[2026-02-12] 선 하나로 뒤바뀌는 의미의 마법: Stroke of Surprise와 점진적 시맨틱 일루전의 기술적 심층 분석

1. Executive Summary (핵심 요약)
인간의 시각 시스템은 단순히 사물을 보는 것에 그치지 않고, 맥락에 따라 이미지를 재해석하는 능력을 갖추고 있습니다. ‘토끼-오리 착시’와 같은 고전적인 시각적 일루전은 이러한 인지적 유연성을 공략한 예술적 성취입니다. 하지만 생성 AI 시대에 들어서며, 우리는 공간적 착시를 넘어 ‘시간적’ 혹은 ‘점진적’인 의미의 변화를 구현하려는 시도를 목격하고 있습니다.
본 분석에서 다룰 ‘Stroke of Surprise: Progressive Semantic Illusions in Vector Sketching’ 연구는 벡터 스케치 분야에서 혁신적인 ‘점진적 시맨틱 일루전(Progressive Semantic Illusions, PSI)’이라는 개념을 제안합니다. 이는 하나의 스케치가 그려지는 과정에서, 초기 단계의 획(Stroke)들이 특정 객체(예: 토끼)를 형성하다가, 추가적인 획(Delta strokes)이 더해지는 순간 전혀 다른 새로운 객체(예: 말)로 드라마틱하게 변모하는 기술입니다.
이 기술의 핵심은 ‘이중 제약(Dual-constraint)’의 해결에 있습니다. 초기 획은 단독으로도 완벽한 의미를 가져야 함과 동시에, 미래에 추가될 획들을 위한 ‘구조적 기반’ 역할을 수행해야 합니다. 본 논문은 이를 위해 이중 분기 Score Distillation Sampling (SDS) 메커니즘과 순차 인식 공동 최적화(Sequence-aware Joint Optimization) 프레임워크를 도입했습니다. 또한, 획 간의 간섭을 최소화하고 시각적 명료성을 확보하기 위한 Overlay Loss를 통해 기술적 완성도를 높였습니다. 이는 단순한 생성 모델을 넘어, 시간의 흐름에 따른 시각적 서사를 생성하는 새로운 형태의 AI 예술 도구로서의 가능성을 열어주었습니다.
2. Introduction & Problem Statement (연구 배경 및 문제 정의)
시각적 착시(Visual Illusion)는 오랫동안 예술가와 심리학자들의 관심을 끌어왔습니다. 최근 생성 AI 분야에서는 ‘Visual Anagrams’나 ‘Multi-view Illusions’와 같이 이미지를 회전시키거나 뒤집었을 때 의미가 변하는 연구들이 활발히 진행되었습니다. 하지만 이러한 시도들은 대부분 ‘공간적(Spatial)’ 변형에 국한되어 있었습니다.
본 연구가 주목한 지점은 ‘점진적(Progressive)’인 변화입니다. 우리가 종이 위에 그림을 그릴 때, 선 하나하나가 추가됨에 따라 그림의 정체성이 점차 뚜렷해집니다. 만약 이 과정에서 정체성이 한 번 혹은 여러 번 뒤바뀐다면 어떨까요? 이것이 바로 ‘점진적 시맨틱 일루전(PSI)’의 핵심 아이디어입니다.
기술적으로 PSI를 구현하는 데에는 크게 두 가지의 본질적인 어려움이 존재합니다.
- Semantic Conflict (의미론적 충돌): 초기 단계(Phase 1)의 획들이 후기 단계(Phase 2)의 객체 구조와 모순되지 않아야 합니다. 예를 들어, 오리의 부리가 나중에 양의 귀가 되어야 한다면, 이 부리는 오리처럼 보이면서도 양의 귀로 변환될 수 있는 ‘공통의 구조적 특징’을 가져야 합니다.
