[2026-02-25] [NoLan 리뷰] LVLM 환각(Hallucination), 범인은 눈(Vision)이 아니라 뇌(언어모델)였다?

요즘 LLaVA나 Qwen-VL 같은 멀티모달 모델(LVLM) 많이들 써보셨죠? 그런데 가끔 이미지에 있지도 않은 물체를 있다고 뻔뻔하게 우기는 ‘환각(Hallucination)’ 현상 때문에 실무에 붙이려다 뒷목 잡은 경험, 다들 한 번쯤 있으실 겁니다.
우리는 흔히 “비전 인코더가 이미지를 제대로 못 봐서”라고 생각하기 쉽습니다. 하지만 이 논문은 완전히 다른 도발적인 주장을 던집니다. “비전 인코더는 죄가 없다. 범인은 언어 모델의 굳어진 편향(Language Priors)이다”라고 말이죠. 솔직히 처음엔 ‘이게 진짜일까?’ 싶었는데, 실험 결과를 보니 꽤나 충격적이네요.
📖 논문 메타데이터
- 📖 논문: arXiv:2602.22144
- 🖥️ Github: https://github.com/lingfengren/NoLan
- 📅 발표일: 2026년 2월
- ✍️ 저자/기관: Lingfeng Ren 외
💡 한 마디로? 멀티모달의 환각은 비전 인코더의 인식 오류가 아니라 언어 모델의 강력한 사전 지식 때문이며, 이를 ‘텍스트 전용 디코딩’과의 비교를 통해 동적으로 억제해내는 학습 불필요(Training-free) 방법론입니다.
🕵️♂️ 무엇이 문제였나? (백설공주와 6난쟁이)
문제를 직관적으로 이해해 볼까요?
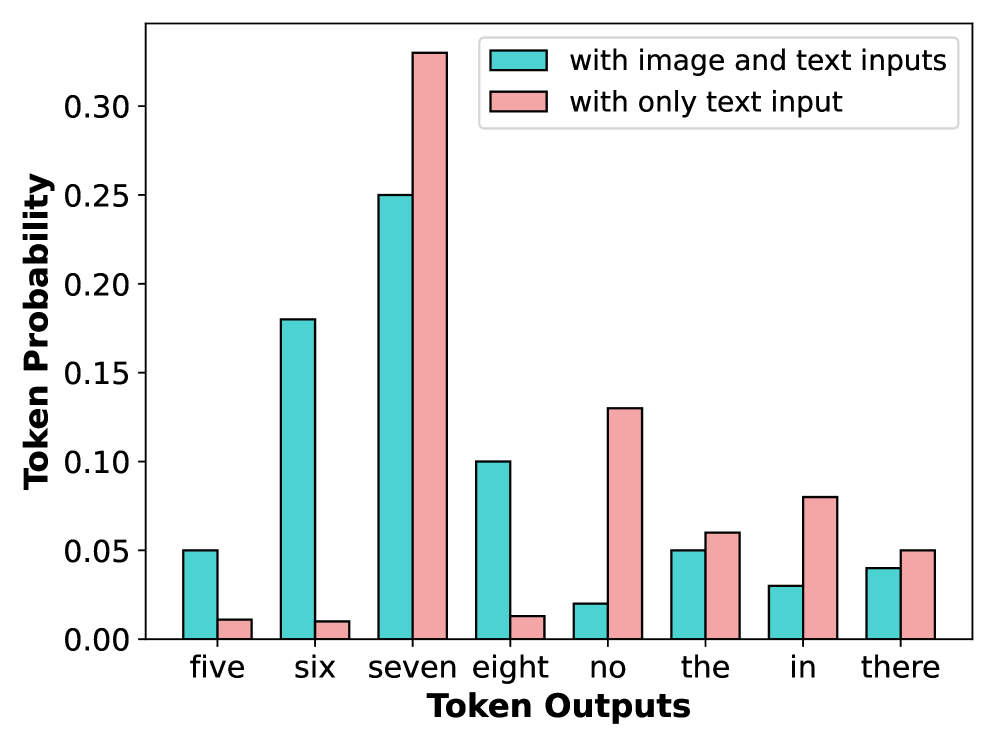
 저자들의 뼈 때리는 예시. 이미지를 안 보고도 ‘일곱’ 난쟁이라고 우기는 언어 모델의 똥고집을 잘 보여줍니다.
