[2026-03-25] AVControl: 무겁고 뚱뚱한 비디오 생성 모델은 가라, LoRA 하나로 오디오-비주얼 컨트롤 끝내는 법

[Paper Metadata]
- Title: AVControl: Efficient Framework for Training Audio-Visual Controls
- Arxiv ID: 2603.24793
- Link: https://arxiv.org/abs/2603.24793
비디오 생성 AI 씬, 솔직히 요즘 좀 피곤하지 않나요? 모델 하나 새로 나올 때마다 “우와!” 하긴 하는데, 막상 실무에서 뎁스(Depth)나 포즈(Pose), 카메라 트래킹, 심지어 오디오 제어 좀 붙이려면 VRAM이 남아나질 않죠.
기존 ControlNet 방식처럼 무거운 브랜치를 덧대거나, 모달리티 추가될 때마다 백본 아키텍처를 새로 뜯어고쳐야 하는 모놀리식(Monolithic) 접근법. 이거 인프라 비용 결제하는 C-레벨이나, 유지보수하는 ML 엔지니어들 수명 깎이는 소리가 여기까지 들립니다.
그런데 말이죠, 아키텍처 변경 일절 없이, 기존 백본은 꽁꽁 얼려둔 채 가벼운 LoRA 하나만 똑 떼서 붙이면 모든 오디오/비주얼 제어가 끝난다는 논문이 나왔습니다. 심지어 학습에 필요한 스텝은 단 수백 번. 사기 같죠? AVControl, 오늘 제대로 뜯어보겠습니다.
TL;DR: 기존 모델을 무식하게 뜯어고칠 필요 없이, LTX-2 백본 위에 Parallel Canvas(병렬 캔버스) 방식으로 참조 신호를 어텐션 토큰으로 밀어넣고 LoRA만 가볍게 학습시키는 미친 효율의 프레임워크. 모놀리식의 저주를 완벽하게 끊어냈습니다.
⚙️ 아키텍처 해부: 모놀리식의 저주를 끊어낸 ‘Parallel Canvas’
기존의 비디오 In-context 방법들은 치명적인 문제가 있었습니다. 이미지 모델에서 하던 것처럼 스페이셜(Spatial)하게 참조 이미지를 비디오 입력에 이어 붙여서(Concatenation) 먹이면, 구조를 제대로 못 따라갑니다.
솔직히 이거 실무에서 해보신 분들은 아실 겁니다. 결과물이 형체를 알아볼 수 없게 뭉개져서 바로 멘붕 오거든요. AVControl 논문에서도 이 문제를 정확히 지적합니다.

- 단순 Concatenation의 한계: 공간 구조를 억지로 이어붙이면 씬의 전반적인 의미는 파악해도 물리적 뎁스 구조가 와르르 무너져내리는 환장할 결과물을 보여줍니다.*
그래서 이들이 꺼내든 카드가 바로 Parallel Canvas(병렬 캔버스)입니다. 참조 신호(Control Signal)를 입력 채널에 억지로 욱여넣는 게 아니라, 별도의 캔버스에 두고 셀프 어텐션(Self-Attention) 레이어에서 ‘추가 토큰’으로 계산해버리는 방식이에요.
이게 왜 대단하냐면, 아키텍처 수정이 일절 필요 없다는 겁니다. LTX-2 같은 조인트 오디오-비주얼 파운데이션 모델(Backbone)은 꽁꽁 얼려두고(Frozen), 오직 LoRA 어댑터만 학습시키는 거죠.
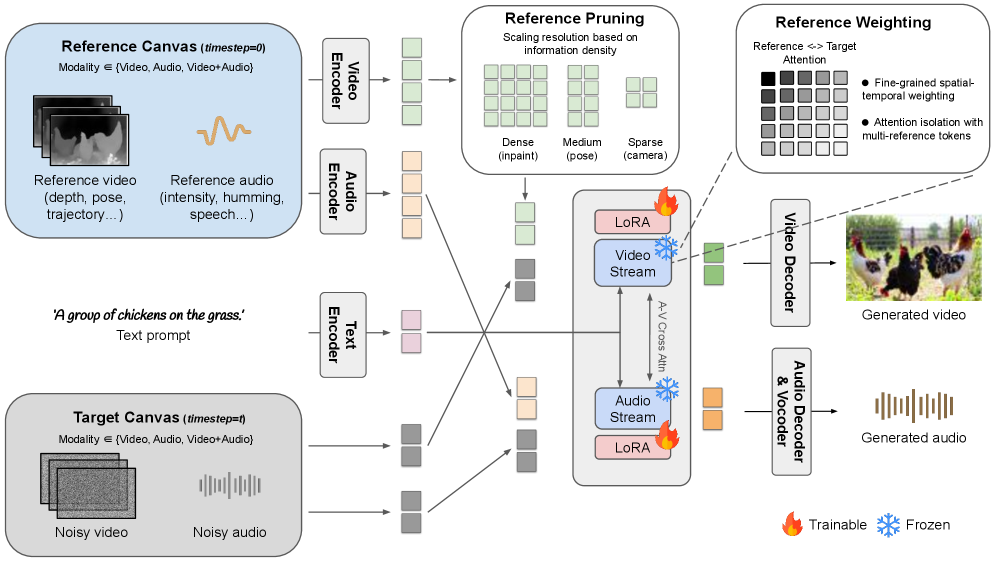
- AVControl 아키텍처 데이터 플로우: 꽁꽁 얼어붙은 백본 위로 Parallel Canvas가 어텐션의 K, V 토큰을 던집니다. 여기서 유일하게 업데이트되는 파라미터는 가벼운 LoRA 뿐입니다.*
이 구조가 코드로 어떻게 구현되는지, 제가 대략적인 데이터 플로우를 의사 코드(Pseudo-code)로 짜봤습니다. 한 번 보시죠.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# AVControl의 Parallel Canvas 동작 방식 (핵심 로직)
import torch
import torch.nn as nn
def forward_with_parallel_canvas(video_tokens, control_tokens, lora_adapter, base_model):