- Structural Scaffolding (구조적 비계 설정): 초기 획이 단순히 후기 단계에서 무시되거나 노이즈로 전락해서는 안 됩니다. 초기 획은 후기 객체의 핵심적인 골격 역할을 수행해야 하며, 이를 위해 정교한 최적화 과정이 필요합니다.
기존의 래스터(Raster) 기반 방식이나 단순한 순차적 벡터 생성 방식은 이러한 문제를 해결하지 못합니다.
![Figure 2:Challenges in progressive illusion sketching.(a) Raster-based methods (e.g., Nano Banana Pro) rely ondestructive editing, modifying the initial structure to fit the final target and thus violating the progressive constraint. (b) Vector-based baselines (e.g., SketchDreamer[93]or SketchAgent[110]) employ a greedy strategy, where specific Phase 1 details becomesemantic noiseor clutter in Phase 2. (c) Ours achievesdual-semantic coherencyby jointly optimizing for a common structural subspace, ensuring the initial strokes are valid building blocks for both interpretations (e.g., “rabbit”→\rightarrow“elephant”).](https://www.opsoai.com/assets/img/papers/2602.12280/x2.png) Figure 2: 점진적 일루전 스케칭의 도전 과제. (a) 래스터 기반은 파괴적 편집이 발생하고, (b) 기존 벡터 방식은 노이즈가 발생하지만, (c) 본 제안 방식은 공통 구조 서브스페이스를 찾아내어 두 단계 모두에서 정합성을 유지합니다.
Figure 2: 점진적 일루전 스케칭의 도전 과제. (a) 래스터 기반은 파괴적 편집이 발생하고, (b) 기존 벡터 방식은 노이즈가 발생하지만, (c) 본 제안 방식은 공통 구조 서브스페이스를 찾아내어 두 단계 모두에서 정합성을 유지합니다.
위 그림에서 보듯, 기존 방식들은 초기 구조를 파괴하거나(Raster), 초기 획이 후기 단계에서 지저분한 노이즈가 되는(Greedy Vector) 한계를 보입니다. 본 연구는 이러한 한계를 극복하기 위해 벡터 그래픽스의 미분 가능성(Differentiability)을 활용한 최적화 전략을 택했습니다.
3. Core Methodology (핵심 기술 및 아키텍처 심층 분석)
‘Stroke of Surprise’의 아키텍처는 벡터 획의 파라미터를 직접 최적화하는 방식을 취합니다. 여기서 획은 제어점(Control Points), 두께(Thickness), 투명도(Opacity) 등의 속성을 가진 베지에 곡선(Bezier Curves)으로 정의됩니다.
3.1. Joint Optimization & Dual-branch SDS
가장 핵심적인 혁신은 이중 분기 SDS(Score Distillation Sampling) 가이드입니다. SDS는 사전 학습된 확산 모델(Diffusion Model)의 지식(Score)을 활용하여 생성된 이미지가 특정 텍스트 프롬프트에 부합하도록 그래디언트를 전달하는 기법입니다.
본 모델은 획의 집합을 두 부분으로 나눕니다:
- Prefix Strokes (S_prefix): Phase 1에서 그려지는 획들.
- Delta Strokes (S_delta): Phase 2에서 추가되는 획들.
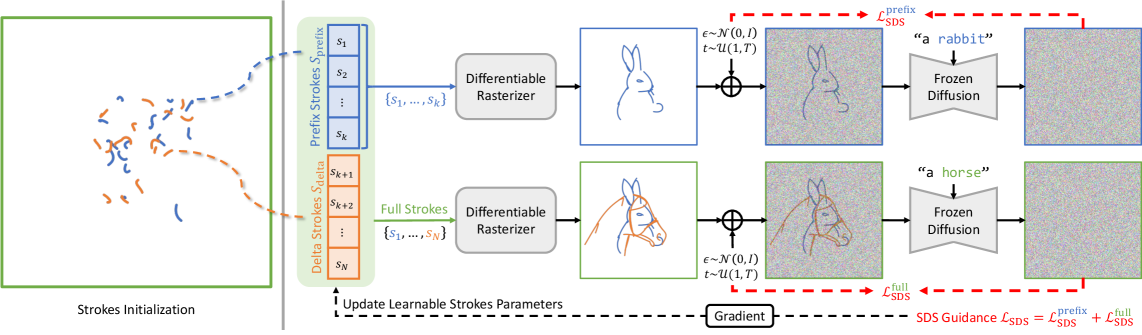 Figure 3: 파이프라인 개요. Prefix Strokes는 단독으로 Phase 1의 프롬프트를 만족하도록 최적화되고, 전체(Full) 획은 Phase 2의 프롬프트를 만족하도록 동시에 최적화됩니다.
