[2026-03-12] [XSkill] 모델 재학습은 하수나 하는 짓? 파라미터 업데이트 없이 스스로 진화하는 멀티모달 에이전트 해부

layout: post title: “[XSkill] 모델 재학습은 하수나 하는 짓? 파라미터 업데이트 없이 스스로 진화하는 멀티모달 에이전트 해부” date: 2026-03-15 author: Cynical Tech Lead tags: [LLM, Multimodal, Agent, XSkill, Continual Learning] —
딥러닝 모델의 치매 현상, 언제까지 참아야 할까요?
최근 프론트엔드 UI가 살짝 바뀐 사내 어드민 페이지 때문에 멀티모달 RPA 에이전트가 뻗어버린 적이 있습니다. 버튼 위치가 몇 픽셀 바뀌거나, 이미지가 뒤집혀 들어오면 에이전트는 바보가 되죠. 에러 로그를 보고 프롬프트를 떡칠하거나, 눈물을 머금고 비싼 GPU를 태워 파인튜닝을 돌리는 게 우리네 일상입니다.
솔직히 지치지 않나요? 사람이면 “아, 저번엔 이미지가 뒤집혀 있어서 OCR이 깨졌지? 이번엔 회전시키고 읽어야겠다”라고 한 번의 경험으로 학습합니다. 그런데 왜 우리의 최첨단(SOTA) 에이전트들은 매번 백지상태에서 똑같은 실수를 반복할까요?
이 지긋지긋한 쳇바퀴를 끊어내겠다고 나온 논문이 바로 오늘 씹고 뜯어볼 XSkill(2603.12056)입니다. 복잡한 모델 파라미터 업데이트? 없습니다. 그냥 에이전트가 자신의 성공과 실패 궤적을 분석해서 ‘아하 모먼트’를 문서화하고, 다음 작업 때 이걸 꺼내 쓴다는 발상입니다.
한 줄 요약: 무거운 파라미터 튜닝 없이 ‘경험(Experience)’과 ‘스킬(Skill)’이라는 두 가지 메모리 스트림을 활용해 스스로 진화하는 멀티모달 에이전트 아키텍처. 단, RAG 기반이라 컨텍스트 윈도우 비용은 각오해야 함.
🧠 파라미터 튜닝 없이 어떻게 스스로 진화하는가? (XSkill 아키텍처 해부)
기존에도 에이전트에게 과거의 대화 기록을 쑤셔 넣는 RAG(Retrieval-Augmented Generation) 방식은 많았습니다. 하지만 멀티모달 환경에서는 단순 텍스트 검색만으로는 시각적 맥락(Visual-semantic gap)을 포착하지 못합니다. XSkill은 이 문제를 해결하기 위해 13만 줄의 코드를 갈아 넣어 듀얼 스트림 프레임워크(Dual-stream framework)를 설계했습니다.
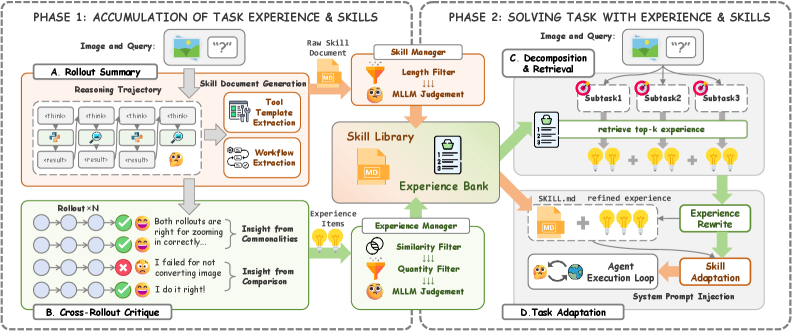
- 그림 2 설명: 롤아웃을 통해 성공/실패 궤적을 추출하고 이를 ‘경험’과 ‘스킬’이라는 두 가지 비전 기반 메모리로 압축(Phase I)한 뒤, 실제 추론 시 현재 상황에 맞춰 검색 및 주입(Phase II)하는 전체 파이프라인 구조입니다.
