[2026-02-22] TOPReward: VLM의 토큰 확률을 활용한 로보틱스 제로샷 보상 모델의 혁신

[1] Executive Summary: 로보틱스 RL의 게임 체인저
최근 로보틱스 분야에서는 Vision-Language-Action (VLA) 모델의 사전 학습(Pretraining) 기술이 비약적으로 발전하고 있습니다. 하지만 실제 환경에서의 강화학습(Reinforcement Learning)은 여전히 낮은 샘플 효율성과 희소한 보상(Sparse Rewards) 문제에 직면해 있습니다.
TOPReward는 사전 학습된 비디오 VLM(Vision-Language Model)의 내부 토큰 확률(Token Probabilities)을 활용하여 로봇의 작업 진행 상태를 0.947이라는 높은 상관계수(Value-Order Correlation, VOC)로 추정하는 제로샷(Zero-shot) 보상 모델입니다. 별도의 추가 학습 없이 130개 이상의 실제 작업에서 성능을 입증하며, 로봇 제어 정책 최적화의 새로운 지평을 열었습니다.
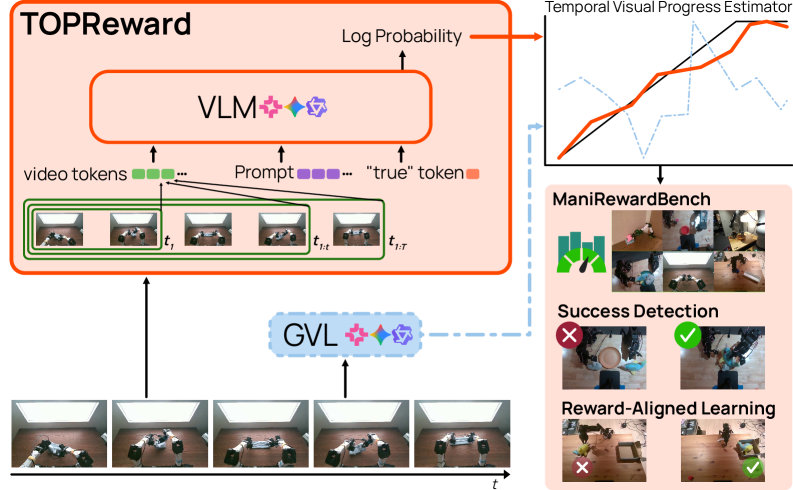 그림 1: 다양한 로봇 플랫폼과 환경에서 제로샷 작업 진행률을 추정하는 TOPReward의 주요 성과.
그림 1: 다양한 로봇 플랫폼과 환경에서 제로샷 작업 진행률을 추정하는 TOPReward의 주요 성과.
[2] 연구 배경 및 문제 정의 (Problem Statement)
기존의 VLA 모델을 강화학습에 적용할 때 가장 큰 병목 현상은 일반화 가능한 프로세스 보상 모델(Process Reward Models)의 부재였습니다.
- 희소 보상 문제: 단순히 작업 완료 여부만 판단하는 이진 보상(Binary Reward)은 에이전트가 복잡한 동작을 학습하기에 정보량이 턱없이 부족합니다.
- 시간적 가치 함수의 한계: 기존의 시간적 가치 함수(Temporal Value Functions)는 학습 데이터 도메인을 벗어나면 성능이 급격히 저하됩니다.
- 수치 표현의 불안정성: 기존 VLM을 활용해 보상을 얻으려 할 때, VLM에게 직접 수치(예: “0.75 진행됨”)를 출력하도록 유도하는 방식은 모델의 수치적 추론 오류(Numerical Misrepresentation)로 인해 신뢰도가 낮습니다.
이러한 배경 하에, 연구진은 VLM의 잠재된 세계 지식(Latent World Knowledge)을 보다 직접적이고 연속적인 방식으로 추출할 방법을 고민하게 되었습니다.
[3] 핵심 방법론: TOPReward의 아키텍처 및 메커니즘
TOPReward의 핵심 아이디어는 VLM의 텍스트 생성 결과물이 아닌, 내부 토큰 로짓(Internal Token Logits)에 주목한 점입니다.
