[2026-02-11] 로봇 지능의 비약적 도약: RISE, '상상력'을 통한 자가 개선 정책과 구성적 세계 모델 심층 분석

로봇 지능의 비약적 도약: RISE, ‘상상력’을 통한 자가 개선 정책과 구성적 세계 모델 심층 분석
1. Executive Summary (핵심 요약)
최근 로보틱스 분야는 시각-언어-행동(Vision-Language-Action, VLA) 모델의 발전으로 거대한 전환점을 맞이하고 있습니다. 그러나 기존 VLA 모델들은 물리적 접촉이 빈번하거나 동적인 환경에서 실행 오차가 누적되어 실패하는 고질적인 ‘취약성(Brittleness)’ 문제를 안고 있었습니다. 본 블로그 포스트에서는 이러한 한계를 극복하기 위해 제안된 RISE(Self-Improving Robot Policy with Compositional World Model) 프레임워크를 심층 분석합니다.
RISE의 핵심은 크게 두 가지입니다. 첫째, 구성적 세계 모델(Compositional World Model)을 통해 멀티뷰 미래 영상을 예측하고 현재 상태의 가치를 평가합니다. 둘째, 실세계 상호작용 없이 오직 상상 공간(Imaginary Space)에서의 롤아웃을 통해 정책을 자가 개선(Self-Improvement)합니다. 실험 결과, RISE는 동적 벽돌 분류(+35%), 백팩 패킹(+45%), 박스 닫기(+35%) 등 고난도 작업에서 기존 모델을 압도하는 성능 향상을 보여주었습니다. 이는 로봇이 물리적 위험이나 비용 없이 스스로 학습하고 정교해질 수 있는 새로운 패러다임을 제시합니다.
2. Introduction & Problem Statement (연구 배경 및 문제 정의)
2.1. VLA 모델의 한계: 왜 ‘상상’이 필요한가?
RT-2, OpenVLA와 같은 대규모 VLA 모델은 방대한 데이터를 통해 일반화 능력을 확보했지만, 실제 물리적 환경에서의 정밀한 제어에는 여전히 한계를 보입니다. 특히 다음과 같은 세 가지 문제가 치명적입니다.
- 오차의 복리 효과(Compounding Errors): 작은 실행 편차가 누적되어 최종적으로 전체 작업의 실패로 이어집니다.
- 데이터의 희소성: 복잡하고 정교한 조작 작업에 대한 고품질 데이터는 수집하기 매우 어렵습니다.
- 물리적 환경의 제약: 강화 학습(RL)은 이론적으로 강력하지만, 실세계에서의 시행착오(Trial-and-error)는 하드웨어 파손 위험, 높은 시간적 비용, 그리고 매번 환경을 초기화해야 하는 번거로움을 동반합니다.
2.2. 해결책으로서의 세계 모델 (World Model)
연구진은 인간이 새로운 도전을 할 때 머릿속으로 결과를 ‘시뮬레이션’해 본다는 점에 주목했습니다. 로봇 역시 물리적 시도 이전에 자신의 행동 결과를 예측하고 그 가치를 판단할 수 있다면, 안전하고 효율적인 학습이 가능할 것입니다. RISE는 이러한 ‘상상의 루프’를 구성적 설계로 풀어내어 로봇 정책의 견고함을 극대화합니다.
3. Core Methodology (핵심 기술 및 아키텍처 심층 분석)
RISE의 아키텍처는 크게 Compositional World Model (CWM)과 Self-Improving Loop로 나뉩니다.
3.1. Compositional World Model (구성적 세계 모델)
RISE는 세계 모델을 하나의 거대한 모델로 처리하지 않고, 역할에 따라 두 개의 독립적이지만 상호 보완적인 모듈로 나눕니다. 이것이 바로 ‘Compositional(구성적)’ 설계의 핵심입니다.
