[2026-03-24] 수천 초짜리 영상 분석, 토큰 폭탄 없이 가능할까? 엔드투엔드 비디오 에이전트 EVA 해부

[Paper] [2603.22918] EVA: Efficient Reinforcement Learning for End-to-End Video Agent [Github] https://github.com/wangruohui/EfficientVideoAgent
비디오 데이터를 MLLM(Multimodal LLM)에 던져넣을 때 우리가 겪는 환장할 노릇이 뭔지 아시죠? 2시간짜리 영상에서 ‘주인공이 파란색 모자를 쓴 정확한 시점’을 찾으려면 어떻게 해야 할까요?
지금까지의 무식한 접근법은 그냥 영상을 N개의 프레임으로 쪼개서 몽땅 컨텍스트 윈도우에 쑤셔 넣는 거였습니다. 결과는? VRAM은 터져나가고, API 호출 비용은 천정부지로 솟구치죠. 더 끔찍한 건, 모델이 그 긴 토큰의 늪에서 허우적대다가 정작 2초짜리 핵심 장면은 놓치고 환각(Hallucination)을 뱉어낸다는 겁니다. 최근에 나온 툴 기반 에이전트(Tool-based Agent)들도 외부 API를 호출하긴 하지만, 여전히 수동으로 짠 워크플로우에 갇혀 있어서 긴 비디오 앞에서는 속수무책이거든요.
이런 답답한 상황에서 등장한 EVA(Efficient Video Agent)는 꽤나 우아한 해결책을 제시합니다. 비디오를 수동적으로 인식(Perception)하는 걸 넘어서, 에이전트 스스로 ‘언제, 무엇을, 어떻게 볼지’ 먼저 계획(Planning)하게 만들었거든요.
TL;DR: EVA는 무지성 프레임 샘플링을 버리고, 에이전트가 스스로 동영상을 탐색하도록 만든 강화학습(RL) 기반 비디오 에이전트입니다. SFT -> KTO -> GRPO로 이어지는 3단계 파이프라인으로 토큰 효율과 추론 능력을 극대화했죠. 단, 초기 추론 레이턴시는 꽤 각오해야 할 겁니다.
⚙️ 비디오 토큰 다이어트와 자율 주행의 결합, EVA 파이프라인 해부
EVA의 핵심 아키텍처는 Summary-Plan-Action-Reflection의 무한 루프입니다. 전체를 대충 훑고, 의심 가는 곳을 파고들고, 아니면 다시 돌아가는 인간의 비디오 탐색 방식을 그대로 모방했죠.
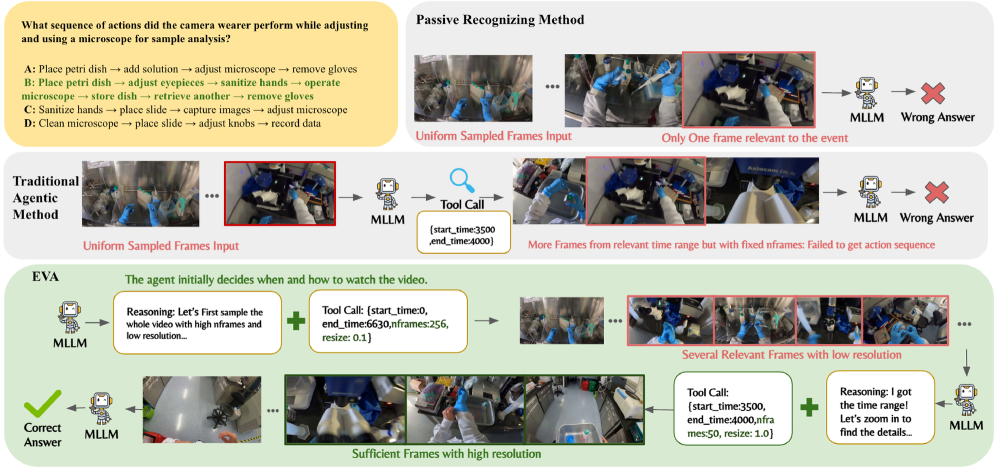
- [그림 1] 기존의 무식한 균일 샘플링(Uniform Sampling)과 EVA의 탐색 방식 비교. 토큰을 낭비하지 않고 핵심 구간만 고해상도/고프레임으로 파고드는 전략이 핵심입니다.
