[2026-03-11] VLM 파인튜닝은 낭비다. 1번째 레이어에서 5배 빠르게 답을 낚아채는 Super Neuron (SN) 기법 해부

[Metadata]
- Paper: Taking Shortcuts for Categorical VQA Using Super Neurons (arxiv:2603.10781)
- Date: March 2026
VLM(Vision Language Model)으로 서비스 돌려본 분들은 알 겁니다. 사용자는 그저 “이 사진에 고양이 있어?”라는 단순한 ‘Yes/No’ 대답을 원할 뿐인데, 백엔드에서는 70B짜리 거대 모델의 80개 레이어를 전부 태우고 있죠. 이건 마치 스위치 하나 켜려고 발전소를 통째로 돌리는 격입니다. LoRA로 파인튜닝을 해봐야 결국 추론 시점의 연산량은 그대로입니다. 게다가 컨텍스트 윈도우가 길어질수록 VRAM은 비명을 지르죠.
이 미련한 짓을 멈추게 해줄 기발한 접근법이 나왔습니다. “Taking Shortcuts for Categorical VQA Using Super Neurons”라는 연구인데, 핵심은 진짜 미쳤습니다. 모델의 맨 첫 번째 레이어에서, 첫 번째 토큰이 생성되자마자 답을 낚아채서(Early Exit) 추론을 끝내버립니다. 최대 5.1배 빠른 속도로 말이죠.
TL;DR: 거대한 VLM의 깊은 레이어까지 연산할 필요 없이, 첫 번째 토큰과 가장 얕은 레이어의 ‘Super Neuron(스칼라 활성화 값)’만 프로빙(probing)하면 최대 5.1배의 속도로 분류형 VQA 결과를 얻을 수 있지만, 생성형(Generative) 태스크에는 절대 못 쓴다는 명확한 한계가 있습니다.
⚙️ 70B VLM의 깊은 늪을 건너뛰는 스칼라 프로빙의 마법
기존에 유행하던 SAV(Sparse Attention Vectors) 기법도 나쁘진 않았습니다. 특정 태스크에 반응하는 어텐션 헤드를 찾아내 분류기처럼 쓰는 방식이었죠. 하지만 어텐션 벡터를 뒤지는 건 여전히 무겁고, 탐색 공간(Search Space)에 한계가 명확했습니다. 반면, 이번에 등장한 Super Neurons (SNs)는 접근법 자체가 훨씬 로우레벨(Low-level)입니다.
🔹 스칼라 활성화 값 직접 찌르기 (Probing) 복잡한 벡터 연산을 무시하고 VLM 내부의 날것 그대로인 스칼라 활성화 값(Raw scalar activations) 자체를 찌릅니다. 특정 분류 태스크(예: 강아지 vs 고양이) 데이터셋을 모델에 살짝 흘려보내면, 유독 미친 듯이 활성화되는 특정 뉴런(스칼라 값)들이 발견됩니다. 이 녀석들이 바로 Super Neuron입니다. 탐색 공간이 기하급수적으로 늘어나니, 훨씬 더 날카로운 식별력을 가진 뉴런을 찾을 수 있게 된 거죠.
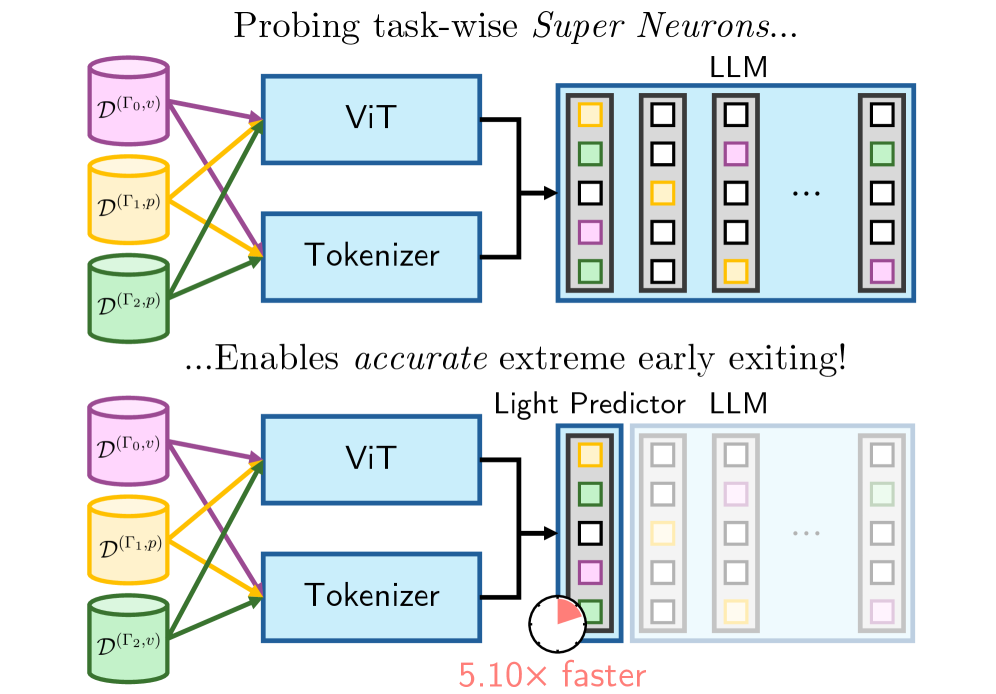 Figure 1: 깊은 레이어를 통과할 필요 없이, 첫 번째 토큰이 생성되는 즉시 미리 찾아둔 Super Neuron의 스칼라 값을 확인해 극단적인 조기 종료(Extreme Early Exiting)를 수행하는 구조입니다.