가장 핵심적인 두 가지 개념부터 짚고 넘어갑시다.
🔹 경험 (Experiences) - 액션 레벨의 족집게 과외 개발자로 치면 ‘트러블슈팅 로그’입니다. “이 특정 화면에서 버튼이 작아서 클릭이 빗나갔으니, 다음엔 확대(Zoom-in) 툴을 먼저 써라” 같은 구체적이고 좁은 범위의 지식입니다. 단순한 텍스트가 아니라 당시의 시각적 관측(Visual observation)과 맵핑되어 저장됩니다.
🔹 스킬 (Skills) - 태스크 레벨의 표준 운영 절차(SOP) 이건 ‘재사용 가능한 함수(Function)’에 가깝습니다. “뒤집힌 영수증에서 총액을 추출하려면: 1. 이미지를 크롭한다 -> 2. 180도 회전한다 -> 3. OCR 툴을 호출한다”라는 일련의 구조화된 계획입니다.
이 녀석이 동작하는 과정은 꽤나 영악합니다. Phase I (지식 축적) 단계에서 에이전트는 여러 경로로 태스크를 시도해 봅니다(Multi-path rollouts). 그리고 성공한 경로와 실패한 경로를 비교 분석(Cross-rollout critique)해서 “왜 실패했고 어떻게 성공했는지”를 요약합니다. 쓸데없는 노이즈는 버리고 정수만 뽑아내는 증류(Distillation) 과정이죠.
Phase II (추론) 단계에서는 새로운 태스크가 들어오면 현재의 화면(시각적 컨텍스트)을 분석해 가장 유사한 ‘경험’과 ‘스킬’을 검색해 옵니다. 그리고 이를 프롬프트에 동적으로 주입해 실행합니다. 한마디로, 스스로 StackOverflow를 만들고 검색해가며 코딩하는 에이전트인 셈입니다.
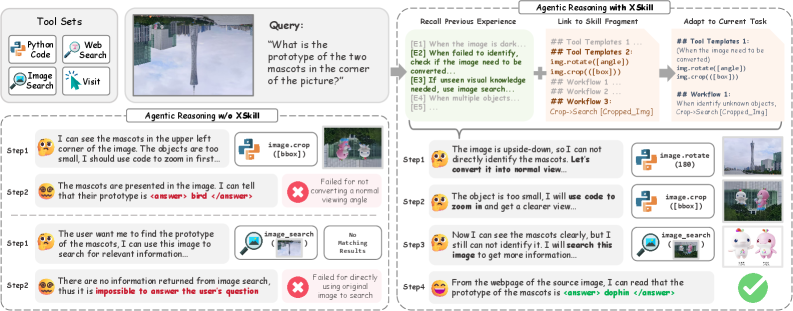
- 그림 1 설명: 단순 프롬프팅(왼쪽)은 이미지가 뒤집혀 있다는 시각적 컨텍스트를 놓치지만, XSkill(오른쪽)은 과거의 ‘경험’을 불러와 이미지 회전 및 크롭이라는 구체적 ‘스킬’을 조합해 문제를 해결해내는 과정을 적나라하게 보여줍니다.
⚔️ 기존 스택(SOTA) vs 새로운 패러다임: 무엇이 다른가?
“그냥 모델 파인튜닝 하면 되는 거 아님?”이라고 반문하실 분들을 위해 준비했습니다. 현업에서 에이전트를 굴려본 사람이라면 이 차이가 얼마나 큰지 뼈저리게 느낄 겁니다.