1. 토큰 로짓 기반 진행률 추정
모델은 입력 비디오 프레임에 대해 특정 텍스트 토큰(예: ‘Success’, ‘Progress’ 등과 관련된 토큰)이 생성될 확률을 계산합니다. 이는 모델이 텍스트를 출력하기 직전의 확률 분포를 활용하므로, 자연어 출력 과정에서 발생하는 노이즈를 제거하고 훨씬 더 미세하고(fine-grained) 연속적인 보상 신호를 생성할 수 있게 합니다.
2. 시간적 일관성 확보
TOPReward는 비디오 VLM의 시계열 처리 능력을 활용하여 작업의 흐름을 파악합니다. 아래 예시에서 보듯, ‘수건 접기’와 같은 복잡한 작업에서도 단계별 시맨틱 하위 작업(Sub-tasks)에 따라 보상 값이 논리적으로 상승하는 것을 확인할 수 있습니다.
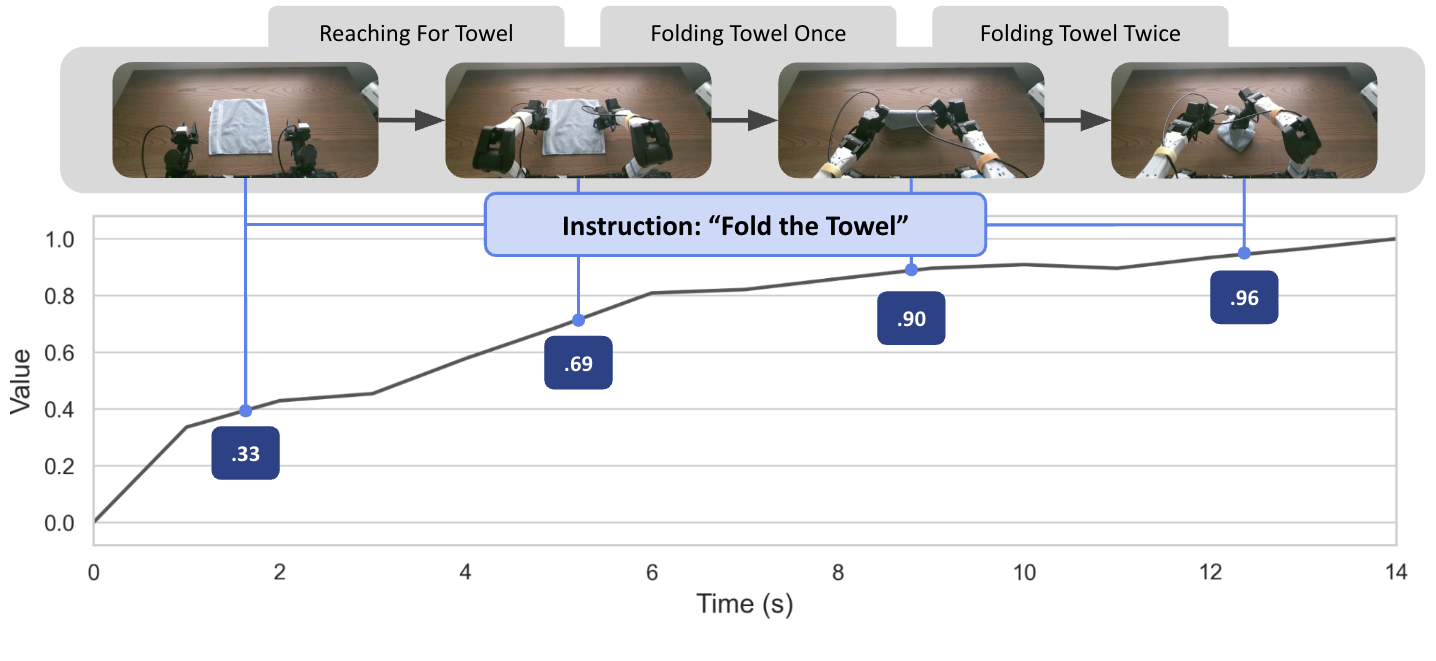 그림 2: ‘수건 접기’ 작업에서의 시간에 따른 TOPReward의 진행률 추정 곡선. 각 단계별로 보상 값이 정교하게 매핑됩니다.
