[2026-03-25] AI가 내 컴퓨터를 조종하려면? 600만 프레임의 노가다가 만든 'CUA-Suite' 해부

[Metadata]
- Paper: CUA-Suite: Massive Human-annotated Video Demonstrations for Computer-Use Agents (arXiv:2603.24440)
- Date: March 2026
AI 에이전트 개발하다 보면 빡치는 순간이 한두 번이 아니죠. 특히 UI 조작 에이전트(Computer-Use Agents, CUA) 만들 때 제일 짜증 나는 게 뭔지 아세요? 학습 데이터가 죄다 ‘듬성듬성한 스크린샷’이라는 겁니다. 마우스가 A에서 B로 어떻게 이동했는지, 드래그 앤 드롭의 궤적은 어땠는지 알 길이 없죠.
기존 최대 데이터셋이라는 ScaleCUA도 꼴랑 200만 장, 시간으로 치면 20시간 분량의 스크린샷 모음집 수준이었습니다. 모델은 마우스 포인터를 자연스럽게 이동시키는 게 아니라 좌표를 찍고 ‘순간이동’ 시키려고 듭니다. 이걸로 프로덕션 레벨 에이전트를 만들라고요? 장난합니까. 그런데 이번에 나온 CUA-Suite는 이 징글징글한 병목을 55시간짜리 ‘연속 비디오’로 박살 내버렸습니다.
TL;DR: 스크린샷 몇 장 던져주던 낡은 방식을 버리고, 30fps 연속 비디오와 마우스 궤적(Kinematic trace)까지 600만 프레임으로 꽉 채운 데스크톱 조작 데이터셋 생태계. 단, 모델에 먹일 때 당신의 VRAM이 터져나가는 건 감수하셔야 합니다.
⚙️ 끊긴 스크린샷을 넘어: 30fps 궤적 데이터 파이프라인
이 녀석들이 들고 온 ‘CUA-Suite’는 단순한 데이터 덤프가 아닙니다. 파이프라인 자체가 예술이에요. 핵심은 VideoCUA입니다. 87개 전문가용 앱에서 사람이 직접 작업한 55시간 분량의 화면을 30fps로 통째로 떠버렸습니다.
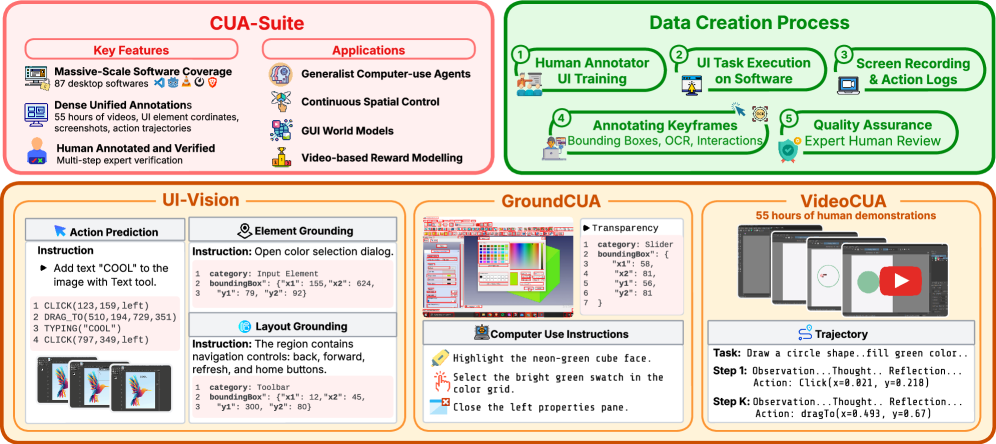
- [그림 설명] 단순 화면 녹화가 아니라, 키프레임, 바운딩 박스, 인터랙션 로그까지 전부 매핑한 CUA-Suite의 파이프라인 전모입니다. 라벨링 노가다의 결정체죠.*
데이터가 실제로 어떻게 생겼는지 까볼까요? 기존 에이전트 프레임워크들은 [클릭, x:450, y:200] 식의 1차원적인 액션만 정의했습니다. 하지만 CUA-Suite가 제공하는 연속 데이터 스트림은 결이 다릅니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
{
"timestamp": 12.334,
"frame_id": "vid_001_f0370",
"action": {
"type": "drag_and_drop",
"cursor_trajectory": [[450, 200], [452, 205], [458, 211], [460, 215]],
"click_state": "left_down"
},
"annotation": {
"reasoning_layer": "우측 툴바에서 '그라디언트 툴'을 선택해 캔버스로 드래그 중",
"bounding_boxes": [{"element": "gradient_tool", "bbox": [440, 190, 500, 220]}]
}
}
🔹 Kinematic Cursor Traces (운동학적 궤적): 위 JSON의 cursor_trajectory를 보세요. 최종 좌표만 덜렁 있는 게 아닙니다. 사용자가 마우스를 어떻게 가속하고 감속했는지, 커서의 물리적 궤적이 고스란히 들어있죠. 이걸로 Vision-Language-Action(VLA) 모델을 학습시키면, 에이전트가 진짜 사람처럼 마우스를 움직입니다.
