[2026-02-05] Context Forcing: 초장기 비디오 생성의 한계를 돌파하는 새로운 패러다임 - 1분 이상의 일관성을 구현하는 기술적 심층 분석

Context Forcing: 초장기 비디오 생성의 한계를 돌파하는 새로운 패러다임
최근 생성형 AI 분야, 특히 비디오 생성(Video Generation) 영역은 Sora, Kling, Gen-3와 같은 모델들의 등장으로 가히 폭발적인 성장을 거듭하고 있습니다. 그러나 이러한 모델들이 보여주는 놀라운 시각적 퀄리티 뒤에는 여전히 해결되지 않은 거대한 기술적 장벽이 존재합니다. 바로 ‘장기적 일관성(Long-term Consistency)’입니다. 비디오의 길이가 길어질수록 배경이 일그러지거나, 캐릭터의 외형이 변하고, 물리적 법칙이 붕괴하는 현상은 현재의 자기회귀(Autoregressive, AR) 모델들이 극복해야 할 최우선 과제입니다.
오늘 분석할 논문인 “Context Forcing: Consistent Autoregressive Video Generation with Long Context”는 이러한 한계를 극복하기 위해 제안된 혁신적인 프레임워크입니다. 본고에서는 시니어 AI 사이언티스트의 시각으로 이 논문이 제시하는 해결책인 ‘Context Forcing’과 ‘Slow-Fast Memory’ 아키텍처를 심층적으로 분석하고, 이것이 비디오 생성 AI 산업에 어떤 지각변동을 일으킬지 논의해 보겠습니다.
1. 핵심 요약 (Executive Summary)
기존의 실시간 장기 비디오 생성 방식은 짧은 컨텍스트를 가진 ‘Teacher’ 모델이 긴 컨텍스트를 학습하려는 ‘Student’ 모델을 지도하는 Streaming Tuning 전략에 의존해 왔습니다. 하지만 이 과정에서 Teacher는 과거의 정보를 망각한 채 현재의 5초 내외의 정보만으로 Student를 가르치는 ‘Student-Teacher Mismatch’가 발생합니다.
Context Forcing은 이 근본적인 불일치를 해결하기 위해 ‘Long-context Teacher’를 도입합니다. Teacher가 전체 생성 이력을 인지한 상태에서 Student를 지도하게 함으로써, 전역적인 시간적 의존성(Global Temporal Dependency)을 학습할 수 있게 합니다. 또한, 연산 효율성을 위해 KV Cache를 Slow-Fast Memory 구조로 관리하여 시각적 중복성을 제거하고 컨텍스트 길이를 획기적으로 확장(기존 대비 2~10배)했습니다. 결과적으로 1분 이상의 영상에서도 피사체와 배경의 일관성을 유지하는 놀라운 성과를 거두었습니다.
2. 연구 배경 및 문제 정의 (Introduction & Problem Statement)
비디오 생성은 근본적으로 고차원의 시공간 데이터를 다루는 작업입니다. 현재 주류를 이루는 Diffusion 기반의 AR 모델들은 비디오를 여러 청크(Chunk)로 나누어 순차적으로 생성합니다. 이때 가장 큰 문제는 ‘Drift(표류)’ 현상입니다. 모델이 다음 프레임을 생성할 때 이전 프레임의 정보를 참조하지만, 그 참조 범위가 짧을수록 과거의 맥락을 잃어버리게 됩니다.
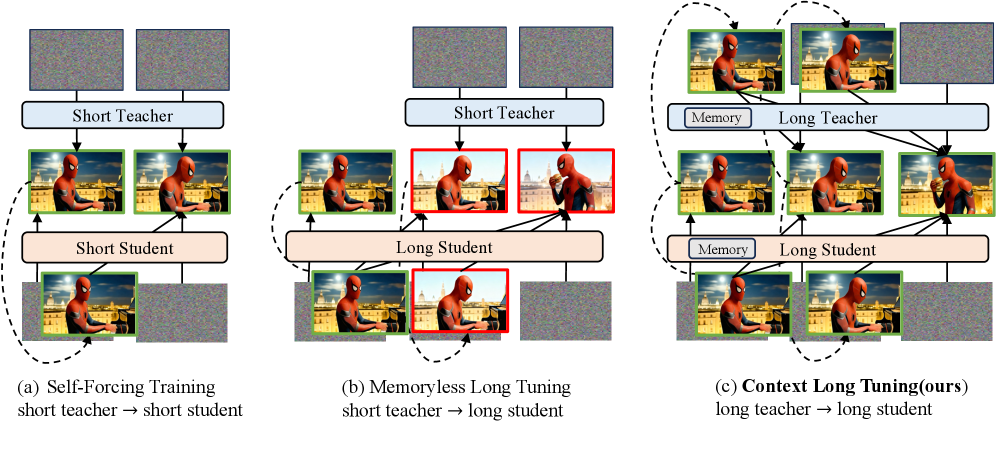 그림 2: 기존 학습 패러다임과 Context Forcing의 비교. Teacher 모델의 컨텍스트 인지 능력이 핵심 차별점이다.
