[2026-03-12] [ShotVerse] 아직도 프롬프트로 카메라 워킹을 기도하시나요? 텍스트를 3D 궤적으로 컴파일하는 'Plan-then-Control' 패러다임

Link: arxiv:2603.11421 Authors: ShotVerse Team Date: March 2026
어제 최신 비디오 생성 모델 테스트를 하다가 키보드를 부술 뻔했습니다. 프롬프트에 분명히 “피사체를 중심으로 360도 오빗(Orbit) 회전한 뒤, 타이트한 클로즈업 샷으로 컷 전환(Cut)”이라고 적었는데, 결과물은 어땠을까요? 카메라는 바보처럼 제자리에 멈춰 있고, 피사체의 얼굴만 기괴하게 일그러지며 줌인 되더군요.
이게 현재 잘 나간다는 SOTA(State-of-the-Art) 비디오 모델들의 뼈아픈 현실입니다. Sora2, Kling3.0, VEO3 모두 화질은 기가 막히지만, 공간 지각 능력은 처참합니다. 텍스트라는 추상적인 개념을 픽셀 단위의 물리적 카메라 워킹으로 1:1 매핑하려니 모델이 파업을 선언하는 거죠. 그렇다고 개발자가 직접 수동으로 $SE(3)$ 카메라 매트릭스(Trajectory)를 좌표 값으로 한 땀 한 땀 입력하는 건 말도 안 되는 노가다입니다.
여기서 등장한 게 바로 오늘 뜯어볼 ShotVerse입니다. 이들은 “텍스트에서 픽셀로 직행하는 무식한 짓은 그만두자”고 선언합니다. 대신 텍스트를 정밀한 3D 카메라 궤적으로 먼저 컴파일(Plan)하고, 그 궤적을 바탕으로 비디오를 렌더링(Control)하는 방식을 들고 나왔습니다.
한 줄 요약: 추상적인 텍스트 프롬프트를 명시적인 3D 카메라 궤적으로 번역하는 VLM 플래너와, 이를 픽셀로 구워내는 DiT 컨트롤러의 완벽한 분업. 하지만 로컬에서 돌리기엔 컴퓨팅 자원이 만만치 않음.
⚙️ VLM과 DiT의 기묘한 동거: ‘Plan-then-Control’은 어떻게 작동하는가?
이 녀석의 아키텍처를 까보면 꽤나 우아한 엔지니어링적 결단이 보입니다. 모든 걸 거대한 모델 하나에 욱여넣는(End-to-End) 최근의 트렌드를 거스르고, 역할을 두 개의 에이전트로 철저히 분리했습니다.
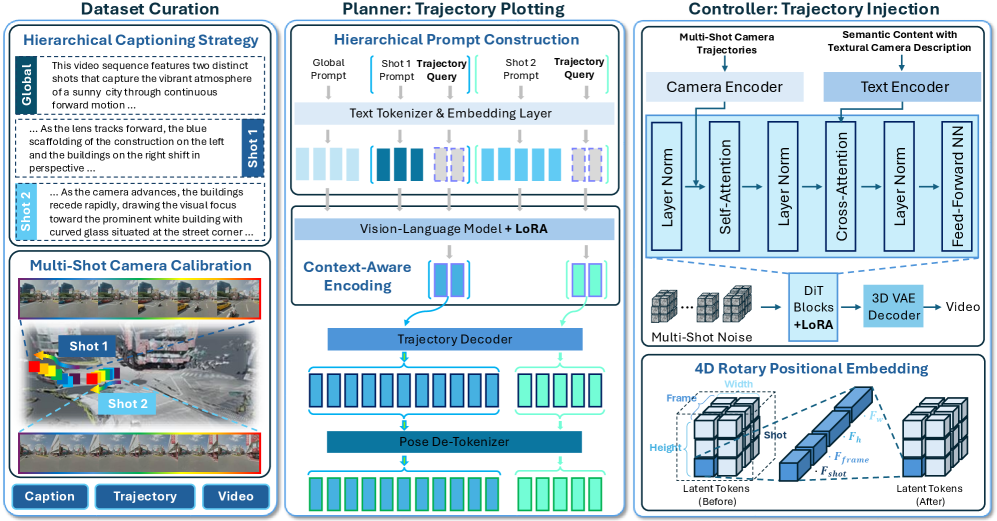 👆 핵심 아키텍처: VLM이 프롬프트를 해석해 카메라 좌표(Trajectory)를 짜주면, 하단의 DiT 컨트롤러가 이 좌표를 따라가며 비디오를 렌더링하는 2단계 구조입니다.