저자들의 뼈 때리는 예시. 이미지를 안 보고도 ‘일곱’ 난쟁이라고 우기는 언어 모델의 똥고집을 잘 보여줍니다.
위 그림을 보면 백설공주 앞에 난쟁이가 분명 6명밖에 없습니다. 그런데 LLaVA에게 물어보면 “7명”이라고 대답해요. 왜 그럴까요?
🔹 언어 모델의 편향(Priors): “백설공주와…“라는 텍스트를 보는 순간, 언어 모델은 기존에 학습된 방대한 텍스트 데이터의 관성 때문에 무조건 “일곱 난쟁이”를 떠올립니다. 🔹 무시당하는 시각 정보: 비전 인코더가 “야, 내 눈엔 6명인데?”라고 신호를 줘도, 거대한 언어 모델의 뇌피셜이 시각 정보를 그대로 덮어버리는 겁니다.
연구진은 이를 증명하기 위해 재미있는 실험을 설계했습니다. 비전 인코더가 진짜 물체를 못 보는 건지 떼어내서 테스트해 본 거죠.
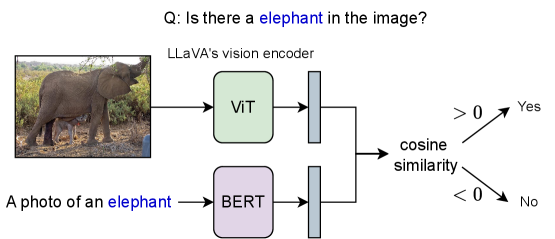 비전 인코더의 억울함을 풀어주는 실험. 인코더는 사실 다 보고 있었습니다.
비전 인코더의 억울함을 풀어주는 실험. 인코더는 사실 다 보고 있었습니다.
🚀 핵심 무기: NoLan, 어떻게 해결했나?
그럼 이 ‘언어 모델의 뇌피셜’을 어떻게 잠재울까요? 저자들이 제안한 NoLan (No-Language-Hallucination Decoding)은 매우 심플하고 우아합니다.
간단히 말해, 멀티모달(이미지+텍스트)로 나온 예측값에서 텍스트만 주고 나온 예측값(뇌피셜)을 빼버리는 겁니다. 이 방식이 실무적으로 왜 중요한지 표로 정리해 봤습니다.
| 비교 항목 | 기존 일반 디코딩 (Standard) | 🚀 NoLan 디코딩 | 실무적 의미 |
|---|---|---|---|
| 환각 개선 (POPE 기준) | 기본 수준 | 최대 +7.21 상승 | 의료, 자율주행 등 환각에 민감한 도메인 적용 가능성 ↑ |
| 추가 학습 (Fine-tuning) | 필요 (환각을 줄이려면) | 전혀 불필요 (Training-free) | 모델 가중치를 건드릴 필요가 없어 배포가 매우 쉬움 |
| 추론 속도 (Inference) | 빠름 (1x Forward) | 느림 (~2x Forward) | 텍스트 전용 패스가 추가되므로 실시간 서비스에는 부담 |
| 구현 복잡도 | - | 매우 낮음 | Logits 처리 코드 몇 줄만 수정하면 됨 |
🛠️ 기술적 딥다이브 (매우 간단함)
로직은 정말 허무할 정도로 간단합니다.