🔹 다층적 추론 라벨링(Multi-layered reasoning): 행동만 있는 게 아니라 왜 이 행동을 했는지에 대한 추론 텍스트가 바운딩 박스와 엮여 있습니다. 여기에 360만 개 UI 요소를 밀도 높게 라벨링한 GroundCUA까지 합쳐져서, 시각적 월드 모델(Visual World Models)을 훈련하기 위한 완벽한 토대를 제공합니다.
⚔️ 기존 스택 vs CUA-Suite: 진짜 갈아탈 가치가 있나?
기존 SOTA 데이터셋이었던 ScaleCUA와 비교하면 스펙 차이가 살벌합니다. 하지만 개발자 입장에서 이게 진짜 축복일까요?
| Metric | ScaleCUA (기존 SOTA) | CUA-Suite (New) | 💡 개발자 체감 (Dev Impact) |
|---|---|---|---|
| Data Format | Sparse Screenshots | Continuous 30fps Video | 순간이동 버그 해결, 하지만 처리할 데이터량 폭증 |
| Total Size | 2M Images (<20h) | 6M Frames (~55h) | S3 스토리지 비용과 다운로드 시간 증가 |
| Action Detail | Final Click Coords | Kinematic Cursor Traces | 훨씬 부드러운 UI 제어 가능 (에러율 급감) |
| UI Annotations | Basic Grounding | 3.6M Elements (GroundCUA) | 복잡한 전문가용 앱(CAD, 포토샵) 인식률 대폭 향상 |
| Context Window | Low (단일 이미지) | Extreme (비디오 스트림) | 훈련 시 H100 8장 묶어도 VRAM 병목 발생 확률 높음 |
솔직히 데이터 질은 압도적입니다. 기존 프레임워크에서 요구하는 포맷으로 무손실(lossless) 변환도 가능하죠. 하지만 문제는 렌더링 파이프라인과 컨텍스트 윈도우입니다. 30fps 비디오 600만 프레임을 트랜스포머에 그대로 때려 박을 순 없어요. 프레임 샘플링 전략을 잘못 짜면, 인프라 비용 청구서 보고 뒷목 잡게 될 겁니다.
🚀 내일 당장 프로덕션에 도입한다면?
이 데이터셋을 실무에 어떻게 써먹을 수 있을까요? 가장 시급한 건 전문가용 데스크톱 앱 자동화입니다.
기존 파운데이션 액션 모델들을 테스트해 보면, 웹 브라우저 조작은 그럭저럭 하는데 크리타(Krita), 프리캐드(FreeCAD) 같은 복잡한 툴에선 실패율이 60%에 달했습니다. 왜 실패하는지 볼까요?