👆 핵심 아키텍처: VLM이 프롬프트를 해석해 카메라 좌표(Trajectory)를 짜주면, 하단의 DiT 컨트롤러가 이 좌표를 따라가며 비디오를 렌더링하는 2단계 구조입니다.
🔹 The Planner (VLM 기반 궤적 컴파일러) 우리가 고수준 언어(Python)를 짜면 컴파일러가 바이트코드로 번역하듯, VLM(Vision-Language Model)이 그 역할을 합니다. 텍스트 프롬프트와 학습 가능한 ‘Trajectory Query Tokens’를 섞어서 입력하면, VLM이 공간적 맥락을 파악해 명시적인 카메라 포즈(Camera Poses) 배열을 뱉어냅니다. 즉, “오빗 샷”이라는 문자가 [R|t] 형태의 수학적 회전/이동 행렬로 변환되는 것이죠.
🔹 The Controller (DiT & Camera Adapter) 이제 궤적을 확보했으니 비디오를 찍을 차례입니다. DiT(Diffusion Transformer) 백본에 ‘Camera Adapter’를 달아서 VLM이 짜준 궤적을 주입(Injection)합니다. 여기서 재밌는 건 4D RoPE(Rotary Positional Embedding)의 도입입니다. 기존 3D 공간의 위치 정보에 ‘시간(Temporal)’과 ‘샷 인덱스(Shot Index)’ 정보까지 엮어서, 컷이 넘어갈 때 피사체가 엉뚱한 곳으로 튀는 현상을 막아줍니다.
🔹 The Secret Sauce: 글로벌 좌표계 캘리브레이션 (ShotVerse-Bench) 사실 이 논문의 진짜 광기는 데이터셋 구축에 있습니다. 기존 모델들이 멀티샷에서 무너지는 이유는 샷 1과 샷 2의 카메라 좌표가 서로 독립적이라 연속성이 없기 때문입니다. 개발팀은 여러 샷의 비디오를 하나의 ‘글로벌 좌표계’로 정렬(Align)하는 자동화 파이프라인을 구축했습니다. (Caption, Trajectory, Video)의 완벽한 삼위일체 데이터를 갈아 넣은 덕분에 모델이 공간의 연속성을 이해하게 된 겁니다.
⚔️ 통제불능의 E2E vs 예측가능한 분업화 (SOTA 비교)
Sora2나 Kling3.0 같은 괴물들과 이 새로운 패러다임을 비교해 볼까요? 개발자 관점에서 이 차이는 단순히 ‘화질’의 문제가 아니라 ‘제어권’의 문제입니다.
 👆 타 모델들과의 비교: “오빗”이라는 복잡한 명령어가 주어졌을 때, 덩치만 큰 최신 모델들은 제자리에 얼어붙는 반면 ShotVerse는 정확하게 카메라를 궤도에 올려 회전시킵니다.
👆 타 모델들과의 비교: “오빗”이라는 복잡한 명령어가 주어졌을 때, 덩치만 큰 최신 모델들은 제자리에 얼어붙는 반면 ShotVerse는 정확하게 카메라를 궤도에 올려 회전시킵니다.
| 비교 지표 | End-to-End 비디오 모델 (Sora2, Kling3.0) | ShotVerse (Plan-then-Control) |
|---|---|---|
| 개발자 경험 (DX) | 가챠(Gacha) 게임. 프롬프트를 미세 조정하며 기우제 지내야 함 | 명확한 API. 궤적이 맘에 안 들면 VLM 단계에서 수정 후 렌더링 가능 |
| 카메라 제어력 | Zoom, Pan 정도의 단순 이동만 근사치로 성공 | Orbit, Dolly-zoom 등 복잡한 시네마틱 궤적 정확도 90% 이상 |
| 멀티샷 연속성 | 컷 전환 시 피사체 외형이 무너지거나 위치가 리셋됨 | 글로벌 좌표계 & 4D RoPE 덕분에 컷 전환 시 공간 연속성 유지 |
| 메모리 / 비용 | 단일 거대 모델 추론 (무겁지만 한 번에 끝남) | VLM 추론 + DiT 렌더링 이중 구조로 VRAM 요구량 및 추론 시간 증가 |
단순히 지표만 보면 추론 시간이 늘어난 것이 단점처럼 보일 수 있습니다. 하지만 실무에선 다릅니다. 클라이언트가 “카메라를 피사체 오른쪽으로 30도만 더 꺾고 컷을 넘겨주세요”라고 했을 때, 기존 모델로는 100번을 다시 돌려야 할 수도 있습니다. ShotVerse 구조라면 VLM이 생성한 좌표값만 살짝 비틀어(Tweak) DiT로 넘기면 끝납니다. 이 제어권의 차이가 프로덕션 도입 여부를 가릅니다.
