[2026-02-23] 비디오 추론의 새로운 지평: VBVR(Very Big Video Reasoning) 데이터셋과 시공간 인공지능의 스케일링 법칙 심층 분석

비디오 추론의 새로운 지평: VBVR(Very Big Video Reasoning) 데이터셋과 시공간 인공지능의 스케일링 법칙 심층 분석
1. 핵심 요약 (Executive Summary)
인공지능 연구의 중심축이 텍스트(LLM)와 정적 이미지(LMM)를 넘어 비디오 추론(Video Reasoning)으로 급격히 이동하고 있습니다. 그간의 비디오 모델들이 주로 시각적 품질(Visual Quality) 향상에 집중했다면, 최근의 과제는 비디오 내의 시공간적 흐름 속에서 논리적 인과관계와 물리적 변화를 이해하는 ‘지능’의 구현입니다.
본 보고서에서 분석할 VBVR(Very Big Video Reasoning)은 기존 데이터셋 대비 약 1,000배(3 orders of magnitude) 더 큰 규모인 200만 개 이상의 비디오 클립과 200여 개의 정교한 추론 태스크를 포함하는 전례 없는 규모의 벤치마크이자 데이터 스위트입니다. 본 연구는 인지 아키텍처에 기반한 5대 핵심 역량(Perception, Spatiality, Transformation, Knowledge, Abstraction)을 정의하고, 이를 통해 비디오 모델의 스케일링 법칙(Scaling Laws)과 창발적 일반화(Emergent Generalization) 현상을 실험적으로 입증했습니다. 이는 단순한 데이터 증설을 넘어, 모델이 학습하지 않은 새로운 유형의 추론 태스크에 대해서도 논리적 대응 능력을 갖추기 시작했음을 시사하는 기념비적인 연구입니다.
2. 서론: 왜 지금 ‘비디오 추론’인가? (Introduction & Problem Statement)
현재의 생성형 비디오 모델(Sora, Runway Gen-3 등)은 눈을 매료시키는 화려한 영상을 만들어내지만, 그 이면에는 심각한 ‘물리적 비일관성’과 ‘인과관계 부재’라는 고질적인 문제가 도사리고 있습니다. 사람이 비디오를 볼 때 단순히 픽셀의 움직임을 쫓는 것이 아니라, “공이 상자 뒤로 사라졌으니 잠시 후 반대편으로 나올 것이다(연속성)”라거나 “A가 B를 밀었으니 B가 넘어질 것이다(인과성)”와 같은 시공간적 추론(Spatiotemporal Reasoning)을 수행하는 것과는 대조적입니다.
이러한 간극이 발생하는 근본적인 원인은 고품질 추론 데이터의 부족에 있습니다. 기존의 비디오 데이터셋(Video-MME, Ego-Schema 등)은 규모가 수천 개 수준에 불과하며, 대부분 인간의 주관적인 평가나 모델 기반 평가(Model-based Judging)에 의존하여 재현성과 정밀도가 떨어지는 한계가 있었습니다.
VBVR 연구팀은 이 문제를 해결하기 위해 검증 가능하고(Verifiable), 확장 가능하며(Scalable), 인지적으로 타당한(Cognitively Grounded) 대규모 비디오 추론 학습 및 평가 체계를 구축했습니다. 이는 비디오 모델이 단순히 ‘그럴듯한 영상’을 만드는 단계를 넘어 ‘물리적 세계를 이해하는 세계 모델(World Model)’로 진화하기 위한 필수적인 인프라입니다.
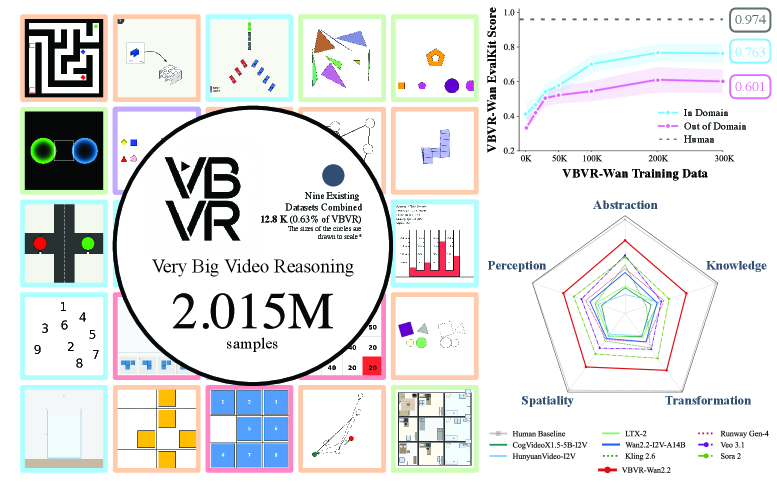 그림 1: VBVR의 전반적인 개요. 왼쪽의 그리드는 인지 아키텍처에 따른 200개 태스크의 분포를 보여주며, 중앙의 원형 그래프는 기존 9개 데이터셋 합계 대비 VBVR의 압도적인 규모(약 200만 샘플)를 시각화합니다.
