[2026-03-12] [AI 논문 해부] 미쳐버린 Reward Model을 구출하라: 이미지 편집/생성 RLHF를 위한 FIRM-8B의 등장

Metadata Block
- Paper ID: 2603.12247
- Paper Title: Trust Your Critic: Robust Reward Modeling and Reinforcement Learning for Faithful Image Editing and Generation
- Project Page: https://firm-reward.github.io
요즘 텍스트-투-이미지(T2I)나 이미지 편집 모델에 RLHF(인간 피드백 기반 강화학습)를 끼워 넣는 게 일종의 국룰이 되어가고 있죠. 그런데 막상 프로덕션 레벨에서 이걸 돌려보신 분들은 아실 겁니다. 모델 성능을 높이려고 PPO나 DPO를 돌렸는데, 웬걸? 이미지가 점점 기괴해지거나 프롬프트랑 전혀 상관없는 결과물이 나오는데도 보상 모델(Critic)이 만점을 줘버립니다.
왜 그럴까요? 평가를 담당해야 할 보상 모델(주로 LLaVA나 Qwen 같은 범용 VLM) 자체가 심각한 ‘환각(Hallucination)’에 빠져 있기 때문입니다. 고양이한테 빨간 모자를 씌우라고 했더니 화면 전체를 붉게 물들이고는 “명령 완벽 수행! 10점!”을 외치는 꼴이죠. GPU는 비명을 지르며 타들어가는데, 결과물은 쓰레기가 되는 환장할 노릇입니다. 오늘은 이런 멍청한 Critic들을 갈아치우고, 이미지 편집과 생성 파이프라인의 강화학습을 근본부터 뜯어고친 FIRM (Faithful Image Reward Modeling) 프레임워크를 해부해 보겠습니다.
한 줄 요약: 환각에 빠져 쓰레기 이미지에 만점을 주던 범용 VLM의 한계를 인정하고, ‘편집’과 ‘생성’을 철저히 분리해 평가 기준을 모듈화한 구원투수. 덕분에 RLHF 도중 모델이 붕괴하는 꼴을 안 봐도 됩니다.
⚙️ 멍청한 Critic을 참교육하는 방법: FIRM 아키텍처 딥다이브
기존의 보상 모델들은 단순히 완성된 이미지를 던져주고 “이거 프롬프트랑 잘 맞아? 1~10점으로 평가해 봐”라고 묻는 원시적인 방식을 썼습니다. FIRM은 이 안일한 접근을 완전히 쪼개버립니다. 연구진은 ‘이미지 편집(Edit)’과 ‘이미지 생성(Gen)’의 평가 기준이 근본적으로 다르다는 걸 인지하고 파이프라인을 두 개로 분리했습니다.
🔹 FIRM-Edit 파이프라인 (Difference-first 설계) 이미지 편집에서 개발자들을 제일 빡치게 하는 게 뭘까요? ‘배경에 있는 사과만 지워’라고 했는데 탁자 질감이나 고양이 털 색깔까지 바꿔버리는 현상입니다. 기존 VLM은 이걸 캐치하지 못합니다. FIRM은 원본 이미지와 편집된 이미지의 ‘차이(Difference)’를 먼저 추출합니다. 그다음 두 가지를 냉혹하게 평가하죠.
- Execution (실행력): 프롬프트에서 지시한 편집(사과 지우기)이 정확히 수행되었는가?
- Consistency (일관성): 건드리지 말아야 할 배경이나 나머지 요소들이 원본과 완벽하게 동일하게 유지되었는가? 이 논리적인 접근을 위해 37만 개의 고품질 데이터(FIRM-Edit-370K)를 구축해 FIRM-Edit-8B 모델을 깎아냈습니다.
🔹 FIRM-Gen 파이프라인 (Plan-then-score 패러다임) 생성은 어떨까요? 프롬프트가 길어질수록 기존 VLM은 정신을 못 차립니다. FIRM은 프롬프트를 통째로 평가하는 대신, ‘계획(Plan)’을 세워서 분해해 버립니다. “빨간 모자를 쓴 고양이가 파란 상자 위에 있다”라는 프롬프트가 있다면, 이걸 [객체: 고양이, 상자], [속성: 빨간 모자, 파란색], [공간적 관계: 위에]로 쪼갠 다음 각각을 개별적으로 채점합니다. 우리가 백엔드 코드 짤 때 거대한 함수 하나를 테스트하는 대신, 모듈별로 단위 테스트(Unit Test)를 촘촘하게 작성하는 거랑 똑같은 논리입니다.