- Controllable Dynamics Model (동역학 모델): 멀티뷰 카메라 입력과 로봇의 행동(Action chunks)을 받아 미래의 시각적 변화를 예측합니다. 여기서 Diffusion Transformer(DiT) 기반의 아키텍처를 사용하여 시공간적으로 일관된 고화질 영상을 생성합니다.
- Progress Value Model (진행 가치 모델): 생성된 미래 영상이 목표 달성에 얼마나 기여했는지를 평가합니다. 이는 RL의 Reward 함수 역할을 하며, 정책 개선을 위한 유익한 ‘어드밴티지(Advantage)’ 신호를 제공합니다.
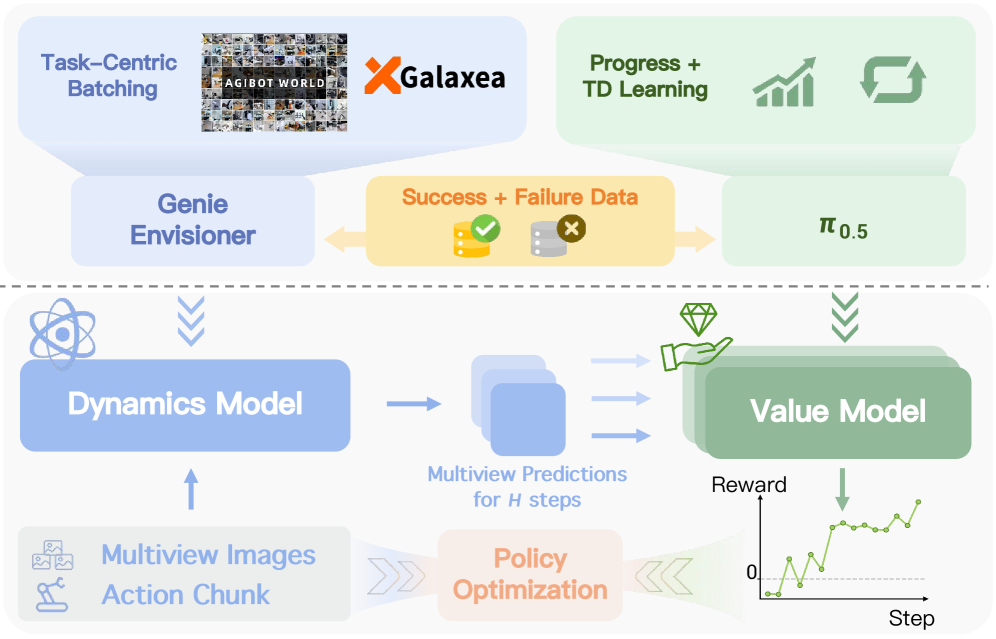 이 그림은 CWM의 워크플로우를 보여줍니다. 상단은 학습 과정을, 하단은 추론 및 정책 최적화를 위한 보상 샘플 생성 과정을 나타냅니다.
이 그림은 CWM의 워크플로우를 보여줍니다. 상단은 학습 과정을, 하단은 추론 및 정책 최적화를 위한 보상 샘플 생성 과정을 나타냅니다.
3.2. 자가 개선 루프 (Self-Improving Loop)
RISE는 학습된 세계 모델 안에서 수천 번의 가상 롤아웃을 실행합니다. 이 과정은 다음과 같은 단계로 진행됩니다.
- Step 1: Rollout: 현재 정책이 세계 모델 내에서 행동을 취하고, 모델은 그 결과를 상상합니다.
- Step 2: Advantage Estimation: 가치 모델이 각 상상된 경로의 성과를 평가하여 어드밴티지를 계산합니다.
- Step 3: Policy Update: 높은 어드밴티지를 얻은 행동 궤적을 기반으로 정책을 업데이트합니다. 특히 ‘Advantage-Conditioning’ 기법을 사용하여, 높은 성과가 예상되는 행동을 우선적으로 학습하도록 유도합니다.