그림 2: ‘수건 접기’ 작업에서의 시간에 따른 TOPReward의 진행률 추정 곡선. 각 단계별로 보상 값이 정교하게 매핑됩니다.
3. 수학적 모델링
진행률 $P$는 특정 시점 $t$의 관측값 $O_t$에 대해 모델이 작업 완료를 의미하는 토큰 $w$를 생성할 로그 확률(Log-probability)의 변화량으로 정의될 수 있습니다. 이를 통해 $0$에서 $1$ 사이의 부드러운 스칼라 보상 값을 산출합니다.
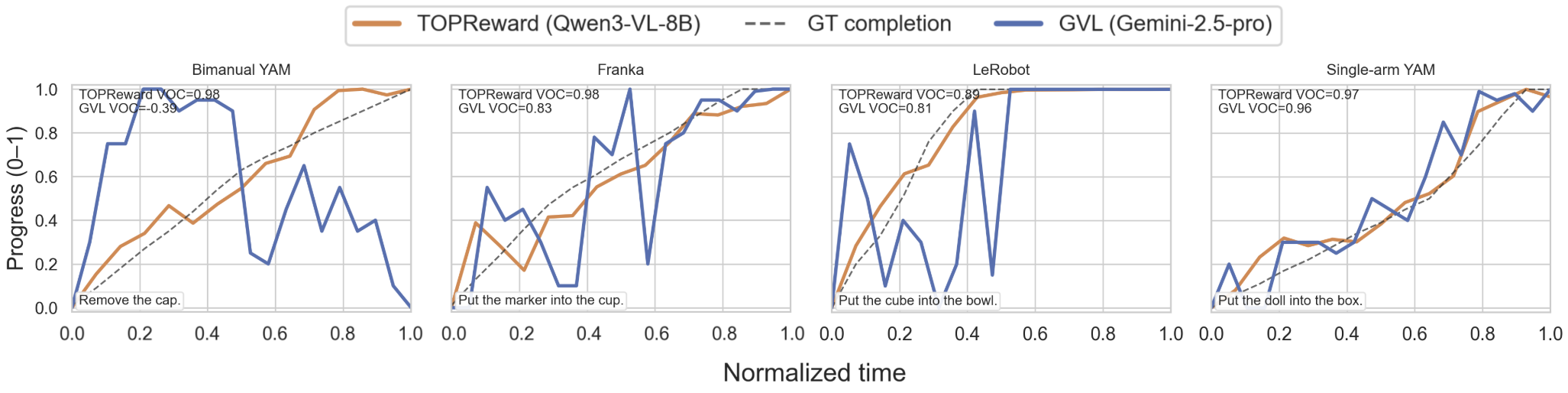 그림 4: ManiRewardBench 벤치마크에서 Ground Truth(점선)와 TOPReward(주황색)의 예측 결과 비교. 기존 GVL 방식보다 훨씬 높은 정확도를 보입니다.
그림 4: ManiRewardBench 벤치마크에서 Ground Truth(점선)와 TOPReward(주황색)의 예측 결과 비교. 기존 GVL 방식보다 훨씬 높은 정확도를 보입니다.
[4] 산업적 응용 및 시장 파급력 (Market Impact)
TOPReward 기술은 B2B AI SaaS 및 스마트 팩토리 시장에서 로봇 자동화의 패러다임을 바꿀 잠재력을 가지고 있습니다.
- 비용 절감형 자동화: 데이터 라벨링이나 보상 함수 설계(Reward Engineering)에 투입되던 수만 시간의 엔지니어링 비용을 획기적으로 줄일 수 있습니다.