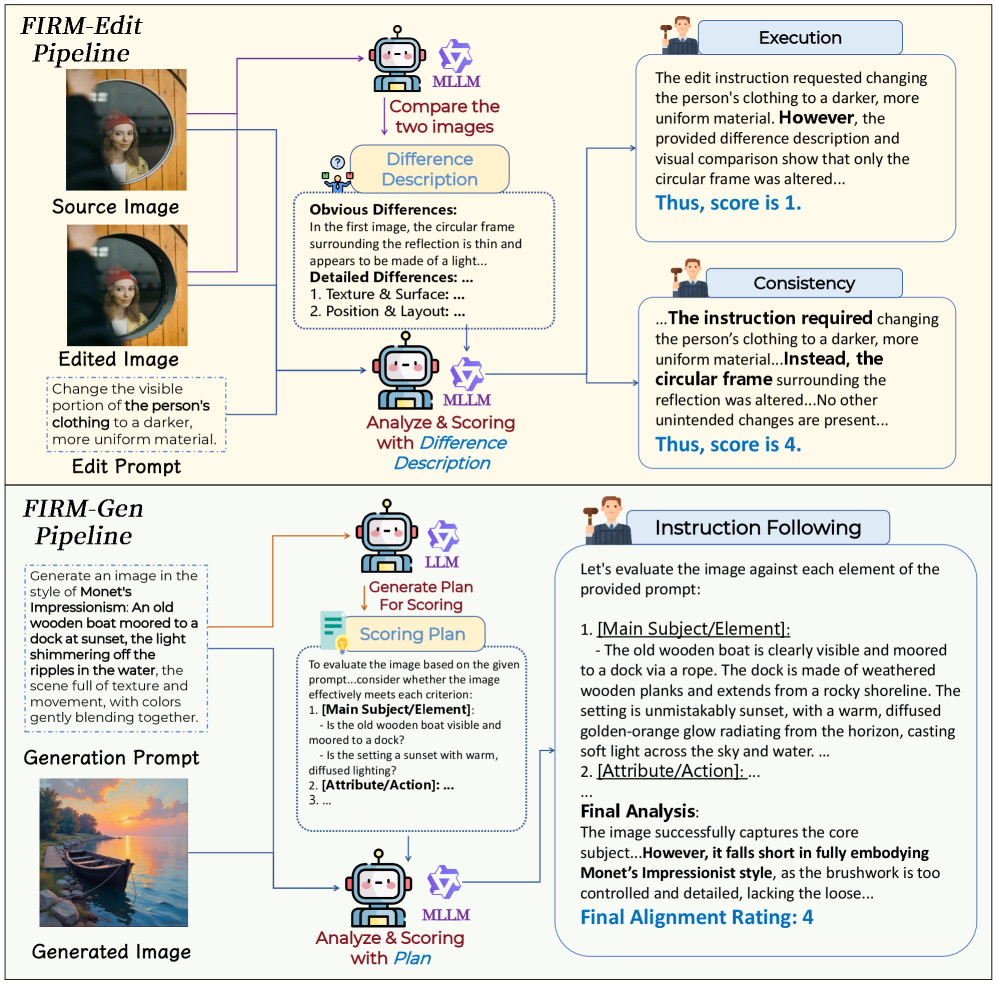 그림 3: 상단의 Edit 파이프라인은 원본-결과물의 ‘차이’를 추출해 분석하고, 하단의 Gen 파이프라인은 프롬프트를 요소별로 분해하여 개별 채점하는 구조를 보여줍니다. VLM이 대충 뭉뚱그려 점수 주는 꼼수를 원천 차단하는 핵심 메커니즘이죠.