Figure 3: 파이프라인 개요. Prefix Strokes는 단독으로 Phase 1의 프롬프트를 만족하도록 최적화되고, 전체(Full) 획은 Phase 2의 프롬프트를 만족하도록 동시에 최적화됩니다.
이 구조의 묘미는 역전파(Backpropagation)에 있습니다. Prefix Strokes는 Phase 1의 손실 함수($\mathcal{L}{\text{SDS}}^{\text{prefix}}$)뿐만 아니라 Phase 2의 손실 함수($\mathcal{L}{\text{SDS}}^{\text{full}}$)로부터도 그래디언트를 전달받습니다. 즉, 초기 획이 결정될 때 이미 ‘미래에 추가될 획’들과 어떻게 조화를 이룰지가 고려되는 것입니다. 이것이 바로 논문에서 강조하는 ‘공통 구조 서브스페이스(Common Structural Subspace)’를 찾는 과정입니다.
3.2. Overlay Loss: 공간적 보완성 확보
단순히 두 단계의 SDS Loss를 합치는 것만으로는 부족합니다. 최적화 과정에서 나중에 추가되는 Delta Strokes가 기존의 Prefix Strokes를 완전히 덮어버리거나(Occlusion), 너무 좁은 공간에 획들이 뭉쳐서 형체를 알아볼 수 없게 되는 문제가 발생하기 때문입니다.
이를 해결하기 위해 저자들은 Overlay Loss를 도입했습니다.
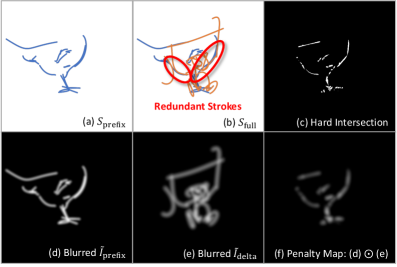 Figure 4: Overlay Loss의 동기 및 수식화. 획들 사이의 물리적 거리를 확보하여 시각적 명료성을 유지하는 메커니즘을 설명합니다.
Figure 4: Overlay Loss의 동기 및 수식화. 획들 사이의 물리적 거리를 확보하여 시각적 명료성을 유지하는 메커니즘을 설명합니다.
이 손실 함수는 Prefix Strokes와 Delta Strokes의 렌더링 맵에 가우시안 블러(Gaussian Blur)를 적용하여 ‘소프트 마스크’를 만든 뒤, 두 영역이 겹치는 부분에 페널티를 부여합니다. 이를 통해 신규 획들이 기존 획 사이의 빈 공간을 효율적으로 활용하도록 유도하며, 결과적으로 두 객체가 구조적으로 ‘통합’되는 효과를 냅니다.
4. Implementation Details & Experiment Setup (구현 및 실험 환경)
본 연구의 구현 세부 사항은 기술적 정교함을 보여줍니다.
- Differentiable Rasterizer: DiffVG를 사용하여 벡터 파라미터에서 렌더링된 이미지로의 미분 가능한 경로를 확보했습니다.
- Diffusion Prior: Stable Diffusion v1.5를 백본으로 사용하였으며, SDS 가이드를 통해 최적화를 수행했습니다.
