[2026-03-19] 외부 VLM 의존도는 버려라. 비디오 편집의 시맨틱과 모션을 완벽히 쪼갠 SAMA 파이프라인 해부

[Metadata]
- Paper: SAMA: Factorized Semantic Anchoring and Motion Alignment for Instruction-Guided Video Editing
- ID: 2603.19228
- Link: https://arxiv.org/abs/2603.19228
인스트럭션 기반 비디오 편집(Instruction-Guided Video Editing)을 한 번이라도 서비스 레벨에서 돌려본 분들은 알 겁니다. 강아지를 고양이로 바꾸라는 프롬프트를 주면, 고양이로 바뀌긴 하는데 배경이 일그러지거나 프레임 사이의 모션이 뚝뚝 끊기죠. 시맨틱(의미적 변환)과 모션(일관성)을 동시에 잡는 건 지옥 같은 일입니다.
지금까지 업계의 해결책은 무식했습니다. 외부 VLM(Vision-Language Model)의 피처를 억지로 주입하거나, ControlNet 같은 구조적 조건(Depth, Edge)을 덕지덕지 발라버렸죠. 결과는 어땠을까요? 모델의 유연성은 박살 나고, 일반화 능력은 떨어지며, GPU VRAM은 터져나갑니다.
SAMA(Factorized Semantic Anchoring and Motion Alignment)는 이 멍청한 패러다임을 정면으로 뒤집습니다. 무거운 외부 조건부에 의존하는 대신, 비디오 편집을 시맨틱 앵커링(Semantic Anchoring)과 모션 정렬(Motion Alignment)이라는 두 가지 독립적인 축으로 완전히 쪼개버렸죠.
💡 TL;DR: 외부 VLM과 ControlNet을 버리고, 원본 비디오 자체에 Pretext Task(마스킹, 셔플링 등)를 걸어 모션과 시맨틱을 분리 학습시켜 제로샷 SOTA를 찍은 아키텍처.
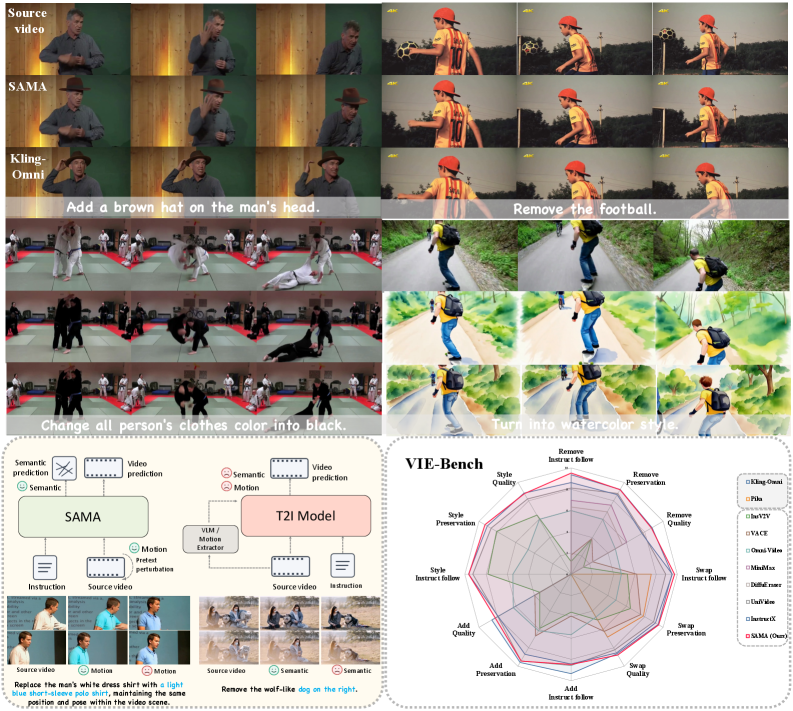 Figure 1: SAMA의 성능 비교와 파이프라인 개요. 기존의 상용 모델(Kling-Omni)과 비벼볼 만한 수준의 일관성을 VLM 없이 달성했다는 점이 핵심입니다.