| 비교 항목 | 기존 멀티모달 파인튜닝 (SOTA) | 단순 RAG + 프롬프팅 | XSkill (New Paradigm) |
|---|---|---|---|
| 메모리/스토리지 | 모델 가중치 전체(수십~수백 GB) 복제 필요 | 벡터 DB 및 텍스트 덩어리 보관 (Low) | 경험/스킬 텍스트 + 시각적 임베딩 맵핑 (Medium) |
| 추론 속도 (Speed) | 빠름 (내재화된 지식) | 컨텍스트 추가로 다소 느려짐 | 지식 검색 + 시각적 적응 과정으로 인해 가장 느림 |
| 새로운 태스크 적응 | 데이터 수집 및 재학습 파이프라인 가동 (수일 소요) | 프롬프트 엔지니어링 깎기 (수시간 소요) | Zero-shot에 가깝게 자가 적응 (즉시) |
| 운영 비용 (Cost) | 막대한 GPU 컴퓨팅 비용 발생 | 저렴하지만 잦은 환각(Hallucination)으로 재시도 비용 발생 | 토큰 사용량 폭발 (API 비용 증가), 하지만 정확도 보장 |
| 개발자 경험 (DX) | 최악. 학습 스크립트 에러 잡다가 밤샘 | 그럭저럭. 근데 프롬프트 길어지면 모델이 말 안 들음 | 최상. 에이전트가 알아서 SOP를 문서화하고 고쳐나감 |
표에서 볼 수 있듯, XSkill은 ‘GPU 연산 비용’을 ‘API 토큰 비용’으로 치환한 모델입니다. 속도는 조금 양보하더라도, 개발자가 일일이 코너 케이스를 하드코딩하지 않아도 된다는 압도적인 장점이 있죠.
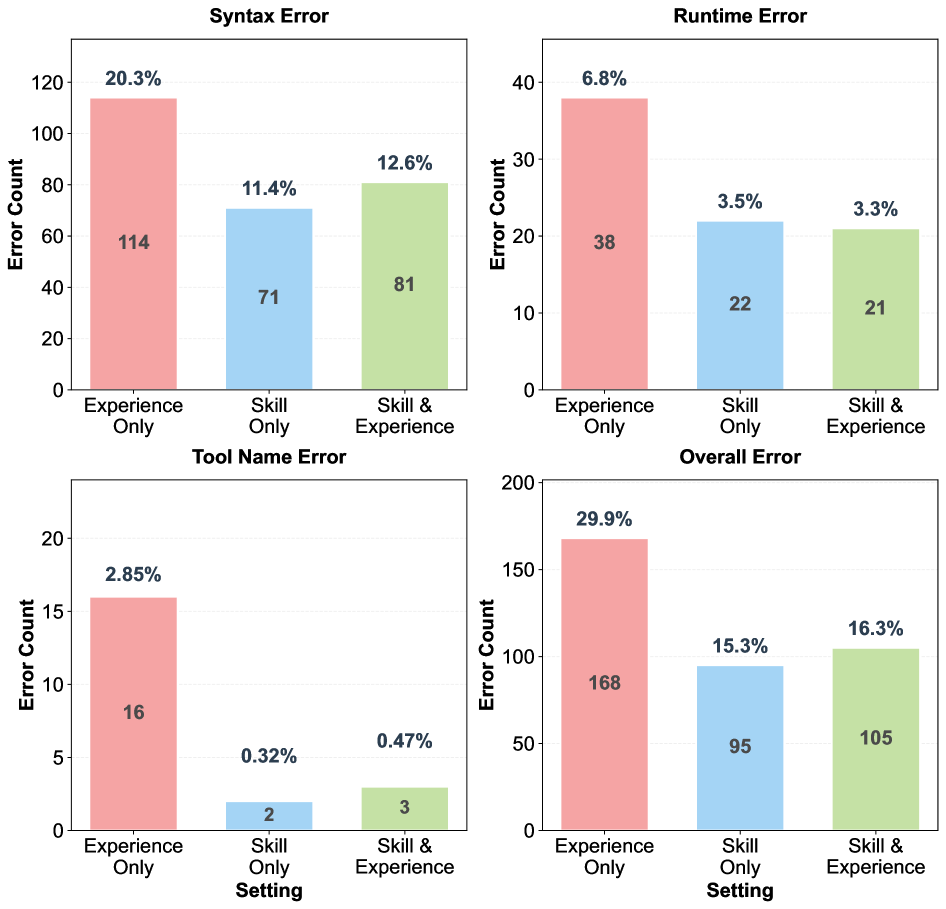
- 그림 3 설명: Gemini-2.5-Pro를 사용한 에러 분석 결과입니다. XSkill의 ‘스킬’ 메모리가 적용되었을 때 에이전트의 고질병인 문법 오류(Syntax)와 런타임 에러(Runtime)가 드라마틱하게 감소하는 것을 확인할 수 있습니다. 툴을 어떻게 써야 하는지 SOP가 생겼기 때문이죠.