그림 3: 상단의 Edit 파이프라인은 원본-결과물의 ‘차이’를 추출해 분석하고, 하단의 Gen 파이프라인은 프롬프트를 요소별로 분해하여 개별 채점하는 구조를 보여줍니다. VLM이 대충 뭉뚱그려 점수 주는 꼼수를 원천 차단하는 핵심 메커니즘이죠.
🔹 Base-and-Bonus 보상 전략 (Reward Hacking 철벽 방어) 솔직히 이 부분이 엔지니어링적으로 가장 섹시합니다. RLHF 돌릴 때 모델이 점수만 높게 받으려고 꼼수(Reward Hacking) 부리는 거 다들 겪어보셨죠? FIRM은 이걸 수학적 임계치로 틀어막았습니다. 편집 과정에는 CME(Consistency-Modulated Execution)라는 공식을 도입했습니다. 아무리 편집(Execution)을 기깔나게 잘했어도, 배경 일관성(Consistency) 점수가 설정한 임계치(Threshold)를 넘지 못하면 최종 보상을 가차 없이 0점으로 날려버립니다. “배경 망가뜨렸으면 넌 그냥 실패한 코드야”라고 시스템 레벨에서 못을 박아버리는 셈입니다. 생성 과정에도 유사한 QMA(Quality-Modulated Alignment)가 적용되어 보상 해킹을 막습니다.
⚔️ 기존 VLM 보상 모델 vs FIRM 패러다임
말로만 하면 체감이 안 되니, 당장 우리가 쓰는 스택과 비교해 봅시다.
| 비교 항목 | 기존 범용 VLM (Qwen-VL, LLaVA 등) | FIRM-8B (제안된 프레임워크) |
|---|---|---|
| 평가 방식 (Scoring) | 프롬프트 통째로 넘기고 점수 줘 (Holistic) | 객체, 속성, 공간 분해 후 개별 채점 (Plan-then-score) |
| 편집(Editing) 이해도 | 원본-결과물 차이 구별 못함 (배경 망가져도 만점) | 차이(Difference) 기반으로 Execution/Consistency 분리 평가 |
| Reward Hacking 방어 | 극도로 취약함 (꼼수 부리면 점수 다 퍼줌) | CME, QMA 등 임계치 기반 수학적 모듈로 원천 차단 |
| 모델 크기 및 VRAM | 32B~72B의 무거운 모델 필요 (RL 시 VRAM 터짐) | 8B 크기의 특화 모델로 비교적 가볍게 구동 (추론 비용 절감) |
| 개발자 경험 (DX) | RLHF 돌려놓고 모델 망가질까 봐 밤새 모니터링해야 함 | 명확한 Penalty 구조 덕분에 방치해 둬도 안정적으로 수렴함 |
견적이 딱 나오죠? 72B짜리 무거운 범용 VLM을 Critic으로 띄워놓고 PPO를 돌린다고 생각해 보세요. H100 8장으로도 VRAM이 남아나질 않습니다. FIRM은 8B 사이즈로 체급을 줄이면서도, 평가 로직 자체를 도메인에 맞게 구조화했기 때문에 속도와 정확도 두 마리 토끼를 다 잡았습니다.