- 에지 컴퓨팅(Edge Computing)과의 결합: 경량화된 VLM(예: Qwen-VL 최적화 버전)을 로봇의 온디바이스(On-device) 환경에 탑재하여, 클라우드 연결 없이도 실시간으로 자신의 작업을 평가하고 교정하는 자율형 로봇 구현이 가능해집니다.
- 다목적 로봇(General-purpose Robots): 특정 환경에 국한되지 않고, 텍스트 명령만으로 새로운 작업의 보상 체계를 즉시 생성할 수 있어 물류, 가전, 제조 등 다양한 산업군으로의 확장이 용이합니다.
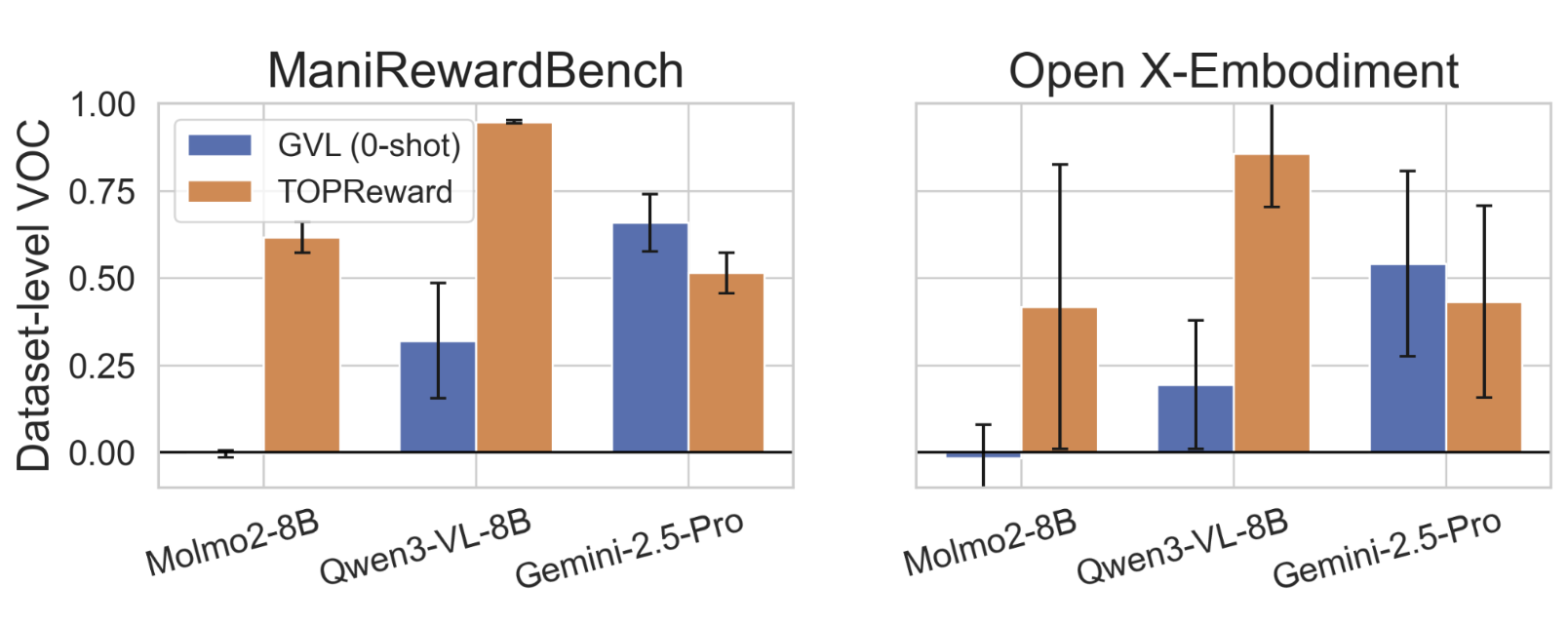 그림 3: 다양한 데이터셋에서 기존 GVL 대비 압도적인 성능(VOC) 차이를 보여주는 벤치마크 결과.
그림 3: 다양한 데이터셋에서 기존 GVL 대비 압도적인 성능(VOC) 차이를 보여주는 벤치마크 결과.