# 1. 백본 모델은 Frozen 상태 (기울기 계산 X, 메모리 세이브!)
with torch.no_grad():
base_qkv = base_model.get_qkv(video_tokens)
control_qkv = base_model.get_qkv(control_tokens)
# 2. Parallel Canvas의 핵심: 컨트롤 토큰을 K, V에 병합
# 아키텍처 변경 없이 Attention 연산에만 슬쩍 끼워넣습니다.
extended_k = torch.cat([base_qkv.k, control_qkv.k], dim=1)
extended_v = torch.cat([base_qkv.v, control_qkv.v], dim=1)
# 3. 확장된 컨텍스트로 어텐션 계산
hidden_states = calculate_attention(base_qkv.q, extended_k, extended_v)
# 4. LoRA 어댑터를 통한 최종 제어 신호 주입
# 각 모달리티(Depth, Pose, Audio)는 오직 자기 자신의 LoRA만 통과합니다.
output = hidden_states + lora_adapter(hidden_states)
return output
코드를 보면 아시겠지만, K(Key)와 V(Value) 텐서 차원에 컨트롤 토큰을 슬쩍 이어붙이는 게 전부입니다. 모달리티가 10개, 20개로 늘어난다고 해서 백본을 다시 굽거나 ControlNet 브랜치를 무식하게 복제할 필요가 없다는 뜻이죠. 멀티 모달리티 환경에서 메모리 효율이 여기서 미친 듯이 올라갑니다.
⚔️ 기존 스택 vs 새로운 패러다임: 진짜 갈아탈 가치가 있나?
논문에서는 VACE 벤치마크를 씹어먹었다고 자랑하는데요. 우리 개발자들이 진짜 궁금한 건 그게 아니죠. “그래서 내 GPU 랙에서 안 터지고 돌아가냐?”, “파이프라인 구축 비용은 얼만데?” 잖아요?
냉정하게 기존 SOTA 방식들과 비교해 봅시다.
| 지표 (Metrics) | 기존 Monolithic ControlNet | AVControl (Parallel Canvas) | 개발자 체감 의미 (Real-World) |
|---|---|---|---|
| 학습 파라미터 | 1B~3B 이상 (Heavy) | 수십~수백만 수준 (LoRA) | OOM(Out of Memory) 공포 탈출, 단일 노드 학습 가능 |
| 학습 소요 스텝 | 수십만 스텝 (클러스터 필수) | 200 ~ 15,000 스텝 | 점심 먹고 커피 한 잔 마시고 오면 모달리티 하나 뚝딱 완성 |
| 모달리티 확장성 | 새로운 모달리티마다 아키텍처 재설계 | LoRA 어댑터만 추가하는 플러그인 | 마이크로서비스 뺨치는 유지보수 및 확장 난이도 급락 |
| 추론 VRAM | 원본 모델 + ControlNet (약 2배) | 원본 모델 + LoRA (거의 동일) | Consumer GPU(예: RTX 4090)에서도 추론 서빙 쌉가능 |
표 보이시죠? 기존 방식은 뎁스 제어 하나 추가하려고 모델 전체를 뒤엎거나, 원본 모델만한 ControlNet을 붙여서 VRAM을 두 배로 갉아먹었습니다.
반면 AVControl은 수백에서 수천 스텝만에 수렴합니다. A100 클러스터 없이도, 적당한 H100 한 두 대만 굴리면 새로운 오디오/비주얼 컨트롤러를 입맛대로 만들어낼 수 있다는 겁니다. 데이터 효율과 컴퓨팅 효율 두 마리 토끼를 다 잡은 거죠.
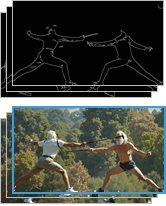
- 다중 모달리티 제어 결과: 스페이셜(Depth/Edge), 카메라 궤적, 모션, 오디오까지 모두 독립된 초경량 LoRA로 깔끔하게 떨어지는 걸 볼 수 있습니다.*
🚀 내일 당장 프로덕션에 도입한다면?