🚀 내일 당장 프로덕션에 쓸 수 있을까? (Use Cases)
이론은 번지르르한데, 이거 진짜 실무에 쓸 수 있을까요? 저는 다음 두 가지 시나리오에서 침을 흘릴 수밖에 없었습니다.
1. 레거시 시스템을 다루는 사내 RPA 자동화 봇 우리 회사의 백오피스 UI는 매달 바뀝니다. 버튼이 왼쪽에 있다가 오른쪽으로 가고, 팝업이 추가되죠. 기존 RPA 스크립트나 단순 비전 에이전트는 이때마다 터집니다. 하지만 XSkill을 적용하면? 첫 시도에서 봇이 실패하더라도, 다른 경로(Rollout)를 탐색해 새로운 UI의 패턴을 ‘경험’으로 저장합니다. 개발자가 코드를 수정할 필요 없이 봇이 스스로 바뀐 UI에 적응하는 기적을 볼 수 있습니다.
2. 엣지 케이스가 넘쳐나는 의료/제조 도메인의 시각 분석 의료용 X-Ray나 공장 불량품 검출 같은 경우, 이미지의 형태가 천차만별입니다. 특정 각도에서 찍힌 부품은 항상 노이즈가 끼는데, XSkill은 “이런 형태의 노이즈가 보일 때는 A 필터를 먼저 적용해라”라는 것을 ‘스킬’로 저장해 둡니다. 제로샷 상황에서도 기가 막히게 대처하죠.
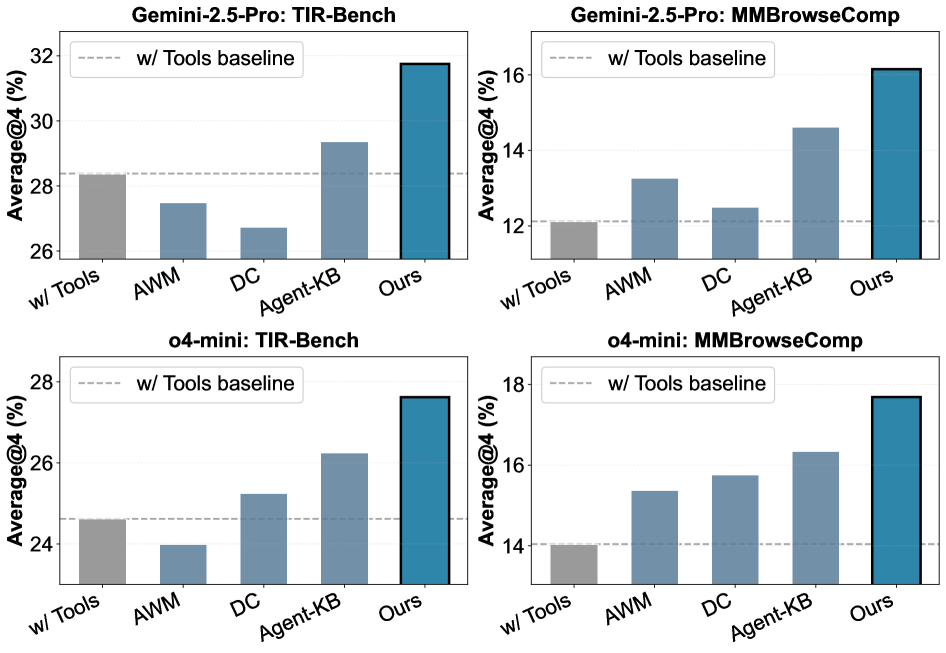
- 그림 5 설명: 처음 보는 환경(Out-of-Distribution)에서도 XSkill은 단순 툴 사용(w/ Tools) 베이스라인 대비 압도적인 제로샷 일반화 성능을 보여줍니다. 즉, 한 번 배운 방식을 낯선 UI에서도 찰떡같이 써먹는다는 뜻입니다.