그림 2: 기존 학습 패러다임과 Context Forcing의 비교. Teacher 모델의 컨텍스트 인지 능력이 핵심 차별점이다.
위 그림에서 알 수 있듯이, 기존의 LongLive와 같은 방식은 Student가 긴 구간을 생성하려 해도 Teacher 자체가 5초 분량의 윈도우만 볼 수 있는 ‘Memoryless’ 상태였기 때문에, Student에게 장기적인 일관성을 가르칠 방법이 없었습니다. 이는 마치 단기 기억 상실증에 걸린 스승이 제자에게 대서사시를 쓰라고 가르치는 것과 같습니다. 제자는 스승의 가이드에 따라 문장은 유려하게 쓰겠지만, 소설 전체의 줄거리는 엉망이 될 수밖에 없습니다.
3. 핵심 기술 및 아키텍처 심층 분석 (Core Methodology)
Context Forcing의 핵심은 두 가지입니다. 첫째는 전체 이력을 기억하는 Teacher이고, 둘째는 효율적인 컨텍스트 관리 시스템입니다.
3.1 Contextual DMD 학습 (Contextual Distribution Matching Distillation)
본 연구는 DMD(Distribution Matching Distillation)를 확장하여, 과거의 컨텍스트($C$)가 주어졌을 때 다음 프레임($x$)을 생성하는 조건부 확률 분포를 학습합니다.
\[abla_\theta \mathcal{L}_{DMD} = \mathbb{E} [w_t (\epsilon_{\text{teacher}}(x_t, C, t) - \epsilon_{\text{student}}(x_t, C, t))]\]여기서 중요한 포인트는 $C$가 단순히 직전 프레임이 아니라, Long-context Teacher가 보유한 전체 생성 이력이라는 점입니다. Teacher와 Student가 동일한 롱-컨텍스트 메모리 메커니즘을 공유함으로써, Student는 Teacher의 풍부한 경험(Long-term History)을 그대로 이식받게 됩니다.
3.2 Slow-Fast Memory 아키텍처
장기 컨텍스트를 유지하는 데 있어 가장 큰 걸림돌은 메모리(KV Cache)의 폭발적 증가입니다. 비디오 데이터는 프레임 간 중복성이 매우 높기 때문에 모든 프레임의 KV Cache를 저장하는 것은 매우 비효율적입니다. 이를 해결하기 위해 저자들은 Slow-Fast Memory 시스템을 제안합니다.
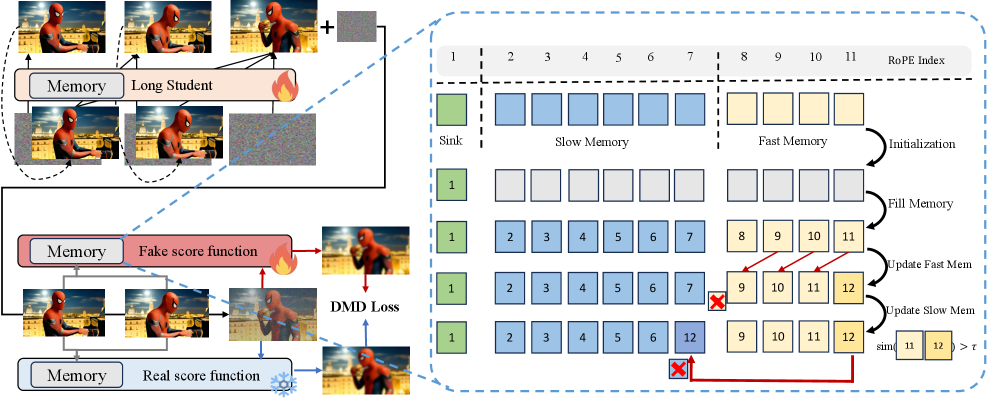 그림 3: Context Management System의 구조. Sink, Slow, Fast 세 단계로 구분된 효율적인 KV Cache 관리 전략.