- Optimization Hyperparameters: 각 단계별로 약 2,000회의 이터레이션을 수행하며, 초기에는 높은 학습률로 구조를 잡고 후반부에는 미세 조정을 진행합니다.
- Stroke Initialization: 초기 획은 캔버스 중앙에 무작위로 배치되거나, 사전 학습된 스케치 모델의 초기값을 활용할 수 있습니다.
실험은 동물, 사물, 심지어 유명 인물의 얼굴(Einstein 등)을 포함한 다양한 프롬프트 쌍에 대해 진행되었습니다. 특히 2단계를 넘어 3단계 이상의 다중 단계(Multi-phase) 일루전까지 확장하여 기술의 범용성을 입증했습니다.
5. Comparative Analysis (성능 평가 및 비교)
성능 평가는 정량적 평가와 정성적 평가, 그리고 최신 VLM(Vision-Language Model)을 활용한 평가까지 다각도로 이루어졌습니다.
5.1. VLM 기반 자동 평가 파이프라인
기존의 CLIP 점수만으로는 ‘일루전의 강도’를 측정하기 어렵습니다. 저자들은 GPT-4o를 평가자로 활용하는 혁신적인 파이프라인을 구축했습니다.
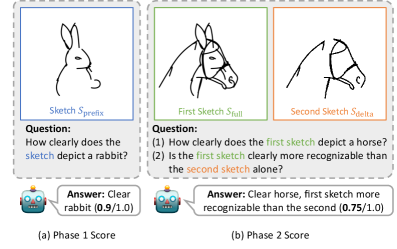 Figure 5: VLM 기반 평가 파이프라인. GPT-4o가 각 단계의 인식 가능성과 초기 획의 기여도를 정밀하게 측정합니다.
Figure 5: VLM 기반 평가 파이프라인. GPT-4o가 각 단계의 인식 가능성과 초기 획의 기여도를 정밀하게 측정합니다.
이 평가 방식은 단순히 최종 결과물이 프롬프트에 맞는지뿐만 아니라, “Prefix Strokes가 Phase 2에서 실질적인 구조적 역할을 수행하고 있는가?”를 묻습니다. 만약 Delta Strokes만으로도 Phase 2 이미지가 완성된다면, 그것은 진정한 일루전이 아니기 때문입니다. 실험 결과, 본 제안 방식은 기존의 SketchDreamer나 SketchAgent보다 압도적으로 높은 일루전 점수를 획득했습니다.
5.2. Multi-phase 확장성
본 기술의 강력함은 다단계 확장 시에도 유지됩니다.
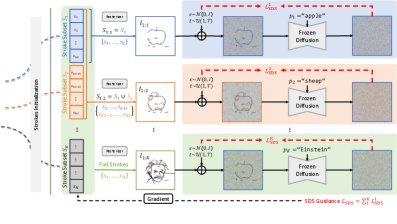 Figure 6: 다단계 파이프라인. ‘사과 -> 양 -> 아인슈타인’과 같이 연속적인 의미 변화를 구현하는 과정을 보여줍니다.
Figure 6: 다단계 파이프라인. ‘사과 -> 양 -> 아인슈타인’과 같이 연속적인 의미 변화를 구현하는 과정을 보여줍니다.
다단계 최적화에서는 $K$개의 누적된 획 집합을 사용하며, 각 단계의 손실 함수가 이전 단계의 획들에 누적되어 반영됩니다. 이는 마치 복잡한 퍼즐을 맞추는 것과 같으며, 공동 최적화(Joint Optimization)가 없으면 달성 불가능한 영역입니다.
6. Real-World Application & Impact (실제 적용 분야 및 글로벌 파급력)
이 연구는 단순한 ‘재미있는 그림 생성’ 이상의 가치를 지닙니다.