그림 1: VBVR의 전반적인 개요. 왼쪽의 그리드는 인지 아키텍처에 따른 200개 태스크의 분포를 보여주며, 중앙의 원형 그래프는 기존 9개 데이터셋 합계 대비 VBVR의 압도적인 규모(약 200만 샘플)를 시각화합니다.
3. 핵심 기술 및 아키텍처 심층 분석 (Core Methodology)
VBVR의 핵심 혁신은 ‘파라미터화된 태스크 생성기(Parameterized Task Generators)’와 ‘5대 인지 역량 분류 체계’에 있습니다.
3.1 5대 인지 역량 분류 체계 (Cognitive Architecture)
연구진은 인간의 인지 발달 과정을 모방하여 비디오 추론 역량을 다음의 다섯 가지 카테고리로 구조화했습니다:
- 지각(Perception): 객체의 색상, 모양, 개수 등 기본적인 시각 속성 식별.
- 공간성(Spatiality): 3D 공간 내에서의 객체 위치, 가려짐(Occlusion), 시점 변화에 따른 공간 관계 이해.
- 변형(Transformation): 물리적 충돌, 변형, 화학적 변화 등 시간의 흐름에 따른 상태 전이 추론.
- 지식(Knowledge): 중력, 관성 등 물리 법칙이나 사전 학습된 상식의 비디오 내 적용.
- 추상화(Abstraction): 패턴 인식, 논리적 유추, 복잡한 시퀀스 내의 규칙성 발견.
3.2 파라미터화된 데이터 생성 프로세스
단순히 인터넷의 영상을 긁어모으는 대신, VBVR은 결정론적(Deterministic)으로 동작하는 태스크 생성기를 사용합니다. 이는 다음과 같은 이점을 제공합니다:
- 무한한 확장성: 객체의 종류, 배경, 물리 법칙의 상수를 조절하여 수백만 개의 유니크한 시나리오 생성 가능.
- Ground-Truth의 정밀도: 정답이 사람의 주관이 아닌 시뮬레이션 코드에 의해 결정되므로, 오차 없는 정답 라벨링이 가능함.
- Verifiable Evaluation: ‘모델 기반 평가’의 모호함을 제거하고, 규칙 기반 스코어러(Rule-based Scorer)를 통해 객관적인 성능 측정이 가능함.
 그림 2: VBVR 스위트에서 생성된 샘플 태스크 인스턴스. 각 행은 지각에서 추상화까지의 인지 영역을 대변하며, 시공간적 추론이 필수적인 시나리오들을 보여줍니다.
그림 2: VBVR 스위트에서 생성된 샘플 태스크 인스턴스. 각 행은 지각에서 추상화까지의 인지 영역을 대변하며, 시공간적 추론이 필수적인 시나리오들을 보여줍니다.
4. 구현 및 실험 환경 (Implementation Details & Experiment Setup)
대규모 데이터를 생성하고 처리하기 위해 연구진은 고도로 병렬화된 분산 컴퓨팅 아키텍처를 채택했습니다.
4.1 데이터 생성 파이프라인
- Lambda Workers: 수천 개의 서버리스 함수(Lambda)를 활용하여 각 태스크 생성기를 병렬 실행합니다. 이는 대규모 렌더링 및 물리 연산에 최적화된 구조입니다.
- Centralized Storage (S3): 생성된 비디오와 메타데이터는 중앙 집중식 S3 저장소에 실시간으로 기록되며, 후속 학습 파이프라인으로 즉시 전달됩니다.
- Scalability: 이 구조를 통해 기존 데이터셋들이 몇 달에 걸쳐 수집하던 분량을 단 며칠 만에 생성해낼 수 있었습니다.