자, 이 가볍고 강력한 장난감을 실무에 어떻게 써먹을 수 있을까요? 바로 시나리오 들어갑니다.
1. 버추얼 프로덕션용 실시간 에셋 제어 파이프라인 기존에는 배우의 모션 캡처 데이터와 음성을 기반으로 영상을 생성하려면 파이프라인이 엄청나게 무거웠습니다. 하지만 AVControl을 도입하면, 카메라 트래킹 데이터용 LoRA와 오디오 반응형 LoRA를 메모리에 동시에 올려버리면 됩니다. 텍스트 프롬프트와 함께 병렬 캔버스에 쏴주기만 하면, 카메라 워킹과 입모양이 일치하는 B컷 영상을 실시간에 가깝게 뽑아낼 수 있습니다. 아키텍처 변경? 제로입니다.
2. 사용자 맞춤형 숏폼 광고 자동 생성 (Multi-tenancy 서빙) 클라이언트가 요구하는 제품의 에지(Edge) 정보와 배경음악 분위기를 매핑해야 한다고 칩시다. 백본 모델 하나만 띄워두고, 요청이 들어올 때마다 독립적으로 훈련된 Canny Edge LoRA와 Audio-Visual LoRA를 동적 로딩(Dynamic Loading)해서 붙입니다. GPU 한 대로 여러 클라이언트의 각기 다른 제어 요구사항을 VRAM 스파이크 없이 서빙할 수 있죠. 이거 인프라 팀에서 보면 눈물 흘릴 아키텍처입니다.
🚨 여기서 짚고 넘어가야 할 병목 (Bottleneck) 잠깐, 완벽해 보이지만 의문이 들죠. 병렬 캔버스로 어텐션 K, V 토큰을 늘려버리면 연산량은 어떻게 됩니까? 맞습니다. 컨트롤 토큰이 추가되기 때문에 컨텍스트 윈도우가 긴 고해상도/장시간 비디오에서는 어텐션 연산량 $O(N^2)$의 저주를 맞게 됩니다. 공식 문서에서는 ‘가볍다’고 홍보하지만, 실무에서 시퀀스 길이를 무턱대고 늘리다간 OOM(Out of Memory) 터집니다. FlashAttention이나 Ring Attention 같은 어텐션 최적화 기법 도입은 선택이 아니라 필수입니다.

- VACE 벤치마크 결과 비교: (가운데가 AVControl) 기존 SOTA인 VACE 결과물과 비교해보면 공간 구조의 충실도가 기가 막히게 유지됩니다. 이 정도면 프로덕션에 당장 던져도 클라이언트한테 욕 안 먹습니다.*
🧐 Tech Lead’s Honest Verdict
결론 내려봅시다. AVControl, 겉기운만 번지르르한 페이퍼 웨어일까요, 아니면 진짜배기일까요?
👍 Pros (장점):
- 미친 듯한 학습/추론 가성비: LoRA 하나 깎는데 수백 스텝이면 족합니다. 데이터셋도 조금만 쥐어주면 됩니다.
- 극강의 모듈화: 모놀리식의 굴레를 벗어났습니다. 모달리티별로 레고 블록 조립하듯 뗐다 붙였다 할 수 있습니다.
- 성능 보존: 백본 모델(LTX-2)의 강력한 사전 학습 지식을 조금도 훼손하지 않고 100% 빼먹습니다.
👎 Cons (단점):
- 컨텍스트 윈도우 압박: Parallel Canvas 방식 특성상 긴 시퀀스에서 메모리 스파이크 위험이 상존합니다.
- 극단적인 마이크로 싱크: 드럼 스틱이 심벌즈에 닿는 정확한 밀리초(ms) 단위의 오디오-비디오 엣지 케이스 싱크까지 완벽하게 잡아낼지는 대규모 프로덕션 트래픽을 태워봐야 확실해집니다.
🔥 Final Verdict:
“Clone immediately for internal toy projects”
지금 바로 사내 랩스(Labs)나 토이 프로젝트용으로 클론해서 굴려보세요. 만약 여러분의 팀이 뎁스나 엣지 기반 비디오 생성 서비스를 만들고 있는데 인프라 비용 때문에 피를 토하고 있다면, 기존 무거운 아키텍처 다 걷어내고 이쪽으로 파이프라인 마이그레이션을 심각하게 고려해 볼 가치가 있습니다. 코드와 체크포인트도 풀렸으니, 오늘 밤엔 야근 확정이네요.

- 독립 학습된 모달리티의 향연: 고작 200~15,000 스텝만 구워내면 이런 고품질 컨트롤 모듈들을 무한정 찍어낼 수 있다는 게 진짜 파괴적입니다. 비디오 생성 패러다임이 확실히 바뀌고 있네요.*