Figure 1: SAMA의 성능 비교와 파이프라인 개요. 기존의 상용 모델(Kling-Omni)과 비벼볼 만한 수준의 일관성을 VLM 없이 달성했다는 점이 핵심입니다.
⚙️ 시맨틱과 모션의 이혼 소송: SAMA의 투트랙 파이프라인 해부
기존 모델들은 한 번의 Forward Pass 안에서 ‘무엇을 바꿀지’와 ‘어떻게 움직일지’를 동시에 처리하려다 가랑이가 찢어졌습니다. SAMA는 이걸 두 개의 스테이지와 두 개의 태스크로 우아하게 분리합니다.
🔹 Semantic Anchoring (무엇을 바꿀 것인가?) 전체 프레임을 다 건드리지 않습니다. 아주 희소한(Sparse) 앵커 프레임만 골라서, 텍스트 인스트럭션에 맞게 시맨틱 토큰과 비디오 레이턴트를 결합해 구조적 플래닝을 수행합니다. 이렇게 하면 모델이 불필요한 프레임 간섭 없이 ‘어떤 형태가 되어야 하는지’에만 집중할 수 있죠.
🔹 Motion Alignment (어떻게 움직일 것인가?) 이 논문의 백미입니다. SAMA는 비디오의 시간적 동역학(Temporal Dynamics)을 배우기 위해, 원본 비디오에 장난을 치는 Pretext Tasks(사전 학습 과제)를 도입합니다. 큐브 인페인팅(Cube Inpainting), 속도 교란(Speed Perturbation), 튜브 셔플(Tube Shuffle)을 통해 모델이 스스로 복원하며 모션을 내재화하게 만듭니다.
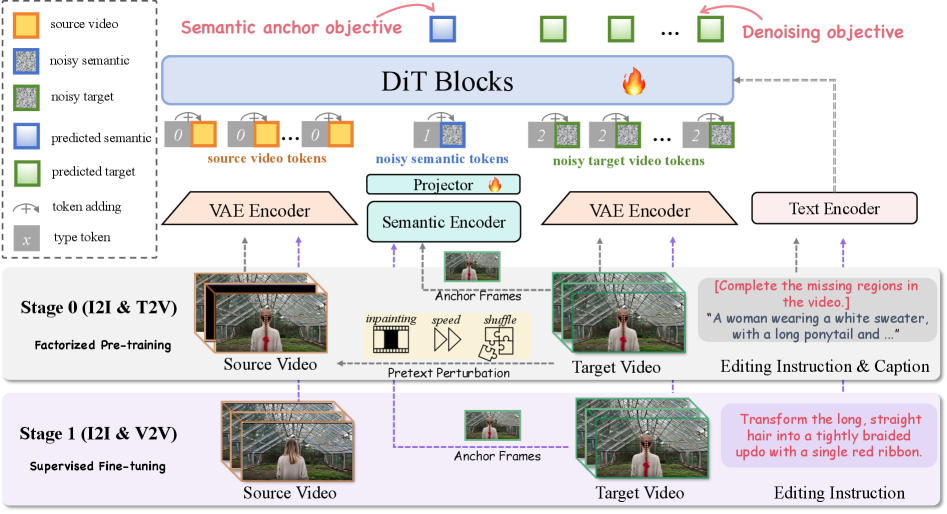 Figure 2: Stage 0(Factorized Pre-training)과 Stage 1(Supervised Fine-tuning)으로 나뉜 전체 파이프라인. 쌍을 이루는 편집 데이터 없이도 Stage 0만으로 모션을 학습하는 구조가 인상적입니다.
Figure 2: Stage 0(Factorized Pre-training)과 Stage 1(Supervised Fine-tuning)으로 나뉜 전체 파이프라인. 쌍을 이루는 편집 데이터 없이도 Stage 0만으로 모션을 학습하는 구조가 인상적입니다.