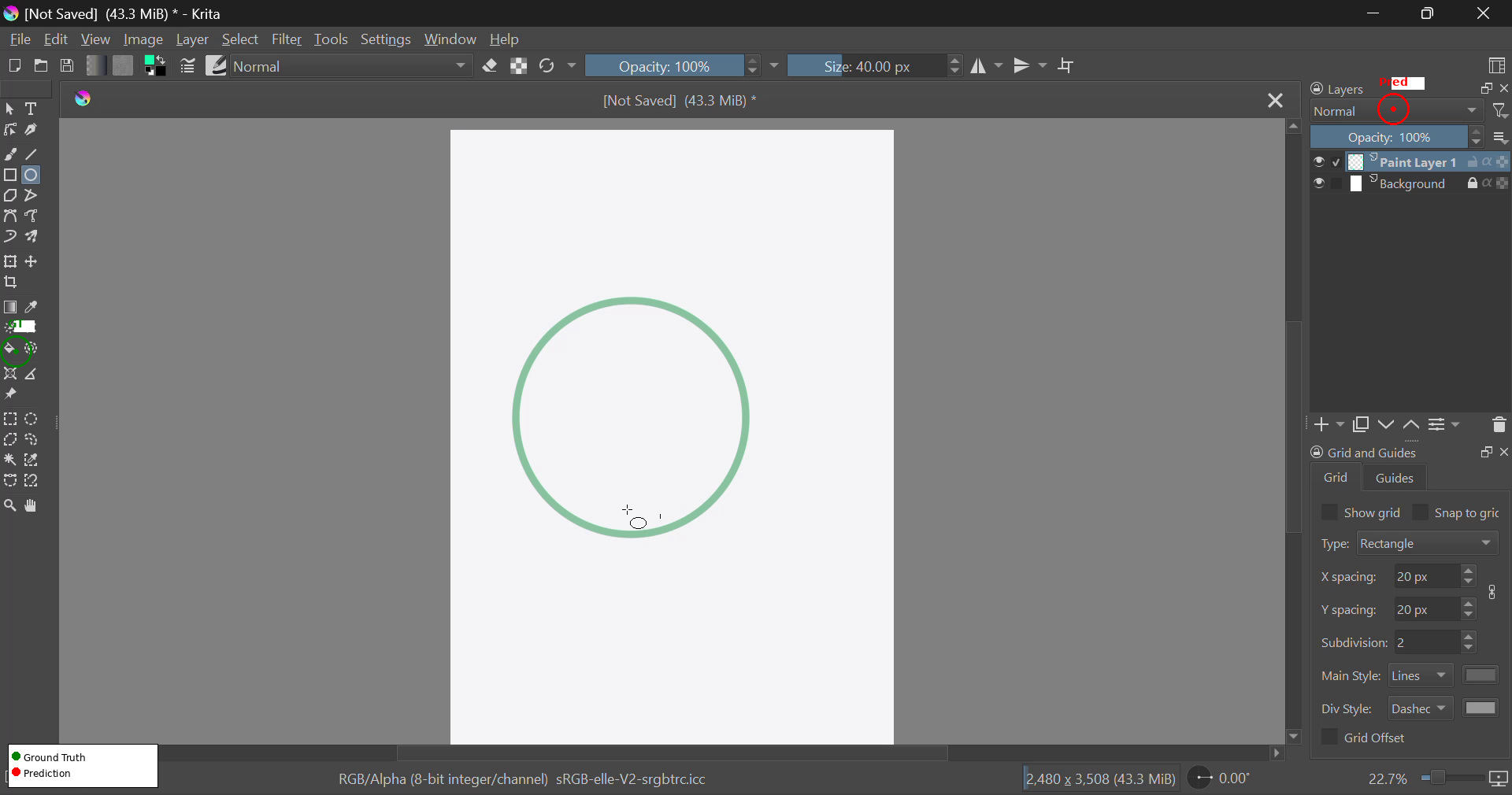
- [그림 설명] 크리타(Krita)에서 패널 간의 복잡한 UI 요소를 모델이 혼동하는 전형적인 실패 사례입니다.*
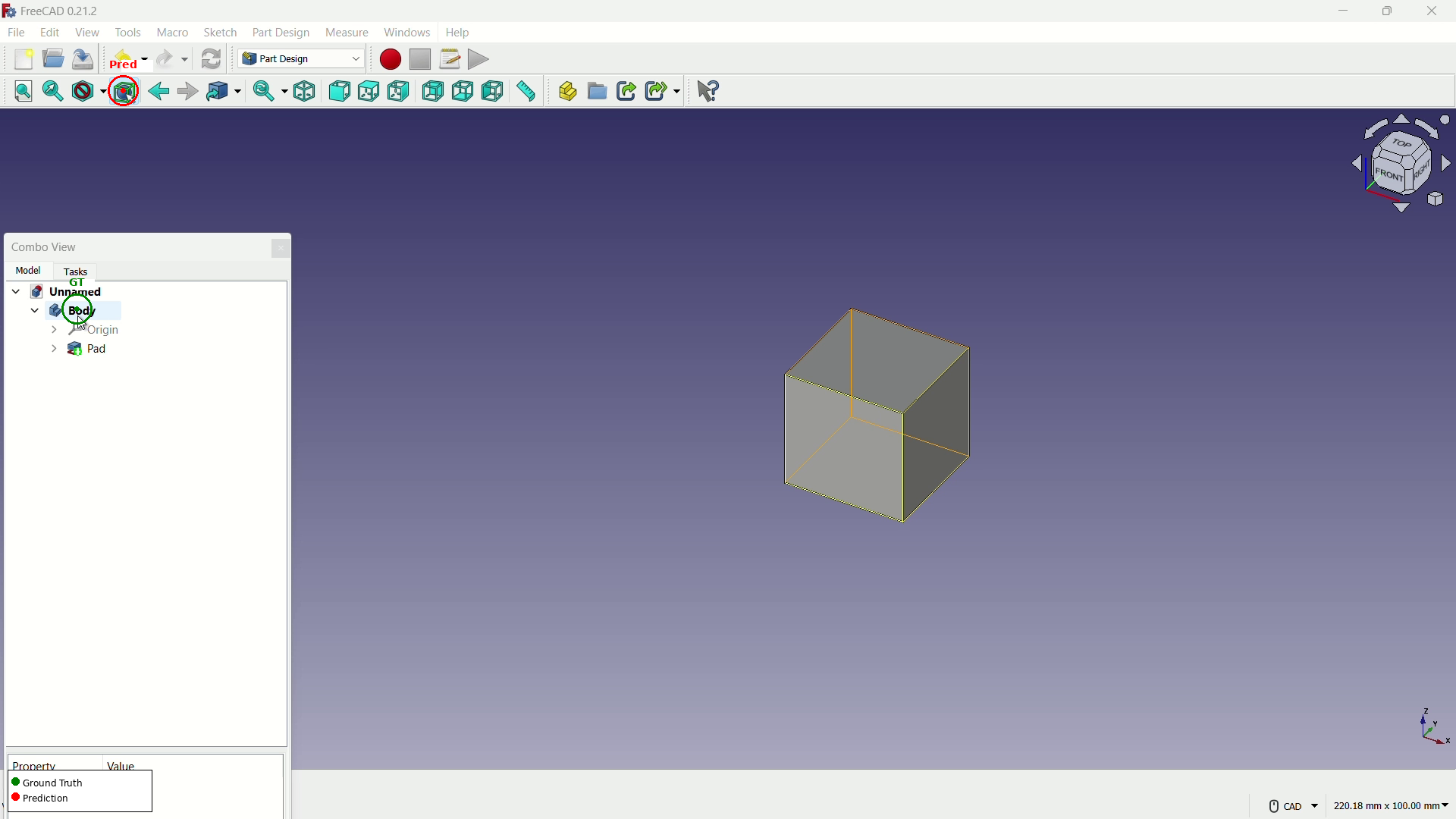
- [그림 설명] FreeCAD의 트리 구조와 상단 툴바를 제대로 구분하지 못해 엉뚱한 곳을 클릭하는 에이전트의 모습이죠.*
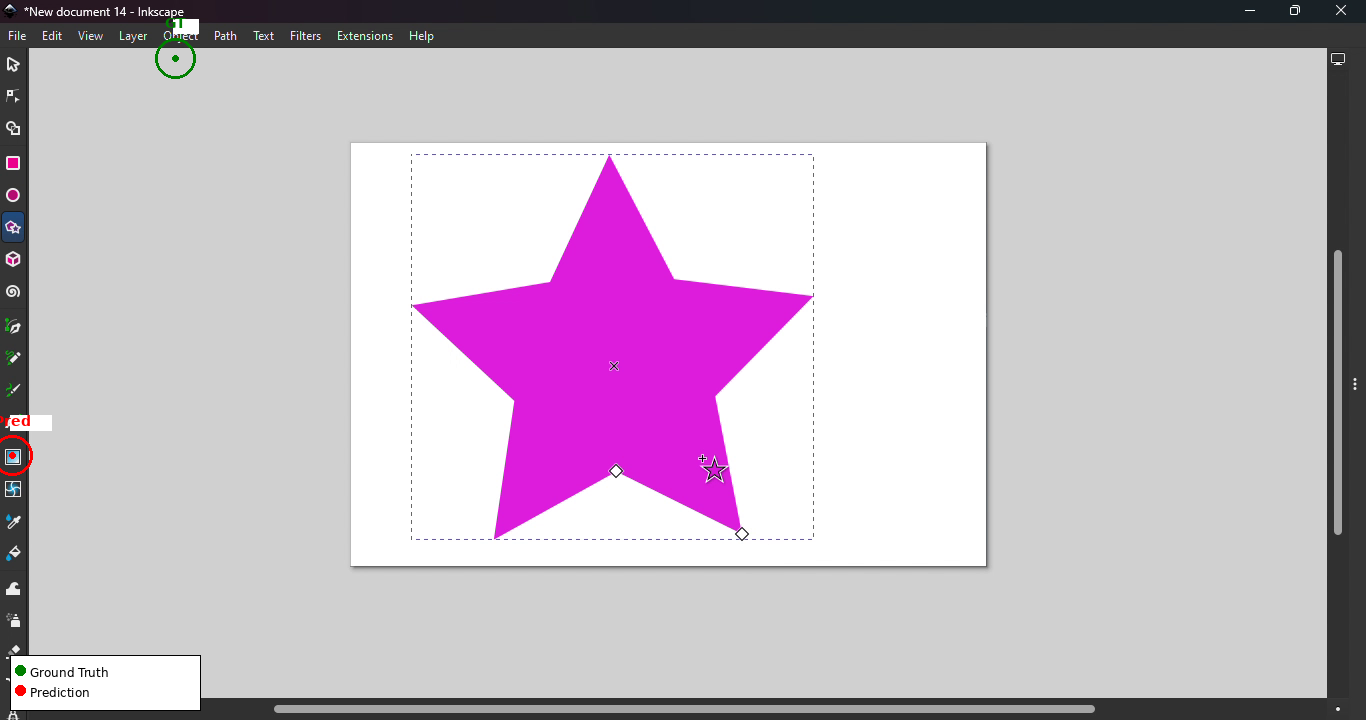
- [그림 설명] 잉크스케이프(Inkscape)의 메뉴바와 사이드바 도구 아이콘을 시각적으로 헷갈려 하는 상황입니다.*
시나리오 1: 복잡한 GUI 환경의 네비게이션 미세조정(Fine-tuning) 위 이미지들처럼 기존 모델은 툴바와 트리 메뉴를 헷갈립니다. CUA-Suite의 360만 개 UI 바운딩 박스 데이터(GroundCUA)를 활용해 비전 모델(Vision Encoder)만 따로 파인튜닝 해보세요. 