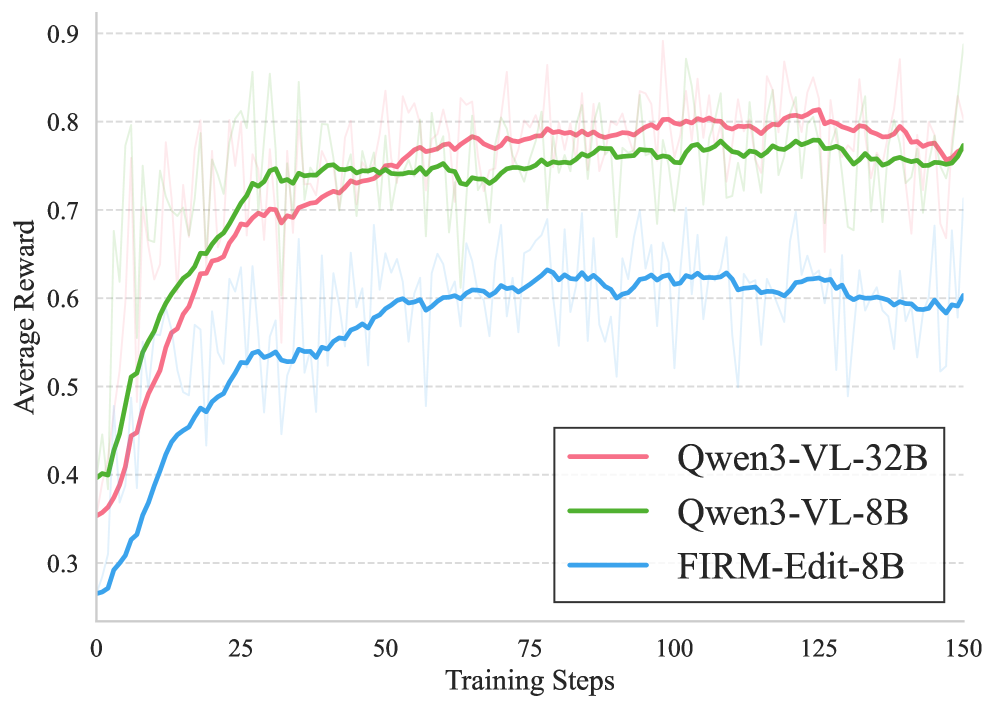 그림 5: 타 보상 모델(주황색, 보라색 선)들이 RL 학습을 거듭할수록 오히려 보상이 곤두박질치거나 요동치는 반면, FIRM-Edit-8B를 Critic으로 쓴 곡선(파란색)은 안정적으로 우상향하는 것을 볼 수 있습니다. 제대로 된 평가 지표가 강화학습에서 얼마나 중요한지 보여주는 증거입니다.
그림 5: 타 보상 모델(주황색, 보라색 선)들이 RL 학습을 거듭할수록 오히려 보상이 곤두박질치거나 요동치는 반면, FIRM-Edit-8B를 Critic으로 쓴 곡선(파란색)은 안정적으로 우상향하는 것을 볼 수 있습니다. 제대로 된 평가 지표가 강화학습에서 얼마나 중요한지 보여주는 증거입니다.
🚀 당장 우리 팀 파이프라인에 어떻게 써먹을까? (Practical Scenarios)
시나리오 1: 이커머스용 가상 피팅 및 상품 배경 교체 자동화 요즘 쇼핑몰 이미지 자동 편집 AI 많이들 도입하시죠. “모델 옷 색깔만 빨간색으로 바꿔줘” 했는데, 모델 얼굴이 뭉개지거나 옷에 있던 브랜드 로고가 날아가면 바로 CS 폭탄 맞습니다. 이때 기존 모델 대신 FIRM-Edit 프레임워크를 사내 모델 파인튜닝 파이프라인의 보상 모델로 끼워 넣으세요. CME 로직 덕분에 “원래 있던 로고나 배경을 1픽셀이라도 건드리면 보상은 0점”이라는 무자비한 룰이 강제되어, 치명적인 일관성 파괴 버그를 프로덕션 배포 전에 완벽하게 차단할 수 있습니다.
 그림 1: 왼쪽의 기존 모델들은 사과를 지우라고 했더니 접시 질감을 찰흙으로 만들거나 고양이를 기괴하게 변형시킵니다. 반면 우측의 FIRM을 적용한 결과물은 타겟만 깔끔하게 편집하면서 주변 환경의 Consistency를 소름 돋게 유지하고 있습니다.
그림 1: 왼쪽의 기존 모델들은 사과를 지우라고 했더니 접시 질감을 찰흙으로 만들거나 고양이를 기괴하게 변형시킵니다. 반면 우측의 FIRM을 적용한 결과물은 타겟만 깔끔하게 편집하면서 주변 환경의 Consistency를 소름 돋게 유지하고 있습니다.