Figure 1: 깊은 레이어를 통과할 필요 없이, 첫 번째 토큰이 생성되는 즉시 미리 찾아둔 Super Neuron의 스칼라 값을 확인해 극단적인 조기 종료(Extreme Early Exiting)를 수행하는 구조입니다.
가장 소름 돋는 포인트는 이 SN들이 모델의 가장 얕은 레이어(Layer 1)에 대거 포진해 있다는 사실입니다. 굳이 32개, 80개씩 되는 트랜스포머 블록을 다 통과할 필요가 없다는 뜻이죠. 아래의 가상 코드를 보면 이 극단적인 조기 종료(Extreme Early Exiting)가 아키텍처 레벨에서 어떻게 구현되는지 감이 올 겁니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
def forward_categorical_vqa(self, input_ids, images, sn_indices, threshold_alpha):
# 1. 임베딩 계층 통과
hidden_states = self.embed_tokens(input_ids)
# 2. 전체 레이어 중 단 '첫 번째' 레이어만 포워드 패스 실행!
hidden_states = self.layers[0](hidden_states, images)
# 3. 1번 레이어의 첫 생성 토큰 위치에서 특정 뉴런(SN)의 스칼라 값만 핀셋으로 뽑아냄
sn_activations = hidden_states[0, 0, sn_indices]
# 4. 활성화 값이 사전에 정의한 임계치(alpha)를 넘으면 연산 즉시 종료
if sn_activations.mean() > threshold_alpha:
return "Yes" # 🚀 나머지 79개 레이어 연산 전부 스킵 (5배 속도 향상)
# 5. 임계치를 못 넘으면 원래대로 전체 레이어 통과 (Fallback)
return self.generate_full_pass(hidden_states)
이 코드가 의미하는 바는 명확합니다. 파라미터를 단 1비트도 수정하지 않으면서도(Training-free), 추론 비용을 말도 안 되게 깎아버릴 수 있다는 겁니다.
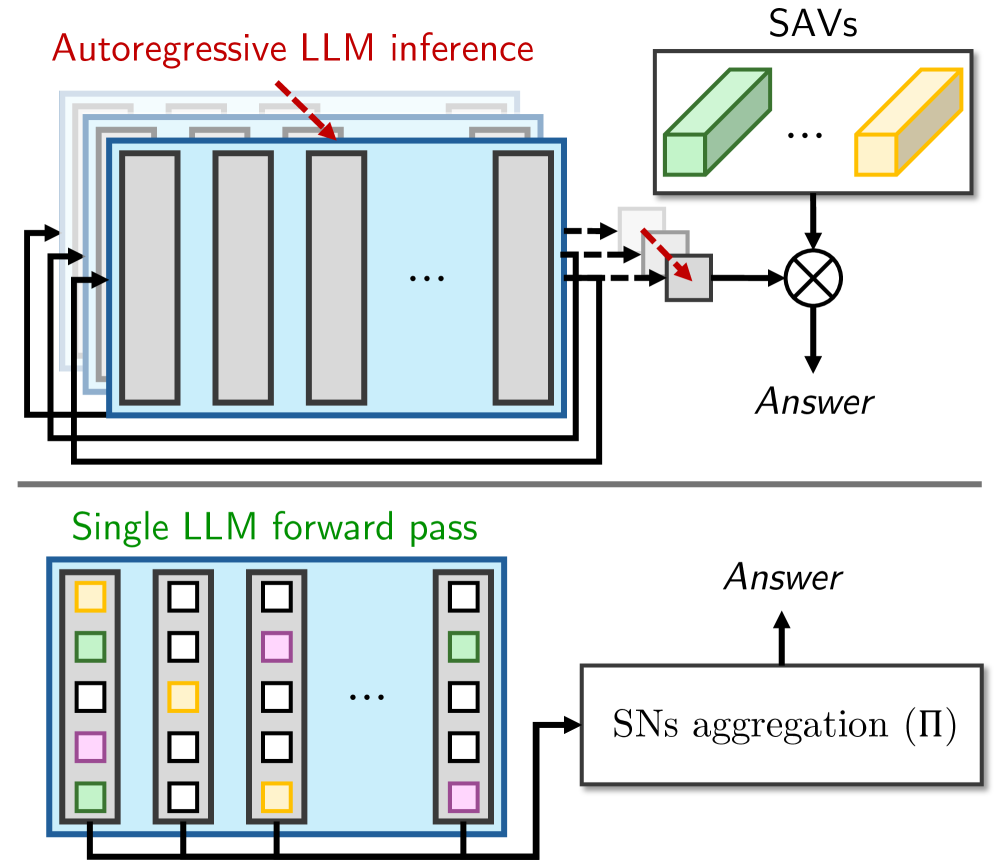 Figure 2: 복잡한 어텐션 맵을 계산해야 하는 SAV 기법과 달리, SN은 단순히 피드포워드 네트워크(FFN) 내부의 단일 스칼라 활성화 값만 쳐다보므로 연산 오버헤드가 사실상 0에 가깝습니다.
