[2026-03-16] 단순 프레임 분석은 잊어라. Video-CoE: MLLM에 'Chain of Events'를 주입해 미래를 예측하는 법

[Metadata]
- Paper: Video-CoE: Reinforcing Video Event Prediction via Chain of Events
- Code & Models: Coming Soon
- Tags: #MLLM #VideoPrediction #GRPO #RLHF
비디오 데이터를 다뤄본 개발자라면 다들 뼈저리게 공감하실 겁니다. GPT-4o나 Gemini에 10초짜리 블랙박스 영상을 던져주고 “이 다음에 무슨 일이 일어날까?”라고 물어보면 어떻게 될까요. 십중팔구는 아주 뻔하고 안전한 소리만 늘어놓거나, 화면에 아예 존재하지도 않는 객체를 지어내는 환각(Hallucination) 파티를 벌입니다. 모델 입장에서 비디오는 그저 ‘순서가 조금 있는 이미지 뭉치’일 뿐, 시간의 흐름에 따른 물리적 인과관계를 이해하지 못하기 때문이죠.
이 지독한 문제를 해결하겠다고 저자들이 들고 온 무기가 바로 Video-CoE (Chain of Events) 입니다. 단순히 정답을 찍어 맞추는 블랙박스 방식에서 벗어나, 프레임 단위의 사건 사슬(Event Chain)을 먼저 강제로 서술하게 만듭니다. 원인이 있어야 결과가 있다는 아주 원초적이면서도 확실한 엔지니어링 접근법을 모델 아키텍처 레벨에 박아 넣은 겁니다.
TL;DR: Video-CoE는 비디오 프레임 사이의 ‘인과관계 사슬(Chain of Events)’을 생성하도록 모델을 강제하여, 시각적 환각을 줄이고 미래 예측(VEP) 정확도를 SOTA급으로 끌어올린 SFT 및 GRPO(RLHF) 파이프라인입니다.
⚙️ 시간의 흐름을 쪼개고 연결하는 ‘Chain of Events’ 파이프라인 해부
기존 MLLM에게 비디오 예측을 시키면 “A가 일어난다”라고 단답형으로 끝납니다. 중간 과정이 없으니 모델이 진짜 영상을 본 건지, 아니면 언어 모델 특유의 텍스트 확률 게임으로 때려 맞춘 건지 알 길이 없죠. Video-CoE는 이 중간 과정을 CoE-SFT와 CoE-GRPO 두 가지 페이즈로 뜯어고쳤습니다.
 기존 모델들의 한계점. 프레임을 개별적으로 인식할 뿐, 시간의 흐름에 따른 사건의 인과관계를 놓치는 전형적인 환각 현상을 보여줍니다.
기존 모델들의 한계점. 프레임을 개별적으로 인식할 뿐, 시간의 흐름에 따른 사건의 인과관계를 놓치는 전형적인 환각 현상을 보여줍니다.
🔹 Phase 1: CoE-SFT (Supervised Fine-Tuning) 우선 거대한 선생님 모델(Qwen2.5-VL-72B)을 데려와서 고품질의 추론 데이터를 뽑아냅니다. 비디오와 최종 미래 사건(Future Event)을 동시에 던져주고, 그 사이를 잇는 논리적 징검다리를 텍스트로 생성하게 만드는 거죠. 이렇게 만들어진 ‘원인-중간과정-결과’의 데이터셋으로 작은 모델들을 파인튜닝합니다.
 Qwen2.5-VL-72B를 활용한 CoE-SFT 파이프라인. 단순히 정답을 맞히는 게 아니라, 비디오 프레임 간의 중간 논리 추론 과정을 생성하도록 강제해 모델의 근본적인 시계열 이해도를 높입니다.
Qwen2.5-VL-72B를 활용한 CoE-SFT 파이프라인. 단순히 정답을 맞히는 게 아니라, 비디오 프레임 간의 중간 논리 추론 과정을 생성하도록 강제해 모델의 근본적인 시계열 이해도를 높입니다.