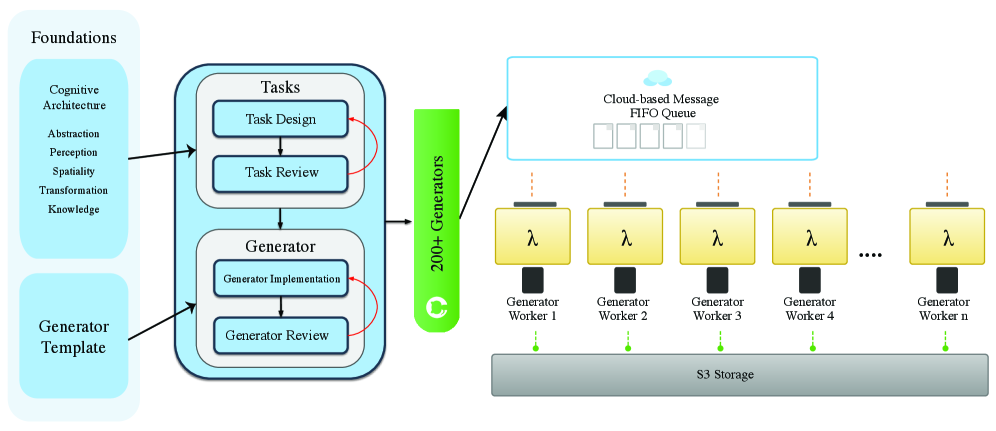 그림 3: 분산 람다 워커를 활용한 VBVR의 대규모 데이터 생성 아키텍처. 인지 설계를 기반으로 한 태스크가 클라우드 환경에서 대량으로 인스턴스화됩니다.
그림 3: 분산 람다 워커를 활용한 VBVR의 대규모 데이터 생성 아키텍처. 인지 설계를 기반으로 한 태스크가 클라우드 환경에서 대량으로 인스턴스화됩니다.
4.2 실험 대상 모델
연구팀은 현재 업계를 선도하는 비디오 언어 모델(VLM)들을 대상으로 벤치마크를 수행했습니다. GPT-4o, Gemini 1.5 Pro와 같은 폐쇄형 모델뿐만 아니라, LLaVA-Video, Video-LLaVA 등 최신 오픈소스 모델들이 포함되어 데이터의 효과를 다각도로 검증했습니다.
5. 성능 평가 및 비교 (Comparative Analysis)
VBVR의 가장 고무적인 발견은 비디오 추론 성능의 스케일링 법칙을 확인했다는 점입니다.
5.1 스케일링에 따른 성능 향상
실험 결과, 학습 데이터의 양이 기하급수적으로 늘어남에 따라 모델의 추론 정확도 역시 선형적으로 향상되는 양상을 보였습니다. 특히 중요한 점은 In-domain(학습한 태스크)뿐만 아니라 Out-of-domain(학습하지 않은 새로운 태스크)에서도 성능 향상이 관찰되었다는 것입니다. 이는 모델이 단순히 특정 시나리오를 암기하는 것이 아니라, ‘추론하는 방법(Mechanism of Reasoning)’ 자체를 학습하고 있음을 시사합니다.
5.2 인지 역량 간의 상관관계
모델들은 ‘Perception’ 영역에서는 높은 성능을 보였으나, ‘Transformation’이나 ‘Abstraction’처럼 고차원적인 인지 능력을 요구하는 영역에서는 여전히 고전하는 모습을 보였습니다. 이는 향후 비디오 AI 연구가 어느 방향으로 집중되어야 하는지를 명확히 보여주는 지표입니다.
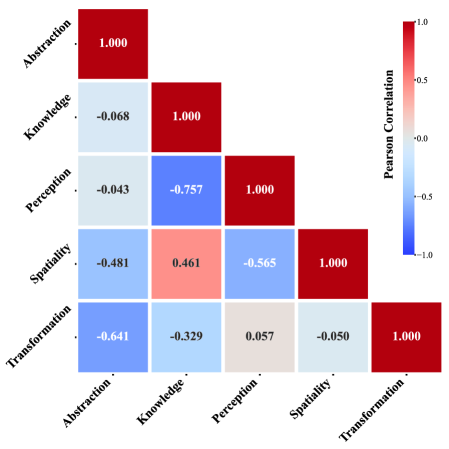 그림 5: 5대 인지 역량 간의 상관관계 분석. 모델 전반의 강점을 통제한 상태에서도 특정 역량들 사이의 구조적 의존성이 존재함을 확인할 수 있습니다.
그림 5: 5대 인지 역량 간의 상관관계 분석. 모델 전반의 강점을 통제한 상태에서도 특정 역량들 사이의 구조적 의존성이 존재함을 확인할 수 있습니다.
6. 실제 적용 분야 및 글로벌 파급력 (Real-World Application & Impact)
VBVR 데이터셋과 이를 통해 고도화된 비디오 추론 모델은 단순한 연구용 도구를 넘어 산업 전반에 파괴적인 변화를 가져올 것입니다.
자율주행 및 로보틱스 (Autonomous Systems): 단순한 장애물 감지를 넘어, 보행자의 다음 행동을 예측하거나 복잡한 교차로에서의 인과 관계를 파악하는 데 필수적입니다. VBVR의 ‘Transformation’과 ‘Spatiality’ 데이터는 로봇이 물리적 세계와 상호작용하는 능력을 비약적으로 높여줄 것입니다.