Figure 2: 복잡한 어텐션 맵을 계산해야 하는 SAV 기법과 달리, SN은 단순히 피드포워드 네트워크(FFN) 내부의 단일 스칼라 활성화 값만 쳐다보므로 연산 오버헤드가 사실상 0에 가깝습니다.
⚔️ 기존 스택 vs 새로운 패러다임: 진짜 쓸만한가?
이쯤 되면 “그냥 LoRA로 VQA 전용 모델 깎는 게 낫지 않아?”라고 반문하실 분들이 계실 겁니다. 하지만 프로덕션 환경의 인프라 청구서를 받아보면 얘기가 달라지죠. 카테고리 분류(Yes/No, 다중 선택)라는 한정된 태스크 안에서, 세 가지 방법론이 서버 비용과 엔지니어의 멘탈에 미치는 영향을 비교해 봅시다.
| 평가지표 | LoRA Fine-Tuning | SAVs (기존 Training-free) | Super Neurons (본 연구) |
|---|---|---|---|
| 모델 가중치 수정 | 필요함 (학습 파이프라인 구축 필수) | 없음 | 없음 (Zero-shot 수준) |
| 사전 준비 시간 | 수 시간 ~ 수 일 (GPU 혹사) | 중간 (어텐션 헤드 탐색) | 매우 짧음 (스칼라 값 프로빙) |
| 추론 속도 향상 | 없음 (베이스라인과 동일) | ~ 1.5x | 최대 5.10x (Layer 1 조기 종료) |
| 적용 가능 태스크 | 모든 VQA 및 생성형 | 제한적 (분류, 식별) | 오직 분류형(Categorical) VQA |
| 메모리 오버헤드 | LoRA 어댑터 VRAM 추가 할당 | 어텐션 캐시 필요 | 완벽히 0 (스칼라 인덱스만 메모리 상주) |
위 표의 수치가 의미하는 바는 단순한 ‘최적화’ 수준이 아닙니다. 추론 속도가 5배 빨라졌다는 것은, 똑같은 GPU 인스턴스 1대에서 처리할 수 있는 초당 동시 요청량(Throughput)이 5배 늘어났다는 뜻입니다. AWS p4d 인스턴스 요금을 생각해 보세요. 모델 가중치를 건드리지 않으니, 백그라운드에서는 기존의 무거운 프롬프트를 처리하는 범용 VLM 역할을 그대로 유지하면서, 단순 분류 요청이 들어올 때만 레이어 1에서 요청을 쳐내는 라우팅이 가능해집니다.
🚀 내일 당장 프로덕션에 도입한다면?
이 기술이 연구실 장난감으로 끝나지 않으려면 어디에 써먹어야 할까요? 가장 파괴적인 효율을 낼 수 있는 실무 시나리오 두 가지를 꼽아봤습니다.
시나리오 1: 대규모 실시간 콘텐츠 모더레이션 (NSFW/Hate Speech 필터링) 수백만 명의 유저가 1초마다 업로드하는 이미지 중 음란물이나 폭력적인 이미지를 걸러내는 파이프라인을 상상해 보세요. “이 이미지에 부적절한 요소가 있는가?(Yes/No)”만 판별하면 됩니다. 전체 파라미터를 태울 필요 없이, 모더레이션에 반응하는 Super Neuron만 미리 찾아두면 됩니다. 저렴한 T4 GPU 하나로도 이전 대비 5배의 트래픽을 감당할 수 있죠. 단, 병목은 존재합니다. 데이터셋에 따라 정확한 식별을 보장하는 최적의 임계값(Threshold $\alpha$)을 찾아내는 사전 프로빙 작업은 필수적입니다.