이게 실제로 어떻게 돌아가는지, EVA의 내부 사고 흐름(데이터 플로우)을 JSON 형태의 목업(Mock)으로 뜯어볼까요?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
{
"step": 1,
"summary": "유저가 '도둑이 빨간 차 창문을 깬 시간'을 물었다. 전체 2시간 영상이다.",
"plan": "전체를 다 보는 건 미친 짓이다. 우선 전체 타임라인을 100배속(낮은 해상도)으로 훑어서 수상한 움직임을 찾자.",
"action": "extract_frames",
"parameters": {
"start_time": 0,
"end_time": 7200,
"fps": 0.01,
"resolution": "low"
},
"reflection": "45분~46분 사이에 주차장에 사람이 나타난 실루엣이 보인다. 정답을 확정하기엔 해상도가 낮다. 해당 1분 구간만 5fps, 고해상도로 다시 추출하자.",
"next_step": 2
}
🔹 동적 시각 토큰 할당 (Dynamic Token Allocation): 여기서 진짜 감탄한 포인트는 에이전트가 fps와 resolution 파라미터를 동적으로 조절한다는 겁니다. 기존 에이전트들은 툴을 호출해도 하드코딩된 해상도로만 이미지를 가져왔죠.
하지만 이런 똑똑한 에이전트를 그냥 프롬프트 엔지니어링으로 만들 수 있을까요? 절대 아닙니다. 연구진은 이를 위해 피 토하는 3단계 학습 파이프라인을 구축했습니다.
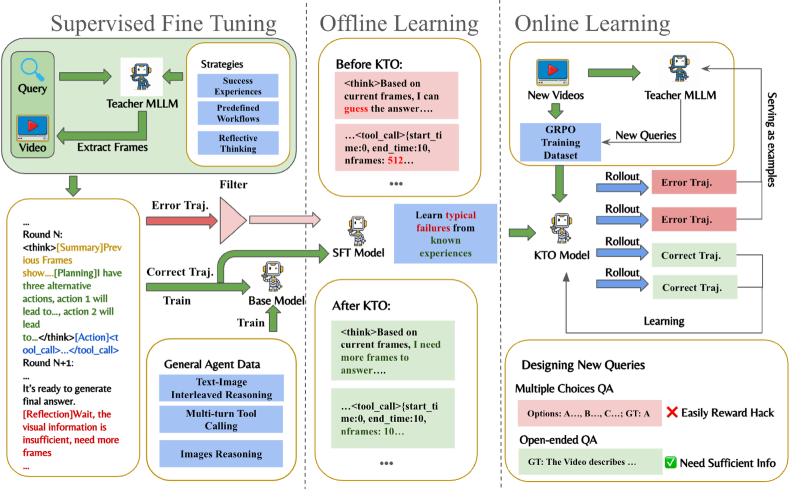
- [그림 2] EVA의 3단계 학습 파이프라인. SFT로 기본기를 다지고, KTO로 오답을 교정하며, 최종적으로 GRPO를 통해 에이전트의 탐색 정책을 최적화합니다.
- SFT (Supervised Fine-Tuning): 먼저 합성 데이터셋으로 에이전트에게 ‘도구 사용법’과 ‘기본적인 추론 패턴’을 강제로 주입합니다.
- KTO (Kahneman-Tversky Optimization): 모델이 자주 저지르는 전형적인 실패 사례(예: 엉뚱한 타임스탬프 탐색)를 모아서 KTO로 교정합니다. DPO(Direct Preference Optimization)처럼 굳이 페어(Pair) 데이터를 만들 필요 없이 실패/성공 여부만으로 최적화가 가능해서 데이터 구축 비용을 확 줄였죠.
- GRPO (Generalized Reward Policy Optimization): 여기서 끝판왕이 등장합니다. 무거운 Value Network를 메모리에 올릴 필요 없이 레퍼런스 모델 대비 상대적인 리워드만으로 정책을 최적화하는 GRPO를 썼습니다. VRAM이 부족한 MLLM 환경에서 강화학습을 돌리기 위한 처절하고도 훌륭한 선택입니다.
⚔️ 기존 스택 vs 새로운 패러다임: 진짜 갈아탈 가치가 있나?
그렇다면 우리가 기존에 쓰던 GPT-4V + LangChain 조합을 버리고 EVA 아키텍처를 도입할 가치가 있을까요? 냉정하게 숫자로 비교해 봅시다.
| 비교 항목 | 무지성 균일 샘플링 (기존 MLLM) | 툴 기반 에이전트 (LangChain 등) | EVA 프레임워크 (New!) |
|---|---|---|---|
| 토큰 소모량 (비용) | 매우 높음 (전체 영상 토큰화) | 중간 (고정된 툴 호출) | 최저 (필요한 구간만 추출) |
| VRAM 점유율 | 터지기 일보 직전 (OOM 위험) | 중간 | 매우 낮음 (적응형 해상도) |
| 미세 행동 포착력 | 낮음 (프레임 사이의 액션 누락) | 중간 (툴 성능에 의존) | 매우 높음 (동적 FPS 조절) |
| 추론 레이턴시 | 낮음 (One-pass 추론) | 높음 (API 여러 번 호출) | 매우 높음 (루프 반복) |
| 인프라 세팅 난이도 | 쉬움 (API 호출 한방) | 보통 | 매우 어려움 (RL 파이프라인 구축) |
표를 보면 명확해집니다. 인프라 비용과 메모리 최적화 측면에서는 EVA가 압도적입니다. 컨텍스트 윈도우를 쓸데없는 배경 프레임으로 낭비하지 않으니까요.