시나리오 2: 사내 맞춤형 고성능 T2I 모델의 RLHF 파인튜닝 오픈소스 Stable Diffusion 3.5나 Qwen 계열 모델을 사내 도메인 데이터로 추가 학습시킬 때, SFT(Supervised Fine-Tuning)만으로는 유저들의 복잡한 프롬프트를 다 맞출 수 없는 한계가 옵니다. 결국 RLHF로 넘어가야 하는데, 사람이 일일이 수만 장의 이미지를 채점할 순 없잖아요? 이때 FIRM-Gen-8B를 AI Critic 자동화 파이프라인으로 투입하세요. 프롬프트의 지시사항(색상, 위치 개수 등)을 얼마나 정확하게 따랐는지(Instruction Following)를 집요하게 요소별로 채점하기 때문에, “대충 퀄리티만 좋은 예쁜 쓰레기”를 생성하며 VRAM을 낭비하는 현상을 획기적으로 줄일 수 있습니다.
 그림 2: 복잡한 다중 객체 프롬프트가 주어졌을 때, 타 모델들이 은근슬쩍 속성이나 객체를 빼먹고 렌더링하는 반면 FIRM-Gen-8B 기반의 모델은 지시사항을 악착같이 다 반영해 냅니다.
그림 2: 복잡한 다중 객체 프롬프트가 주어졌을 때, 타 모델들이 은근슬쩍 속성이나 객체를 빼먹고 렌더링하는 반면 FIRM-Gen-8B 기반의 모델은 지시사항을 악착같이 다 반영해 냅니다.
🧐 Tech Lead’s Brutally Honest Verdict
👍 Pros (진짜 흥분되는 점): 이 논문은 단순히 “우리 모델 벤치마크 점수 높아요”라고 자랑하는 학술적인 글이 아닙니다. RLHF 파이프라인을 직접 구축해 본 개발자들이 피눈물 흘리는 지점(Critic의 환각과 보상 해킹)을 아주 정확하게 타격했습니다. ‘차이(Difference)’ 기반 평가와 ‘임계치 기반의 Base-and-Bonus’ 수학적 접근은 굳이 이미지가 아니더라도 다른 도메인의 보상 모델링에 당장 차용해도 좋을 만큼 훌륭한 엔지니어링 감각입니다. 게다가 FIRM-Bench와 66만 장 규모의 데이터셋을 오픈소스로 풀었다는 건 완전 혜자스럽죠.
👎 Cons (까놓고 말해서 아쉬운 점): 논문에서는 8B 모델이라 가볍다고 열심히 포장하지만, RL 환경 세팅해 보신 분들은 코웃음 치실 겁니다. 강화학습 환경에서는 Base Model, Reference Model, 그리고 Critic Model(FIRM)까지 동시에 GPU에 띄워야 합니다. PPO 환경에서 8B 사이즈의 VLM Critic은 결코 ‘깃털처럼’ 가벼운 게 아닙니다. 엔터프라이즈급 GPU 클러스터가 빵빵하게 지원되지 않는 스타트업이나 개인 개발자에겐 여전히 VRAM 압박이 상당할 겁니다. 또, Plan-then-score 구조 특성상 프롬프트를 파싱하고 개별 채점하는 과정에서 오버헤드(Overhead)가 발생해 학습 속도가 늘어질 위험도 다분합니다.
🔥 Final Verdict: “RLHF를 진지하게 고민하는 팀이라면 당장 Repo를 클론하라. 하지만 단순 SFT만 끄적일 거라면 Wait.” 만약 여러분의 팀이 비전 모델의 RL 파이프라인을 구축 중이고, 멍청한 Reward Model 때문에 밤을 새우며 파라미터 튜닝만 하고 있다면 이 프레임워크는 가뭄의 단비입니다. https://firm-reward.github.io 에 공개된 코드와 데이터셋을 당장 뜯어보세요. 적어도 기존 VLM이 치던 어설픈 사기는 확실하게 막아줄 테니까요.
 그림 4: 자체 벤치마크 테스트 결과. 32B 크기의 거대한 기존 모델들조차 환각에 빠져 오답을 내는 상황에서, 8B에 불과한 FIRM 모델이 훨씬 더 인간의 평가(Ground Truth)에 부합하는 날카롭고 냉정한 판단력을 보여주고 있습니다.
그림 4: 자체 벤치마크 테스트 결과. 32B 크기의 거대한 기존 모델들조차 환각에 빠져 오답을 내는 상황에서, 8B에 불과한 FIRM 모델이 훨씬 더 인간의 평가(Ground Truth)에 부합하는 날카롭고 냉정한 판단력을 보여주고 있습니다.