[5] Expert’s Touch: 기술적 통찰 및 비평
한 줄 평: “VLM의 입을 믿지 말고, 뇌(Logit)를 믿어라.”
기술적 한계 및 확장 과제
- VOC 지표의 맹점: 연구에서 사용된 VOC(Value-Order Correlation) 지표는 순위 상관관계만을 측정합니다. 그림 5에서 제시하듯, 작업이 미완성 상태에서 정체(Plateau)되더라도 순서만 맞으면 높은 점수를 줄 수 있다는 위험이 있습니다. 실제 제어 시스템에서는 절대적인 완료 수준(Absolute Completion) 측정이 병행되어야 합니다.
- 추론 지연(Latency): 대형 VLM의 토큰 로짓을 실시간 제어 루프(Control Loop, 보통 10Hz~100Hz)에 통합하기 위해서는 고도화된 모델 최적화(Model Quantization) 및 추론 가속 기술이 필수적입니다.
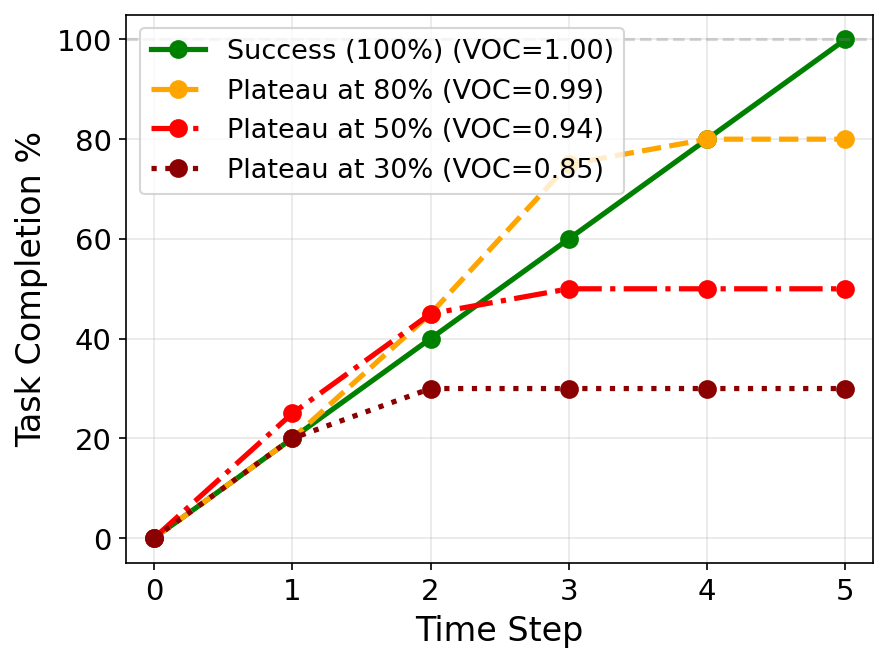 그림 5: VOC 지표의 한계점 분석. 순서가 올바르더라도 중간에 멈춘 궤적을 구분하지 못할 수 있음을 경고합니다.
그림 5: VOC 지표의 한계점 분석. 순서가 올바르더라도 중간에 멈춘 궤적을 구분하지 못할 수 있음을 경고합니다.
개발자를 위한 구현 팁
- Open-source Stack: Qwen2-VL 또는 LLaVA와 같은 오픈소스 모델의 Hugging Face 구현체를 사용하여
outputs.logits를 추출하는 파이프라인을 먼저 구축해 보십시오. - Reward Smoothing: 추출된 로짓 기반 보상은 노이즈가 있을 수 있으므로, 지수 이동 평균(EMA) 등을 활용한 후처리가 안정적인 RL 학습에 도움이 됩니다.
- Hybrid Approach: TOPReward를 기본 보상으로 사용하되, 고위험 작업에서는 전통적인 센서 기반 검증 시스템을 앙상블(Ensemble) 형태로 결합하는 방식이 실제 양산 환경에서는 안전할 것입니다.