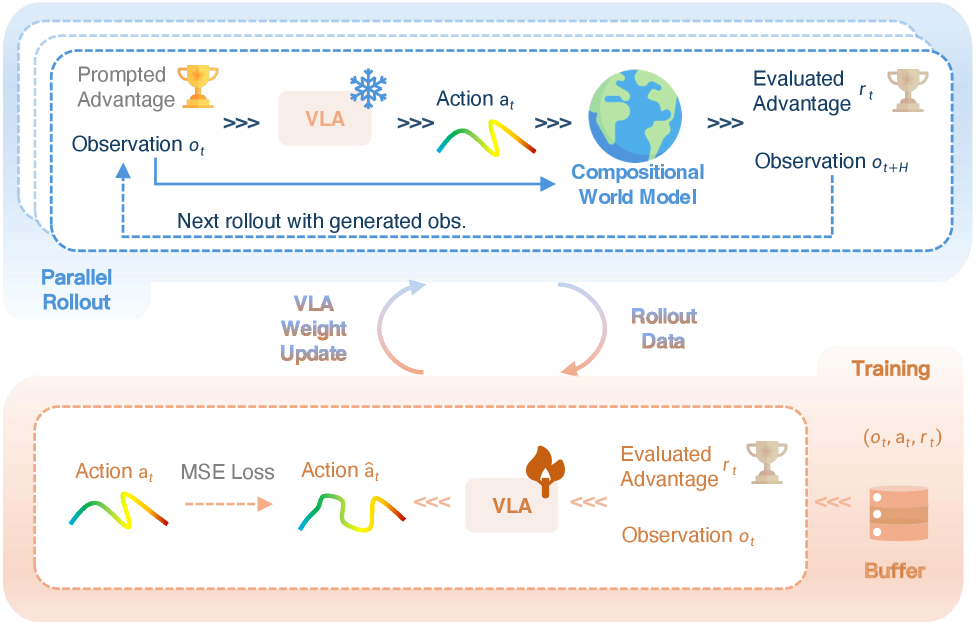 상상 공간 내에서의 자가 개선 루프 구조. 물리적 상호작용 없이 데이터 효율성을 극대화하는 핵심 메커니즘입니다.
상상 공간 내에서의 자가 개선 루프 구조. 물리적 상호작용 없이 데이터 효율성을 극대화하는 핵심 메커니즘입니다.
4. Implementation Details & Experiment Setup (구현 및 실험 환경)
RISE의 성능을 검증하기 위해 연구진은 세 가지 매우 도전적인 실세계 과제를 설정했습니다. 이는 단순한 집기(Pick-and-place)를 넘어선 고차원의 조작 능력을 요구합니다.
- Dynamic Brick Sorting: 움직이는 컨베이어 벨트 위에서 특정 색상의 벽돌을 분류하여 지정된 통에 넣어야 합니다. 높은 동적 반응성이 필요합니다.
- Backpack Packing: 배낭을 열고, 옷을 넣고, 들어 올린 뒤 지퍼를 채우는 복합적인 과정입니다. 유연 물체(Deformable objects) 조작 능력이 필수적입니다.
- Box Closing: 상자의 날개를 접고 탭을 정밀하게 끼워 넣는 작업으로, 아주 작은 오차도 허용되지 않는 정밀 제어가 요구됩니다.
 RISE의 성능을 테스트한 세 가지 실세계 작업 환경.
RISE의 성능을 테스트한 세 가지 실세계 작업 환경.
5. Comparative Analysis (성능 평가 및 비교)
5.1. 정성적 분석: 세계 모델의 품질
RISE의 동역학 모델은 기존의 Cosmos나 Genie Envisioner와 같은 최신 비디오 생성 모델과 비교했을 때 물리적 일관성 면에서 월등한 성능을 보입니다. 기존 모델들이 물체의 형태가 일그러지거나 동작이 흐릿해지는(Motion blurring) 반면, RISE는 멀티뷰 시점 간의 정합성을 유지하며 매우 사실적인 상상을 수행합니다.