🧐 Tech Lead’s Brutally Honest Verdict
자, 흥분은 가라앉히고 차갑게 평가해 봅시다.
장점 (Pros): 강화학습(RLHF)이나 파인튜닝이라는 무거운 짐을 벗어던졌다는 점이 예술입니다. 특히 Cross-Rollout Critique(실패와 성공을 대조해 배우는 과정)는 인간 개발자가 디버깅하는 방식과 완벽하게 닮아 있습니다. 그림 3에서 보았듯 문법 에러나 런타임 에러를 스스로 줄여나가는 모습은 감동적이기까지 합니다.
단점 (Cons): 이 아키텍처의 최대 적은 ‘CFO(재무책임자)’입니다. Phase I에서 경험을 축적하기 위해 여러 번의 롤아웃(Rollout)을 돌려야 합니다. 시각적 맥락까지 포함해서 말이죠. GPT-4o나 Claude 3.5 Sonnet API로 이 짓을 수천 번 반복한다? 다음 달 청구서 날아오면 등짝 스매싱으로 안 끝납니다.
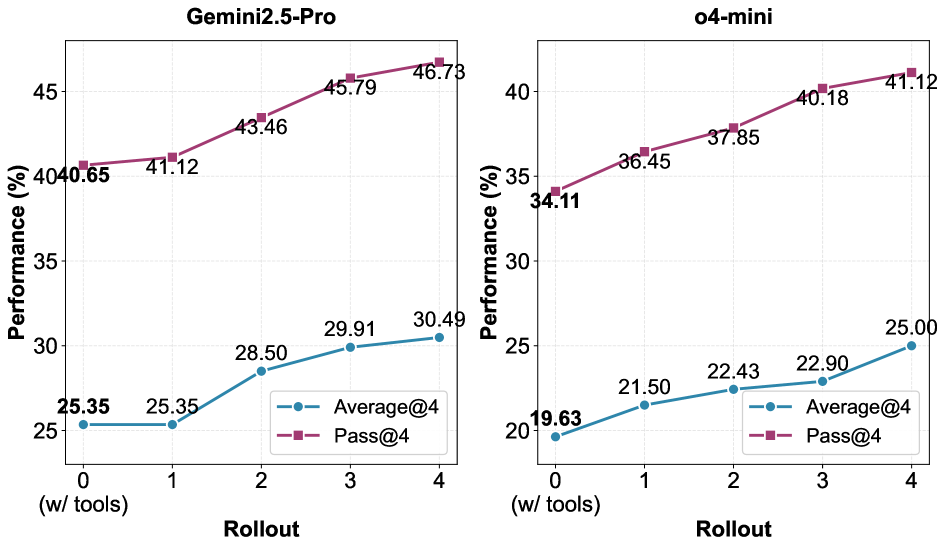
- 그림 4 설명: 롤아웃(N)이 증가할수록 성능이 꾸준히 상승하는 것을 보여줍니다. 하지만 현업 개발자 관점에서 보면 저 아름다운 우상향 그래프는 곧 ‘API 청구서 금액의 폭발적 우상향’을 의미하기도 합니다.
🔥 최종 판정 (Final Verdict): “아이디어는 훔치되, 실무 도입은 최적화 버전을 기다려라” 당장 프로덕션에 1:1로 이식하기엔 컨텍스트 윈도우 낭비와 지연 시간(Latency)이 큽니다. 하지만 에이전트를 설계할 때 단순히 프롬프트 엔지니어링에 목매는 것을 넘어, ‘액션 단위의 경험’과 ‘태스크 단위의 스킬’을 분리해서 캐싱(Caching)하는 이 프레임워크의 철학은 무조건 벤치마킹해야 합니다. LLM 시대의 개발자는 코드를 짜는 사람이 아니라, 에이전트가 스스로 코드를 짤 수 있는 ‘환경’을 구축하는 사람이 되어야 하니까요.