이게 코드로 구현되면 어떤 느낌일지, 데이터 콜레이터(Data Collator) 레벨에서 모션 교란이 어떻게 일어나는지 러프한 의사 코드(Pseudo-code)로 살펴보죠.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# [Mock Code] SAMA의 Motion Alignment를 위한 Tube Shuffle Pretext Task
def apply_tube_shuffle(video_latents, tube_size=4):
"""
video_latents: [B, C, F, H, W] (F=Frames)
시간축(F)을 tube_size 단위로 청크를 나눈 뒤 무작위로 섞어버림.
"""
B, C, F, H, W = video_latents.shape
assert F % tube_size == 0, "Frames must be divisible by tube_size"
# 프레임을 튜브 단위로 리쉐이프: [B, C, F//tube_size, tube_size, H, W]
tubes = video_latents.view(B, C, F // tube_size, tube_size, H, W)
# 시간축(idx=2)을 기준으로 랜덤 셔플링 인덱스 생성
shuffle_idx = torch.randperm(F // tube_size)
# 튜브 셔플 적용 및 원래 형태로 복원
shuffled_tubes = tubes[:, :, shuffle_idx, :, :, :]
shuffled_video = shuffled_tubes.view(B, C, F, H, W)
# 모델은 이 뒤죽박죽된 비디오를 원본 흐름에 맞게 복원해야 함 (Motion Alignment)
return shuffled_video
이 코드가 시사하는 바는 명확합니다. 수만 장의 ‘Instruction-Video’ 페어 데이터셋을 구축할 필요 없이, 넘쳐나는 Raw 비디오만으로도 모델이 ‘물리적 움직임’을 완벽히 이해하도록 훈련시킬 수 있다는 겁니다.
 Figure 3: 모델을 괴롭히는 세 가지 방법(Cube inpainting, Speed perturbation, Tube shuffle). 모델은 이 교란을 원래대로 돌려놓으면서 세상의 물리 법칙(모션)을 깨닫게 됩니다.
Figure 3: 모델을 괴롭히는 세 가지 방법(Cube inpainting, Speed perturbation, Tube shuffle). 모델은 이 교란을 원래대로 돌려놓으면서 세상의 물리 법칙(모션)을 깨닫게 됩니다.
⚔️ 기존 스택(VLM+ControlNet) vs SAMA 패러다임: 내 인프라 비용은 얼마나 줄어들까?
그렇다면 프로덕션 환경에서 이 녀석을 서빙할 때 어떤 차이가 발생할까요? 기존의 무거운 스택과 SAMA의 구조를 표로 직관적으로 비교해 보겠습니다.
| 비교 지표 | 기존 SOTA (VLM + ControlNet 기반) | SAMA 프레임워크 |
|---|---|---|
| 아키텍처 복잡도 | Base Diffusion + ControlNet + VLM | Single Diffusion Backbone |
| 의존성 (External Priors) | 높음 (Depth/Edge 추출기, VLM 필수) | 없음 (자체 Pretext Task로 내재화) |
| VRAM 사용량 (추론 시) | 매우 높음 (24GB+ GPU 여러 대 필요) | 상대적으로 낮음 (단일 모델 서빙) |
| Paired Data 요구량 | 천문학적 (Instruction-Video 쌍 필요) | Stage 0에서 Unpaired Raw Video 활용 |
| 제로샷 편집 능력 | 제한적 (학습된 프롬프트 도메인에 종속) | 우수함 (Stage 0만으로도 강력함) |
표를 보면 인프라 팀이 환호할 포인트가 보입니다. 기존 방식은 사용자 요청 하나를 처리하기 위해 비디오의 Depth를 뽑고, VLM으로 피처를 추출한 뒤, 디퓨전 모델에 태우는 길고 무거운 파이프라인을 거쳐야 했습니다. API 호출 비용과 딜레이가 장난이 아니죠.
반면 SAMA는 백본 자체가 비디오의 동역학을 이해하고 있으므로, 파이프라인이 극단적으로 단순해집니다. 추론 시점에서는 그냥 인스트럭션 텍스트와 원본 비디오만 밀어 넣으면 됩니다.