🚀 내일 당장 프로덕션에 쓸 수 있을까? (Use Cases)
이 아키텍처가 빛을 발하는 구체적인 실무 시나리오를 생각해 봤습니다.
1. 게임 및 영화 프리비주얼(Pre-vis) 파이프라인 인디 게임 스튜디오나 영상 프로덕션에서 스토리보드를 3D 애니메이터에게 넘기기 전, 연출자가 원하는 카메라 워킹을 정확히 시각화해야 할 때 유용합니다. “주인공 어깨 너머로 팔로우 샷 하다가, 문을 열 때 하이앵글로 컷 전환” 같은 텍스트를 입력하면, 정확한 카메라 좌표와 함께 컷씬의 초안이 나옵니다. 이 궤적 데이터(Trajectory)를 그대로 언리얼 엔진의 시퀀서로 임포트하는 툴만 붙이면 완벽한 파이프라인이 완성됩니다.
2. AI 커머셜 영상 자동화 팩토리 제품 광고 영상은 카메라 앵글이 생명입니다. 화장품 병을 360도로 돌려가며 찍거나, 특정 타이밍에 줌인하는 등 정해진 ‘카메라 워킹 템플릿’이 존재합니다. ShotVerse의 컨트롤러(Controller)만 떼어내어 사용한다면, 텍스트가 아닌 사전에 정의된 완벽한 3D 좌표계를 직접 주입하여 일관된 퀄리티의 제품 쇼케이스 영상을 무한히 찍어내는 봇을 구축할 수 있습니다.
 👆 어블레이션 스터디: 캘리브레이션(d)이나 4D RoPE(c) 컴포넌트 중 하나만 빠져도 피사체가 프레임 아웃되거나 샷이 끊어지는 대참사가 발생합니다. 분업화만큼이나 각 모듈의 디테일이 중요하다는 증거죠.
👆 어블레이션 스터디: 캘리브레이션(d)이나 4D RoPE(c) 컴포넌트 중 하나만 빠져도 피사체가 프레임 아웃되거나 샷이 끊어지는 대참사가 발생합니다. 분업화만큼이나 각 모듈의 디테일이 중요하다는 증거죠.
🧐 Tech Lead’s Verdict
ShotVerse의 코드를 보면서 오랜만에 가슴이 뛰었습니다. 생성형 AI가 마법의 블랙박스에서 벗어나, 예측 가능하고 제어 가능한 소프트웨어 엔지니어링의 영역으로 들어오고 있다는 강력한 증거니까요.
장점 (Pros):
- 기우제 방식의 프롬프트 엔지니어링을 끝내고, 궤적(Trajectory)이라는 중간 디버깅 지점을 만들었다는 점.
- 여러 샷의 로컬 좌표를 하나로 묶어낸 데이터 파이프라인 설계는 그 자체로 예술에 가깝습니다.
단점 (Cons):
- VLM과 대형 DiT를 파이프라인으로 연결하다 보니, 개인 머신(RTX 4090 1~2장)에서 가볍게 굴리기엔 메모리 오버헤드가 큽니다.
- VLM 플래너가 궤적을 환각(Hallucination)하여 잘못 짜주면, 뒤에 있는 DiT는 그 쓰레기 좌표를 아주 고해상도로 충실하게 렌더링하는 코미디가 발생합니다. (Garbage in, High-Res Garbage out)
최종 판정: 당장 아키텍처는 훔쳐오고, 경량화 버전을 기다려라 (4.0/5.0) 당장 프로덕션에 원본 그대로 올리기엔 컴퓨팅 비용이 꽤 아픕니다. 하지만 이 ‘Plan-then-Control’ 패러다임 자체는 향후 비디오 AI의 표준이 될 확률이 매우 높습니다. 멀티모달 비디오 서비스를 기획 중인 팀이라면 이 레포지토리의 아키텍처 컨셉만큼은 반드시 벤치마킹하시길 권합니다.