그림 3: Context Management System의 구조. Sink, Slow, Fast 세 단계로 구분된 효율적인 KV Cache 관리 전략.
- Context Sink: 비디오의 가장 초기 프레임들을 고정적으로 보관합니다. 이는 비디오의 초기 설정(캐릭터, 배경의 근간)을 잃지 않게 하는 닻(Anchor) 역할을 합니다.
- Slow Memory (Low-frequency): 과거의 프레임들 중 시간적으로 멀어진 데이터들을 압축하여 보관합니다. 시간적 간격을 두고 샘플링하거나 요약된 정보를 담아 연산 부담을 줄이면서도 장기적인 맥락을 유지합니다.
- Fast Memory (High-frequency): 최근 생성된 프레임들의 상세한 정보를 보관합니다. 현재 생성 중인 움직임의 부드러움과 즉각적인 연속성을 보장합니다.
이러한 계층적 구조는 인간의 뇌가 단기 기억과 장기 기억을 처리하는 방식과 유사하며, 이를 통해 2분 이상의 영상에서도 선형적인 연산 증가 없이 컨텍스트를 유지할 수 있게 되었습니다.
4. 구현 및 실험 환경 (Implementation Details)
본 연구는 LWM(Large World Model) 및 Open-Sora Plan과 같은 강력한 베이스라인을 기반으로 구축되었습니다.
- 데이터셋: 대규모 비디오-텍스트 쌍 데이터를 사용하여 학습되었으며, 특히 일관성이 중요한 댄스, 풍경, 캐릭터 중심 영상들이 포함되었습니다.
- 학습 환경: 다수의 H100 GPU 클러스터에서 수행되었으며, Contextual DMD를 통해 추론 속도를 기존 AR 모델 대비 수십 배 향상시켰습니다.
- 핵심 지표: effective context length(ECL)라는 새로운 지표를 제안하여, 모델이 실제로 몇 초 전의 정보를 유의미하게 참조하는지 측정했습니다.
5. 성능 평가 및 비교 (Comparative Analysis)
Context Forcing의 진가는 초장기 영상 생성에서 드러납니다. 기존 SOTA 모델인 LongLive나 Infinite-RoPE와 비교했을 때, 컨텍스트 유지 능력에서 압도적인 차이를 보입니다.
 그림 4: 1분 분량 비디오 생성 비교. 타 모델들은 시간이 지남에 따라 피사체의 형태가 변하거나 배경이 무너지지만, Context Forcing은 일관성을 유지한다.
그림 4: 1분 분량 비디오 생성 비교. 타 모델들은 시간이 지남에 따라 피사체의 형태가 변하거나 배경이 무너지지만, Context Forcing은 일관성을 유지한다.
실험 결과에 따르면, Context Forcing은 20초 이상의 유효 컨텍스트 길이를 확보했습니다. 이는 기존 모델들이 2~5초 이후 급격히 정보력을 상실하는 것과 대조적입니다.
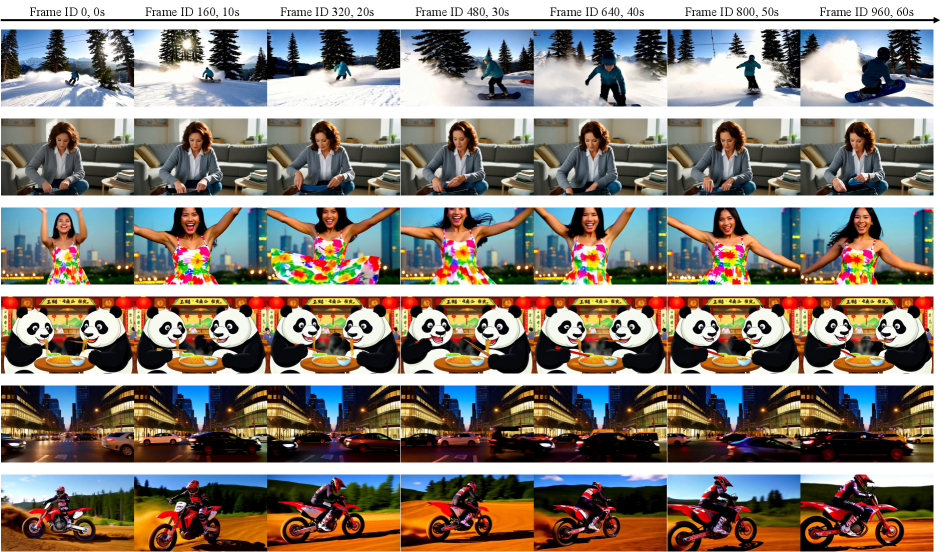 그림 5: 다양한 시나리오에서의 정성적 결과. 자연스러운 움직임과 변함없는 캐릭터 디테일이 돋보인다.