 Figure 4: 다른 SOTA 모델들과의 정성적 비교. SAMA는 타 모델 대비 배경의 왜곡(Motion bleed) 없이 타겟 객체의 시맨틱만 날카롭게 바꿔냅니다.
Figure 4: 다른 SOTA 모델들과의 정성적 비교. SAMA는 타 모델 대비 배경의 왜곡(Motion bleed) 없이 타겟 객체의 시맨틱만 날카롭게 바꿔냅니다.
🚀 내일 당장 프로덕션에 도입한다면?
이 프레임워크가 실무에 떨어졌을 때 우리가 써먹을 수 있는 시나리오는 굉장히 구체적입니다.
1. 자동화된 비디오 광고 생성기 (A/B 테스트용) 의류 브랜드나 자동차 회사의 마케팅 팀을 생각해보세요. 동일한 배경과 동일한 주행 모션을 유지하면서, 자동차의 텍스처나 색상만 수백 가지로 바꾸는 작업을 요청할 겁니다. 기존 모델은 색상을 바꾸면 바퀴의 굴러가는 모션이 깨지곤 했습니다. SAMA는 시맨틱 앵커링 덕분에 텍스처만 갈아끼우고 모션은 Stage 0에서 배운 물리 법칙을 그대로 유지하므로, 완벽한 A/B 테스트용 숏폼 영상을 공장처럼 찍어낼 수 있습니다.
2. 로우 리소스 환경의 제로샷 비디오 번역 API 스타트업 환경에서는 고가의 Paired Video Editing 데이터셋을 살 돈이 없습니다. SAMA의 진가는 Stage 0(Factorized Pre-training)에 있습니다. 인터넷에 널린 수백만 시간의 블랙박스 영상이나 CCTV 영상을 긁어와서 Tube Shuffle, Cube Inpainting만 돌려놔도 모델이 해당 도메인의 ‘움직임’을 완벽히 마스터합니다. 이후 소량의 데이터로 Stage 1만 거치면 특정 도메인에 특화된 비디오 편집 API를 뚝딱 만들 수 있죠.
 Figure 5: Stage 0만 거쳤을 때의 제로샷 편집 결과. 놀랍게도 페어 데이터(Instruction-Video) 없이 원본 비디오 교란 학습만으로도 이런 편집이 가능하다는 걸 증명했습니다.
Figure 5: Stage 0만 거쳤을 때의 제로샷 편집 결과. 놀랍게도 페어 데이터(Instruction-Video) 없이 원본 비디오 교란 학습만으로도 이런 편집이 가능하다는 걸 증명했습니다.
🧐 Tech Lead’s Honest Verdict
솔직히 까놓고 평가해보겠습니다.
장점 (Pros): 비디오 모델링에서 VLM과 ControlNet을 걷어냈다는 것 자체가 혁명적입니다. NLP에서 쓰던 Masked Language Modeling(MLM) 개념을 비디오의 시간축에 적용해(Tube Shuffle 등) 모션을 내재화한 건 박수받아 마땅합니다. 덕분에 인프라 비용은 줄고 파이프라인은 깔끔해졌습니다.
단점 (Cons): 논문 말미에 적혀 있는 마법의 문장, “Code, models, and datasets will be released.” 우리는 이 말이 뜻하는 바를 잘 압니다. 당장 내일 써볼 수 없다는 뜻이죠. 게다가 Stage 0의 Pre-training이 얼마나 많은 GPU 시간을 갈아 넣었는지에 대한 명확한 인프라 청구서(Compute Cost)가 빠져 있습니다. 커스텀 데이터로 Stage 0를 바닥부터 다시 돌리려면 스타트업 수준에서는 감당 안 될 수도 있습니다.
최종 판정 (Final Verdict): “Github에 코드가 풀리는 즉시 클론해서 사내 토이 프로젝트로 돌려봐라.” 특히 VLM 기반의 비디오 파이프라인 때문에 VRAM 부족으로 고통받고 있던 엔지니어라면, SAMA의 Pretext Task 로직만이라도 기존 사내 모델에 이식해 볼 가치가 충분합니다. 시맨틱과 모션은 애초에 이혼했어야 할 개념이니까요.