🔹 Phase 2: CoE-GRPO (Group Relative Policy Optimization) 가장 흥미로운 부분은 이 강화학습(RL) 파이프라인입니다. LLM에서 쓰던 GRPO를 비디오 도메인으로 끌고 왔는데, 모델이 꼼수(Reward Hacking)를 쓰지 못하도록 3중 보상 체계를 설계했습니다. 모델이 “나는 영상을 안 봤지만 대충 이런 일이 일어날 것 같아”라고 우기는 걸 원천 차단하는 장치들입니다.
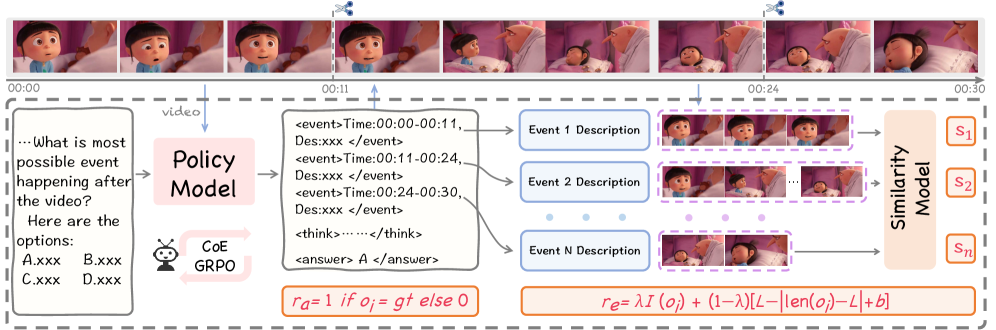 CoE-GRPO 보상 체계. 포맷 준수(r_e), 타임스탬프 정렬(r_s), 최종 정답 검증(r_a) 3가지 보상 함수를 통해 모델이 텍스트 확률에만 의존하지 않도록 멱살을 잡습니다.
CoE-GRPO 보상 체계. 포맷 준수(r_e), 타임스탬프 정렬(r_s), 최종 정답 검증(r_a) 3가지 보상 함수를 통해 모델이 텍스트 확률에만 의존하지 않도록 멱살을 잡습니다.
이 보상 함수들이 실제로 어떻게 동작하는지 개발자 시선에서 JSON 페이로드 형태로 직관적으로 뜯어봅시다. 모델은 반드시 아래와 같은 구조로 타임스탬프를 포함한 CoE를 반환해야만 보상을 받습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
{
"reasoning_process": {
"step_1": {
"timestamp": "00:01-00:03",
"event": "The pedestrian approaches the crosswalk."
},
"step_2": {
"timestamp": "00:03-00:05",
"event": "The traffic light turns yellow."
}
},
"future_prediction": "Therefore, the driver will step on the brakes to stop the vehicle."
}
만약 모델이 timestamp와 event의 싱크를 맞추지 못하거나, 영상에 없는 객체를 event에 적어내면 $r_s$ (상태-시간 정렬 보상)에서 가차 없이 마이너스 페널티를 받게 됩니다. 결국 모델은 비디오 프레임을 억지로라도 꼼꼼히 쳐다볼 수밖에 없는 구조가 완성되는 거죠.
⚔️ 기존 스택 vs 새로운 패러다임: 진짜 쓸만한가?
“그냥 기존 모델에 프롬프팅으로 Chain-of-Thought(CoT) 하라고 지시하면 되는 거 아님?”이라고 생각하실 수 있습니다. 하지만 비디오 도메인에서 단순 Text-CoT는 오히려 독이 되는 경우가 많습니다. 아래 테이블로 비교해 보죠.
| 평가지표 | Direct Prediction (기존) | Standard CoT 프롬프팅 | Video-CoE (SFT) | Video-CoE (GRPO) |
|---|---|---|---|---|
| 시계열 논리 정확도 | 낮음 (찍기 수준) | 중간 (텍스트 환각 심함) | 높음 | 매우 높음 (SOTA) |
| Reward Hacking 방어 | N/A | 취약함 (말만 그럴듯하게 함) | 중간 | 강력함 ($r_s$ 보상 덕분) |
| Context Window 소모 | 적음 | 많음 | 많음 | 많음 |
| Inference Latency | 빠름 (TTFT 이후 즉시) | 느림 | 느림 | 느림 |
숫자와 팩트만 놓고 분석해 봅시다. Standard CoT는 텍스트 위주의 언어 모델 논리에 갇혀버립니다. 영상에 없는 내용을 지어내면서 스스로 그 거짓말에 속아 넘어가는 악순환이 발생하죠. 반면 Video-CoE의 GRPO 방식은 시각적 근거(Visual Grounding) 를 강제합니다.