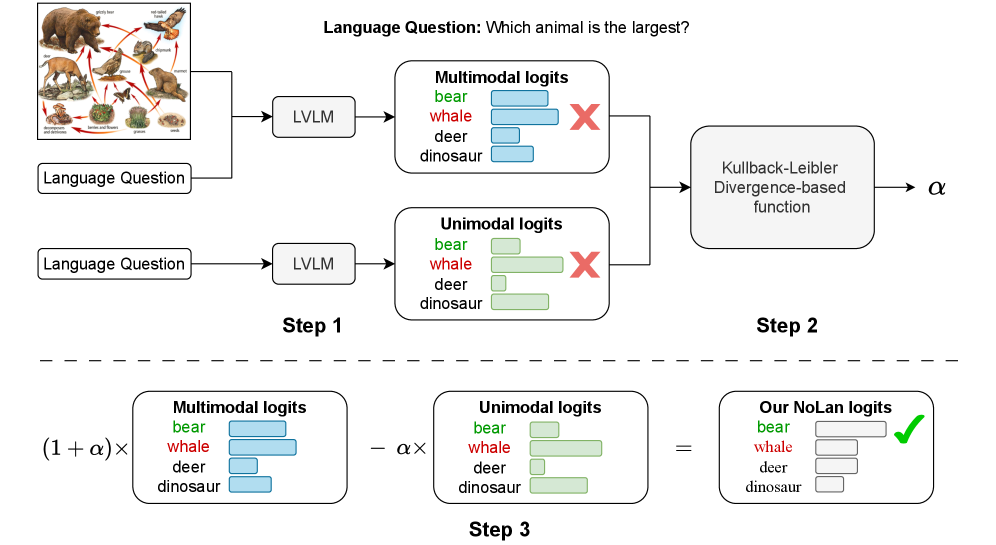 이 논문의 핵심 아이디어. 텍스트만 줬을 때 튀어나오는 ‘고래(whale)’라는 토큰의 확률을 페널티로 줘서 찍어 누릅니다.
이 논문의 핵심 아이디어. 텍스트만 줬을 때 튀어나오는 ‘고래(whale)’라는 토큰의 확률을 페널티로 줘서 찍어 누릅니다.
이걸 코드로 구현한다고 치면 아래와 같은 형태가 될 겁니다. 복잡한 수식 없이 직관적인 논리죠.
1
2
3
4
5
6
7
8
9
10
11
12
13
# Pseudo-code for NoLan Decoding
def nolan_step(image, text_prompt, alpha=1.0):
# 1. 멀티모달(이미지+텍스트) 로짓 계산 (기본 출력)
logits_mm = model(image=image, text=text_prompt)
# 2. 텍스트 단일 로짓 계산 (언어 모델의 뇌피셜 측정)
logits_text = model(image=None, text=text_prompt)
# 3. 언어 편향 억제 (Dynamic Suppression)
# alpha는 동적으로 조절 가능 (멀티모달과 텍스트의 분포 차이 기반)
logits_nolan = logits_mm - alpha * logits_text
return decode(logits_nolan)
기존에도 대조 디코딩(Contrastive Decoding) 방법론들이 존재했지만, LVLM의 환각이 ‘언어 모듈’ 때문이라는 것을 명확히 타겟팅해서 텍스트 전용 입력을 대조군으로 삼았다는 것이 가장 큰 차별점입니다.
🔥 에디터의 생각 (Editor’s Verdict)
- 👍 장점 (Pros): 솔직히 이 부분은 놀랍네요. 복잡한 RLHF나 고품질 데이터셋 구축 없이, 디코딩 타임의 로짓(Logit) 연산 조작만으로 LLaVA-1.5 7B와 Qwen-VL 7B의 성능을 무려 6~7점 이상 끌어올렸다는 건 엄청난 가성비입니다.
- 👎 아쉬운 점 (Cons): 하지만, 실무 B2C 서비스에 당장 적용하기엔 무리가 있어 보입니다. 왜냐하면 매 토큰을 생성할 때마다 ‘멀티모달 패스’와 ‘텍스트 전용 패스’ 두 번의 Forward 연산이 필요하니까요. 연산량(Compute)이 거의 두 배로 뛰기 때문에 API 서비스에 붙이려면 레이턴시(Latency) 최적화 이슈를 겪을 겁니다.
💡 총평: ⭐⭐⭐⭐ (4/5) “NLP 및 비전 AI 엔지니어라면 반드시 읽어봐야 할 강력한 인사이트! 실시간 챗봇 서비스보다는, 속도보다 정확도가 생명인 배치(Batch) 파이프라인이나 오프라인 VQA 데이터 정제용으로 당장 써먹기 좋은 무기입니다.”
Additional Figures
 **
**