![Figure 6:Qualitative Comparison on Dynamics Models.Cosmos[1]and Genie Envisioner[59]suffer from geometric distortion, motion blurring, and physical inconsistency, whereas our method showcases temporally coherent and physically consistent results with Ground Truth (GT).](https://www.opsoai.com/assets/img/papers/2602.11075/x6.png) 기존 모델 대비 RISE의 동역학 예측 우수성 비교. 기하학적 왜곡이 적고 물리적으로 타당한 예측을 수행합니다.
기존 모델 대비 RISE의 동역학 예측 우수성 비교. 기하학적 왜곡이 적고 물리적으로 타당한 예측을 수행합니다.
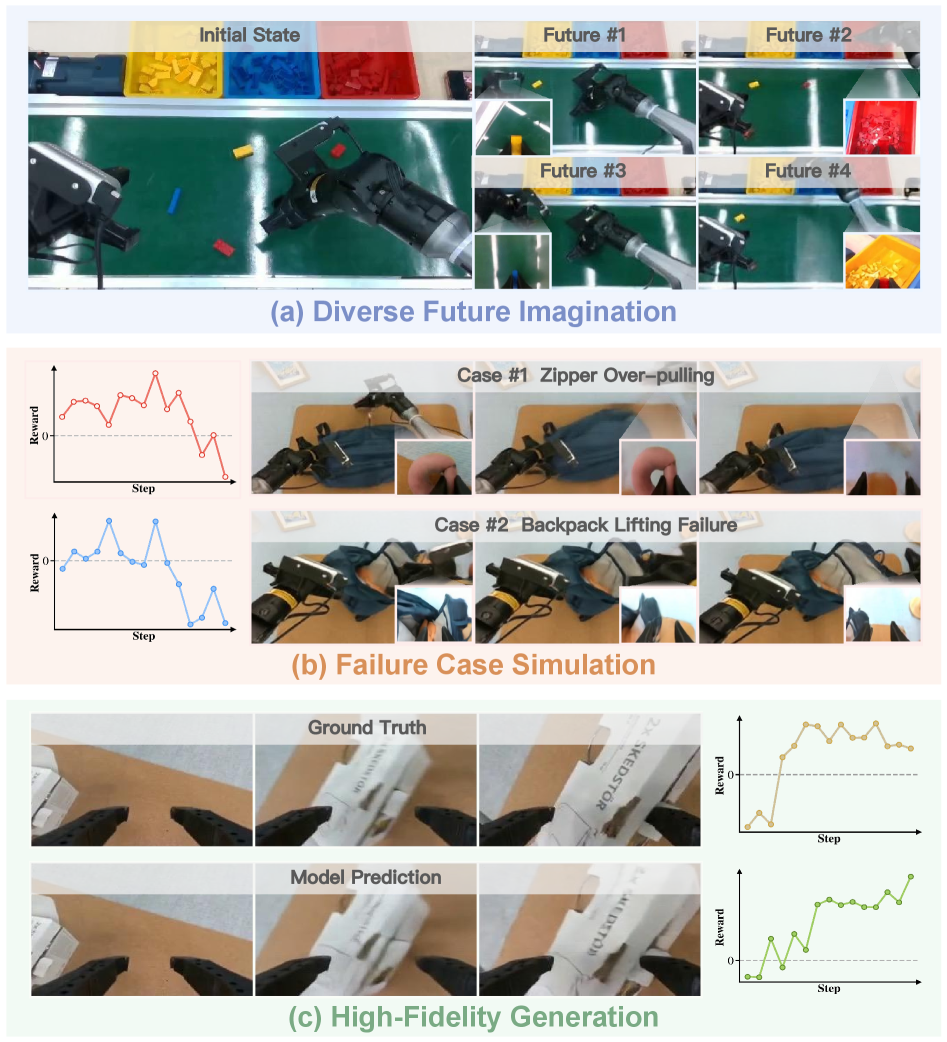 RISE가 상상한 다양한 미래 시나리오. 성공 사례와 실패 사례를 모두 예측하여 정책 학습의 가이드 역할을 합니다.
