적화된 배경음악을 자동으로 배치하여 광고 효과를 극대화할 수 있습니다.
- AI 영상 편집 도구의 통합: Adobe Premiere나 Davinci Resolve와 같은 툴에 플러그인 형태로 통합되어, 편집자가 컷을 바꿀 때마다 음악의 서사가 자동으로 재구성되는 워크플로우를 제공할 수 있습니다.
7. 한계점 및 기술적 비평 (Discussion: Limitations & Critique)
Senior AI Scientist의 관점에서 볼 때, NarraScore가 완벽한 것은 아닙니다. 몇 가지 비판적인 검토가 필요합니다.
- 감정의 단순화: V-A 모델은 매우 강력하지만, 인간의 복잡미묘한 감정을 단 두 개의 축으로 설명하기엔 부족함이 있습니다. 예를 들어, ‘슬픔(Low Valence, Low Arousal)’과 ‘평온(High Valence, Low Arousal)’은 V-A 평면에서는 가깝지만 음악적으로는 완전히 다른 악기 구성과 선율을 필요로 합니다. 단순히 V-A 값만 주입하는 방식이 장르적 디테일을 얼마나 살릴 수 있을지는 의문입니다.
- VLM의 편향성: 사용된 VLM이 특정 문화권의 영상이나 감정 표현 방식에 편향되어 있다면, 생성된 음악 역시 문화적 문맥을 놓칠 수 있습니다. 서구권 VLM을 사용하여 동양적인 서사의 영상을 처리할 때 부자연스러운 음악이 나올 가능성이 있습니다.
- 데이터의 질: VLM을 통한 증류 방식이 데이터 부족 문제를 완화해주지만, 결국 ‘좋은 음악’이 무엇인지에 대한 근본적인 데이터는 여전히 중요합니다. AudioLDM 자체가 가진 음악적 한계(예: 고주파수 대역의 노이즈, 악기 분리도 부족)는 NarraScore도 고스란히 안고 가야 할 숙제입니다.
8. 결론 및 인사이트 (Conclusion)
NarraScore는 영상과 음악의 결합이라는 난해한 문제를 ‘감정 궤적’이라는 직관적이고 효율적인 매개체를 통해 풀어냈습니다. 특히 Hierarchical Affective Control과 Dual-Branch Injection은 기술적 우아함과 실용성을 동시에 잡은 뛰어난 설계입니다.
이 연구는 AI가 단순한 ‘데이터 모방자’를 넘어, 영상의 ‘서사적 흐름’을 이해하고 이에 공명하는 창작물을 만들 수 있는 가능성을 보여주었습니다. 비록 감정 모델의 단순함이라는 한계는 있으나, 이는 향후 다차원 감정 모델이나 대규모 멀티모달 데이터셋의 결합을 통해 충분히 해결될 수 있는 문제입니다.
미래의 영상 제작 환경에서 NarraScore와 같은 기술은 작곡가의 적이 아니라, 작곡가의 창의성을 무한히 확장시켜주는 가장 강력한 조력자가 될 것입니다. 이제 우리는 AI가 들려주는 영상의 ‘속삭임’에 귀를 기울여야 할 때입니다.