전문가용 소프트웨어에서 에이전트가 엉뚱한 버튼을 누르는 대참사를 획기적으로 줄일 수 있습니다.
시나리오 2: 비디오 기반 보상 모델링 (Video-based Reward Modeling) 에이전트가 작업을 수행할 때, 결과 화면만 보고 보상을 주면 ‘어떻게’ 했는지 평가할 수 없습니다. CUA-Suite의 연속 비디오를 RLHF(인간 피드백 기반 강화학습)의 레퍼런스로 사용하세요. 에이전트가 마우스 궤적을 인간처럼 부드럽게 움직일 때 더 높은 리워드를 주도록 세팅하는 겁니다. 단, 이 과정에서 동시성(Concurrency) 문제를 조심해야 합니다. 여러 에이전트가 동시에 비디오 스트림을 처리하며 리워드를 계산하면, VRAM OOM(Out of Memory)이 밥 먹듯이 발생할 수 있습니다.
🧐 Tech Lead’s Honest Verdict
- 장점 (Pros): 스크린샷 기반 학습의 명백한 한계였던 ‘마우스 순간이동 현상’을 해결할 수 있는 마스터키입니다. 87개 앱에 대한 55시간짜리 고품질 연속 데이터는 현존 최고 수준이죠. 논문에서 제안한 UI-Vision 벤치마크도 우리 에이전트 성능 평가에 당장 써먹기 좋습니다.
- 단점 (Cons): 비디오 처리 파이프라인 구축이 지옥입니다. 무작정 원본 30fps 비디오를 모델에 밀어 넣다가는 AWS 비용으로 파산할 겁니다. 실무에 쓰려면 이 방대한 데이터를 영리하게 압축하고 키프레임을 추출하는 전처리 모듈을 직접 짜야 합니다.
- 총평 (Verdict): “연구 목적이라면 무조건 다운받고, 프로덕션용이라면 데이터 샘플링 파이프라인부터 단단히 준비해라.” AI가 내 컴퓨터를 완벽하게 제어하는 시대를 앞당길 엄청난 재료인 건 맞습니다. 하지만 이 무거운 데이터를 소화할 인프라와 엔지니어링 역량이 없다면 그저 예쁜 쓰레기가 될 수도 있습니다.