RISE가 상상한 다양한 미래 시나리오. 성공 사례와 실패 사례를 모두 예측하여 정책 학습의 가이드 역할을 합니다.
5.2. 정량적 분석: 성능 향상 폭
- Dynamic Brick Sorting: 기준 모델 대비 +35%의 절대 성능 향상을 기록했습니다. 컨베이어의 속도 변화에 대한 대응력이 크게 개선되었습니다.
- Backpack Packing: 지퍼 채우기와 같은 고난도 작업에서 +45%의 향상을 보였습니다. 이는 유연 물체 제어에 있어 세계 모델을 통한 학습이 얼마나 효과적인지 증명합니다.
- Box Closing: 정밀 조작 영역에서 +35%의 성공률 향상을 달성했습니다.
6. Real-World Application & Impact (실제 적용 분야 및 파급력)
RISE 프레임워크는 단순히 연구실 수준의 성과를 넘어 산업계 전반에 큰 파급력을 미칠 것으로 기대됩니다.
- 지능형 물류 시스템: 급변하는 컨베이어 벨트 환경이나 무작위로 쌓인 물품을 분류하는 작업에 즉각 투입 가능합니다. 특히 새로운 물품이 추가되어도 상상 학습을 통해 빠르게 적응할 수 있습니다.
- 가사 로봇: 배낭 정리, 박스 포장과 같은 가사 노동은 물체의 형태가 가변적이라 자동화가 어려웠습니다. RISE는 이러한 ‘Soft robotics’ 관점의 난제들을 해결할 실마리를 제공합니다.
- 정밀 제조: 정밀한 부품 조립 및 체결 작업에서 작업자의 시연 데이터가 부족하더라도 로봇 스스로 시뮬레이션을 통해 최적의 궤적을 찾아낼 수 있습니다.
7. Discussion: Limitations & Critical Critique (한계점 및 기술적 비평)
Senior Chief AI Scientist로서 본 논문에 대해 비판적인 시각을 덧붙이자면 다음과 같습니다.
- 모델 표류(Model Drift)의 위험: 상상 공간에서의 롤아웃이 길어질수록 세계 모델의 예측 오차가 누적되어 실제 물리 법칙과 괴리된 ‘환각(Hallucination)’ 학습이 발생할 수 있습니다. RISE는 이를 어드밴티지 기반 학습으로 완화하려 했으나, 장기적인(Long-horizon) 과제에서는 여전히 모델 피델리티 유지가 핵심 과제입니다.
- 추론 비용: DiT 기반의 동역학 모델과 VLM 기반의 가치 모델을 동시에 실행하는 것은 상당한 연산 자원을 소모합니다. 실시간 자가 개선(On-the-fly self-improvement)을 위해서는 모델 경량화와 가속 기술이 뒷받침되어야 합니다.
- 가치 모델의 편향: 가치 모델 자체가 초기 데이터셋의 편향을 학습했다면, 잘못된 행동에 높은 어드밴티지를 줄 위험이 있습니다. ‘잘못된 상상’이 ‘잘못된 정책’으로 이어지는 루프를 어떻게 완벽히 차단할 것인가에 대한 더 깊은 연구가 필요합니다.
8. Conclusion (결론 및 인사이트)
RISE는 로보틱스가 직면한 ‘데이터 기근’과 ‘실세계 학습의 위험성’이라는 두 마리 토끼를 ‘구성적 세계 모델을 통한 상상력’으로 잡아낸 탁월한 연구입니다. 특히 분산된 아키텍처를 통해 예측과 평가를 최적화하고, 이를 다시 정책 개선에 반영하는 폐쇄 루프(Closed-loop) 시스템은 향후 일반 목적 로봇(General-Purpose Robots) 개발에 있어 표준적인 방법론이 될 가능성이 높습니다.
로봇이 스스로 상상하고, 실패를 미리 겪어보며, 그로부터 배우는 시대가 도래했습니다. RISE는 그 시대의 문을 여는 중요한 열쇠가 될 것입니다.”} ```