지능형 보안 및 관제 (AI Surveillance): 장면 내의 비정상적인 움직임이나 범죄 전조 증상을 논리적으로 분석할 수 있습니다. 예를 들어, “가방을 내려놓고 떠나는 행위”와 같은 시간적 선후 관계가 중요한 이벤트를 정확히 포착할 수 있습니다.
디지털 트윈 및 시뮬레이션 (Digital Twins): 가상 환경에서 복잡한 물리적 공정을 시뮬레이션하고, 그 결과를 비디오 형태로 추론하여 최적의 공정 경로를 찾는 데 활용될 수 있습니다.
콘텐츠 제작 및 편집 (AIGC): 비디오 생성 모델이 물리 법칙을 더 잘 따르게 됨으로써, 중력이 무시되거나 물체가 갑자기 사라지는 등의 ‘할루시네이션(Hallucination)’ 현상을 획기적으로 줄인 고품질 영상 제작이 가능해집니다.
7. 비판적 시각: 한계점 및 기술적 비평 (Discussion & Critique)
이 논문은 비디오 AI 분야에 획기적인 기여를 했음에도 불구하고, 몇 가지 비판적으로 검토해야 할 지점들이 있습니다.
첫째, 합성 데이터와 실제 데이터 사이의 간극(Sim-to-Real Gap)입니다. VBVR은 파라미터화된 생성기를 통해 데이터를 확보하므로 시각적인 다양성이 실제 세계의 복잡성을 완벽히 반영하지 못할 위험이 있습니다. 실험실 환경에서의 높은 추론 성적이 저화질 CCTV나 복잡한 도심 영상에서도 그대로 유지될지는 의문입니다.
둘째, ‘Clever Hans’ 효과의 가능성입니다. 모델이 정말로 물리적 법칙을 이해하는 것인지, 아니면 생성 알고리즘이 가진 특정 패턴이나 편향(Bias)을 지름길로 이용해 정답을 맞히는 것인지에 대한 더 심층적인 조사가 필요합니다. 비록 연구팀이 이를 방지하기 위해 태스크를 다양화했지만, 딥러닝 모델의 교묘한 패턴 매칭 능력을 간과해서는 안 됩니다.
셋째, 계산 비용의 문제입니다. 200만 개의 비디오를 학습시키는 데 필요한 연산 자원은 극소수의 대기업만이 감당할 수 있는 수준입니다. 이러한 거대 데이터셋 중심의 연구가 학계와 산업계의 기술 격차를 더욱 심화시킬 우려가 있습니다.
8. 결론 (Conclusion)
VBVR 연구는 비디오 AI가 ‘보는 단계’에서 ‘생각하는 단계’로 도약하기 위한 거대한 데이터 인프라를 제시했습니다. 200만 개의 정교한 추론 데이터와 이를 평가하기 위한 객관적인 벤치마크는 향후 수년간 비디오 이해(Video Understanding) 연구의 표준이 될 것으로 보입니다. 특히 스케일링에 따른 창발적 일반화의 발견은, 우리가 더 많은 데이터와 더 큰 모델을 투입할수록 AI가 세계의 물리적 논리를 스스로 깨우칠 수 있다는 강력한 희망의 메시지를 던지고 있습니다.
9. 전문가의 시선 (Expert’s Touch)
🖋️ 한 줄 평
“비디오 AI의 MNIST 모먼트가 왔다. 이제는 화려한 픽셀이 아니라 견고한 로직을 경쟁해야 할 때다.”
🛠️ 기술적 한계 및 보완점
- 물리 엔진의 정교화: 현재의 생성기는 다소 단순한 기하학적 구조에 의존하고 있습니다. 더 복잡한 유체 역학이나 파편화 모델링이 포함된 물리 엔진(Physically-based Rendering)과의 결합이 필요합니다.
- 멀티모달 통합 추론: 비디오는 시각 정보뿐만 아니라 오디오, 텍스트(자막/대화)가 결합된 매체입니다. VBVR의 추론 체계에 오디오-시각적 인과관계(Audio-Visual Causality)를 추가한다면 더욱 강력한 모델이 탄생할 것입니다.
🚀 오픈소스 및 실무 적용 포인트
- 데이터 효율적 학습(Data-Efficient Learning): 중소 규모의 기업에서는 200만 개를 다 학습시키기보다, VBVR의 태스크 중 자사 서비스와 관련성이 높은 역량(예: 로보틱스는 Spatiality)만 골라 커리큘럼 학습(Curriculum Learning)을 수행하는 전략이 유효할 것입니다.
- 검증 자동화 툴킷 활용: VBVR-Bench의 룰 기반 스코어러는 비디오 AI 서비스를 개발하는 팀에서 자체 모델의 회귀 테스트(Regression Test) 도구로 즉시 도입하기에 매우 훌륭한 수준입니다. 오픈소스화된 https://video-reason.com/ 의 리소스를 적극 활용해 보시기 바랍니다.