하지만 대가는 뼈아픕니다. 토큰 소모량과 Latency가 치솟습니다. 중간 추론 과정(CoE)을 모두 텍스트로 뱉어내야 최종 예측이 나오기 때문이죠. API 비용을 최적화해야 하는 스타트업 입장에서는 상당히 부담스러운 트레이드오프입니다.
🚀 내일 당장 프로덕션에 도입한다면?
이 논문의 접근법을 실제 비즈니스에 적용할 때 마주할 현실적인 시나리오 두 가지를 꼽아봤습니다.
1. 자율주행 블랙박스 엣지 케이스 자동 라벨링 파이프라인 가장 추천하는 유스케이스입니다. 자율주행 데이터팀은 수천 시간 분량의 주행 영상에서 ‘사고가 날 뻔한’ 아찔한 순간들을 필터링해야 합니다. 기존 VLM은 이걸 다 놓칩니다. 하지만 Video-CoE 모델을 오프라인 파이프라인에 배치하고 밤새 돌린다면? 타임스탬프 단위로 인과관계가 적힌 고품질의 JSON 라벨 데이터를 얻을 수 있습니다. 실시간 처리가 아니니 Latency 걱정도 없죠.
2. 실시간 CCTV 범죄/이상행동 예측 시스템 (도입 주의) 내일 당장 이걸 CCTV 관제 서버에 올리겠다고요? 도시락 싸 들고 말리겠습니다. A100 GPU를 여러 대 묶어 쓰지 않는 이상, VLM이 CoE 텍스트를 줄줄이 생성하는 동안 이미 범인은 도망가고 없을 겁니다. Time-to-First-Token(TTFT) 자체도 긴데, 추론 토큰까지 수백 개를 뽑아야 하니까요. 실시간성이 생명인 프로덕션에서는 아직 시기상조입니다.
🧐 Tech Lead’s Honest Verdict
👍 Pros (진짜 혁신적인 부분)
- MLLM의 고질병인 ‘시각적 환각’을 타임스탬프 강제 정렬($r_s$)로 때려잡은 점은 박수받아 마땅합니다.
- GRPO를 비디오 VEP 도메인에 성공적으로 안착시켰습니다. RLHF가 단순 대화형 AI를 넘어 비전 태스크에도 필수적이라는 걸 증명했죠.
👎 Cons (현실적인 한계)
- Inference Cost: 추론 과정 하나하나가 모두 돈(토큰)입니다. CoE를 길게 뽑을수록 정확도는 오르겠지만, 인프라 팀의 비명 소리도 함께 커질 겁니다.
- GRPO 학습의 악랄함: 논문에서는 우아하게 설명했지만, 오픈소스 팀이 자체 비디오 데이터로 이 3중 보상 체계의 하이퍼파라미터를 튜닝하며 학습을 안정화시키는 건 지옥에 가까울 겁니다.
🔥 최종 판정: “내부 데이터 자동 라벨링용으로는 즉각 클론. 실시간 서비스 탑재는 v2를 존버하라.”
비디오 데이터를 다루는 AI 엔지니어라면 이 논문의 보상 함수 설계 철학만큼은 반드시 숙지해야 합니다. 앞으로 나올 모든 Video-LLM은 결국 이 방식으로 진화할 수밖에 없으니까요. 코드가 릴리즈되면 작은 7B 모델부터 로컬에 올려서 그 매운맛을 직접 테스트해 보시길 권합니다.
Additional Figures
 (b)
(b)