- 에듀테인먼트(Edutainment): 아이들을 위한 인터랙티브 드로잉 앱에 적용될 수 있습니다. 특정 동물을 그리다가 선 몇 개를 더하니 전혀 다른 동물이 되는 경험은 창의성 교육에 큰 영감을 줄 것입니다.
- 동적 광고 및 로고 디자인: 고정된 로고가 아닌, 드로잉 과정 자체가 브랜드 스토리를 담고 있는 동적 로고(Dynamic Logo) 제작에 활용될 수 있습니다. 예를 들어 ‘커피 원두’가 그려지다 ‘웃는 얼굴’로 변하는 로고는 소비자에게 강렬한 인상을 남깁니다.
- NFT 및 디지털 아트: 시간의 흐름에 따라 가치가 변하거나 메시지가 변하는 디지털 아트워크의 새로운 장르를 개척할 수 있습니다.
- 벡터 자산 생성의 효율화: 복잡한 일러스트레이션을 생성할 때, 레이어 간의 유기적 관계를 고려하여 최적화된 벡터 자산을 얻는 데 기초 기술로 활용될 수 있습니다.
7. Discussion: Limitations & Critical Critique (한계점 및 기술적 비평)
본 연구는 훌륭한 성과를 거두었지만, 전문가적 시선에서 몇 가지 비판적 검토가 필요합니다.
- SDS의 고질적 문제 (Over-smoothing): 본 논문은 SDS를 기반으로 하기에, 생성된 스케치가 때때로 지나치게 단순화되거나 채도가 과해지는 현상이 발생할 수 있습니다. 최근 제안된 VSD(Variational Score Distillation) 등을 도입했다면 더 정교한 질감 표현이 가능했을 것입니다.
- 획 수의 수동 결정: 각 단계에서 사용될 획의 개수를 사용자가 사전에 정의해야 한다는 점은 한계입니다. 의미의 복잡도에 따라 필요한 획의 수가 다를 텐데, 이를 적응적으로 결정하는 메커니즘이 부재합니다.
- 의미적 거리의 제약: 완전히 상반된 구조를 가진 두 객체(예: 긴 기차와 둥근 공) 사이의 일루전을 만드는 것은 여전히 매우 어렵습니다. 이는 Diffusion 모델이 학습한 형상(Geometry)의 통계적 분포 내에서 ‘공통 분모’를 찾아야 하기 때문인데, 이 범위를 벗어나는 조합에서는 최적화가 불안정해질 가능성이 큽니다.
- 계산 비용: 다단계 최적화로 갈수록 메모리 사용량과 계산 시간이 선형적으로 증가합니다. 실시간 인터랙티브 도구로 쓰이기에는 현재의 최적화 속도는 다소 느린 편입니다.
8. Conclusion (결론 및 인사이트)
‘Stroke of Surprise’는 벡터 그래픽스에 시간적 서사를 부여한 기념비적인 연구입니다. 단순히 결과를 생성하는 AI를 넘어, ‘과정의 예술’을 이해하고 설계할 수 있는 생성 모델의 가능성을 보여주었습니다.
특히 Joint Optimization을 통해 과거와 미래의 시각적 정보를 조율하는 방식은, 향후 비디오 생성이나 애니메이션 최적화 분야에서도 중요한 영감을 줄 것으로 보입니다. 비록 몇 가지 한계가 존재하지만, 시각적 착시라는 고전적인 주제를 최신 생성 AI 기술로 재해석하여 ‘점진적 시맨틱 일루전’이라는 새로운 도메인을 성공적으로 구축했다는 점에서 높은 평가를 받을 만합니다.
앞으로 이 기술이 더욱 발전하여, 우리가 상상하는 모든 사물 사이의 매끄러운 ‘의미적 징검다리’를 놓아줄 수 있기를 기대해 봅니다. AI는 이제 정지된 이미지를 만드는 수준을 넘어, 인간의 인지 과정을 추론하고 그 과정 속에서 ‘놀라움(Surprise)’을 설계하는 단계에 진입하고 있습니다.