그림 5: 다양한 시나리오에서의 정성적 결과. 자연스러운 움직임과 변함없는 캐릭터 디테일이 돋보인다.
 그림 6: 비디오 연속 생성 테스트. Student가 생성한 결과를 바탕으로 Teacher가 다시 맥락을 이어가는 견고함을 보여준다.
그림 6: 비디오 연속 생성 테스트. Student가 생성한 결과를 바탕으로 Teacher가 다시 맥락을 이어가는 견고함을 보여준다.
6. 실제 적용 분야 및 글로벌 파급력 (Real-World Application)
이 기술이 상용화되었을 때의 임팩트는 단순한 ‘기술적 진보’를 넘어섭니다.
- 영화 및 애니메이션 제작: 현재의 AI 비디오는 5~10초 단위의 컷 생성에 머물러 있습니다. Context Forcing은 1~2분 정도의 롱테이크 씬을 AI만으로 생성할 수 있게 하여, 제작 비용을 혁신적으로 절감시킬 것입니다.
- 게임 산업: 실시간으로 상호작용하며 변하는 게임 세계관 내에서, 일관성 있는 환경과 NPC의 움직임을 장시간 유지하는 ‘무한 비디오 엔진’으로 활용될 수 있습니다.
- 가상 시뮬레이션: 자율주행이나 로봇 학습을 위한 고난도 시뮬레이션 환경에서, 장기적인 물리적 일관성이 보장된 학습 데이터를 무한히 생성할 수 있습니다.
7. 한계점 및 기술적 비평 (Discussion: Limitations & Critical Critique)
전문가로서 필자는 이 논문의 성과를 높이 평가하면서도, 몇 가지 날카로운 비판적 시각을 유지하고자 합니다.
- Slow Memory의 정보 손실: Slow Memory에서 수행되는 샘플링 혹은 압축 과정은 필연적으로 세부 디테일의 손실을 가져옵니다. 매우 복잡한 텍스처를 가진 배경에서 아주 미세한 변화가 누적될 때, 과연 ‘Slow’ 기법이 이를 완벽히 잡아낼 수 있을지는 의문입니다.
- Teacher 모델의 비용: Long-context Teacher를 학습 과정에서 상시 유지하는 것은 엄청난 컴퓨팅 자원을 소모합니다. 이는 중소 규모의 연구실이나 스타트업이 접근하기에는 여전히 높은 진입장벽이 될 것입니다.
- Evaluation의 주관성: 비디오 일관성에 대한 정량적 지표(FVD 등)는 여전히 인간의 시각적 인지 능력과 100% 일치하지 않습니다. 본 논문에서 제시한 ECL 지표가 업계 표준으로 자리 잡을 수 있을지는 더 지켜봐야 합니다.
8. 결론 (Conclusion & Insight)
Context Forcing은 비디오 생성 AI의 고질적인 문제였던 ‘단기 기억 상실’을 ‘구조적 불일치 해결’이라는 정공법으로 돌파했습니다. 특히 Teacher 모델에게도 긴 기억을 부여해야 한다는 직관은 단순하지만 강력한 통찰입니다.
앞으로의 비디오 AI 연구는 단순히 ‘더 큰 모델’을 만드는 것을 넘어, ‘어떻게 정보를 효율적으로 기억하고 망각할 것인가’에 집중될 것입니다. Context Forcing은 그 여정에서 매우 중요한 이정표를 세웠으며, 이제 우리는 AI가 생성한 ‘단편 영화’를 넘어 ‘장편 영화’를 보게 될 날에 한 걸음 더 가까워졌습니다.
AI 기술의 발전 속도는 우리의 상상을 초월합니다. 이러한 최신 기술의 흐름을 놓치지 않고 비즈니스와 연구에 녹여내는 혜안이 필요한 시점입니다.