시나리오 2: 이커머스 상품 카탈로그 자동 태깅 하루 수십만 건씩 등록되는 셀러들의 상품 이미지에 “신발”, “가전제품”, “의류” 같은 카테고리 태그를 붙여야 하는 상황입니다. 각 카테고리별로 반응하는 SN 인덱스 맵을 메모리에 올려두면 끝입니다. 입력 이미지가 들어오면 단 1번의 얕은 레이어 통과만으로 수십 개의 다중 라벨링을 순식간에 끝낼 수 있습니다.
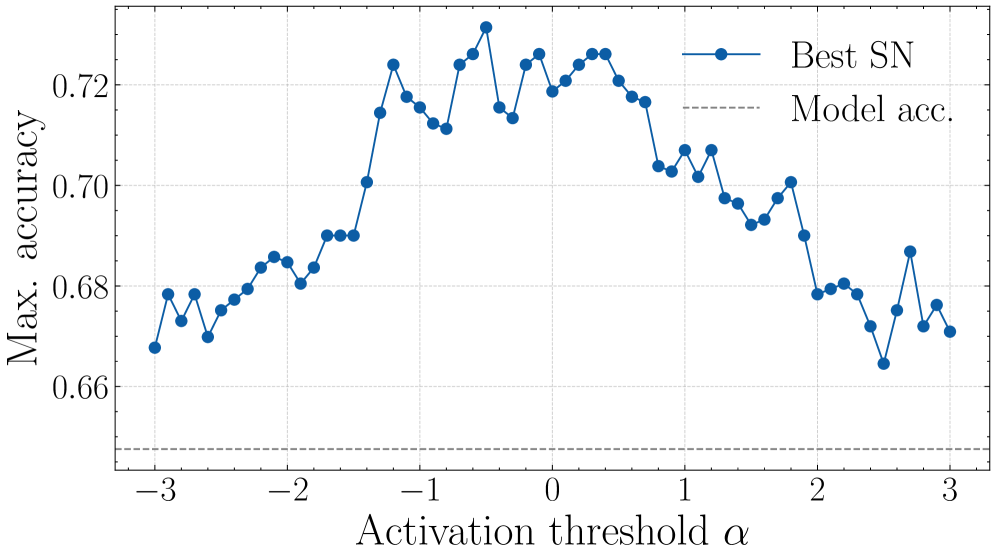 Figure 3: 활성화 임계값($\alpha$) 조정에 따른 정확도 그래프입니다. 임계값을 너무 빡빡하게 잡으면 조기 종료를 못 하고 전체 레이어를 타버리며, 너무 낮게 잡으면 오분류가 터지는 날카로운 트레이드오프를 보여줍니다.
Figure 3: 활성화 임계값($\alpha$) 조정에 따른 정확도 그래프입니다. 임계값을 너무 빡빡하게 잡으면 조기 종료를 못 하고 전체 레이어를 타버리며, 너무 낮게 잡으면 오분류가 터지는 날카로운 트레이드오프를 보여줍니다.
🧐 Tech Lead’s Honest Verdict
장점 (Pros): 무엇보다 ‘Layer 1 Early Exit’이라는 아이디어 자체가 경이롭습니다. 파라미터는 단 한 개도 건드리지 않으면서 추론 속도를 5배나 끌어올린 건 엔지니어링 관점에서 찬사를 보낼 만합니다. 탐색 공간을 복잡한 어텐션 벡터에서 가장 로우레벨인 스칼라 단위의 뉴런으로 확장한 덕분에 가능한 마법이죠. VRAM 오버헤드가 사실상 0이라는 점도 프로덕션 환경에서는 엄청난 축복입니다.
단점 (Cons): 치명적인 맹점이 있습니다. “이 사진에 대해 디테일하게 묘사해 줘” 같은 오픈엔드 생성형(Generative) 태스크에는 완벽하게 무용지물입니다. 오직 카테고리가 정해진 닫힌 분류 문제에만 쓸 수 있습니다. 또한, 앞서 언급했듯 각 태스크와 데이터셋마다 완벽히 작동하는 임계값(Threshold) $\alpha$를 수작업에 가깝게 휴리스틱하게 찾아야 합니다. 데이터 분포가 바뀌면 SN을 다시 프로빙해야 하는 유지보수 지옥이 열릴 수도 있습니다.
Final Verdict: “단순 분류형 VQA 전용 마이크로서비스를 구축할 거라면 지금 당장 클론해서 도입하세요. 하지만 만능 챗봇용으로는 쳐다보지도 마세요.” 여러분의 서비스가 유저와 대화하는 챗봇인지, 아니면 백엔드에서 이미지에 태그만 묵묵히 다는 비동기 워커(Worker)인지 파악하는 게 먼저입니다. 후자라면 이 기술은 여러분의 GPU 인프라 청구서를 극적으로 다이어트시켜 줄 최고의 무기가 될 겁니다.