하지만 추론 레이턴시라는 치명적인 트레이드오프가 존재합니다. 모델이 루프를 돌며 스스로 “어? 여긴 없네. 다른 구간 찾아봐야지” 하고 여러 번 추론을 수행해야 하므로, 실시간성이 중요한 서비스에서는 절대 쓸 수 없는 구조입니다.
🚀 내일 당장 프로덕션에 도입한다면?
이 아키텍처를 실제 프로덕션 환경에 올리면 어떤 일이 벌어질까요? 두 가지 시나리오를 생각해 볼 수 있습니다.
시나리오 1: 대규모 CCTV 보안 관제 비동기 분석 24시간 쌓이는 수천 개의 CCTV 영상에서 ‘새벽 시간대 창문을 넘는 사람’을 찾는 작업을 자동화한다고 칩시다. 기존 모델로는 엄두도 못 낼 일이지만, EVA 아키텍처를 배치(Batch) 파이프라인으로 돌리면 기가 막히게 작동할 겁니다. 전체를 100배속으로 훑어 피사체의 움직임을 찾고, 그 순간만 고해상도로 줌인해서 사람인지 길고양이인지 판별할 테니까요. VRAM을 적게 먹으니 GPU 인스턴스 하나에 여러 개의 워커를 띄우기도 좋습니다.
시나리오 2: 스포츠 하이라이트/반칙 영상 자동 추출 90분짜리 축구 경기에서 ‘심판이 오심을 한 것으로 의심되는 태클 장면’을 찾는다면 어떨까요? EVA는 훌륭한 탐색 능력을 보여주겠지만, 병목(Bottleneck) 현상을 조심해야 합니다. 만약 동시 접속자가 100명이고 각자 다른 경기를 검색한다면? EVA는 에이전틱 루프를 돌기 때문에 KV Cache 관리가 지옥으로 변합니다. 모델이 Reflection 단계를 거칠 때마다 이전의 시각적 컨텍스트를 유지해야 하는데, vLLM 같은 서빙 엔진에서 Multi-turn 비전 토큰에 대한 KV Cache 페이징이 완벽하게 세팅되어 있지 않으면 메모리 파편화로 서버가 뻗어버릴 수 있습니다.
🧐 Tech Lead’s Honest Verdict
그래서 이걸 써야 하냐고요? 장단점을 까놓고 얘기해 보죠.
장점 (Pros):
- 압도적인 토큰 다이어트: 더 이상 롱폼 비디오를 분석하기 위해 토큰 지갑을 털리지 않아도 됩니다.
- RL 기반의 현실적인 학습 파이프라인: VRAM을 아끼기 위해 GRPO를 채택하고, DPO 대신 KTO를 써서 데이터 구축 허들까지 낮춘 연구진의 엔지니어링 감각은 정말 박수받아 마땅합니다.
단점 (Cons):
- 응답 속도의 한계: 사용자가 질문하고 1초 만에 답이 튀어나오는 마법을 기대하지 마세요. 에이전트가 비디오를 앞뒤로 돌려보는 ‘생각의 시간’이 필요합니다.
- 재현성(Reproducibility)의 늪: SFT -> KTO -> GRPO로 이어지는 학습 파이프라인은 논문으로 볼 땐 아름답지만, 막상 내 로컬 환경에서 도메인 특화 데이터로 처음부터 다시 학습시키려면 하이퍼파라미터 튜닝 지옥을 맛볼 확률이 높습니다.
🔥 최종 판정 (Final Verdict):
“내부 비동기 데이터 처리용 PoC로 즉시 클론(Clone)하세요.”
사용자에게 직접 노출되는 실시간 B2C 서비스에 당장 붙이는 건 자살 행위입니다. 하지만 백엔드에서 대용량 비디오 데이터를 정제하고, 라벨링을 자동화하거나, 비동기로 하이라이트를 추출하는 사내 시스템을 만들 생각이라면? EVA는 현재 여러분의 GPU 클라우드 비용을 절반 이하로 후려쳐줄 수 있는 가장 현실적인 솔루션입니다.
Additional Figures
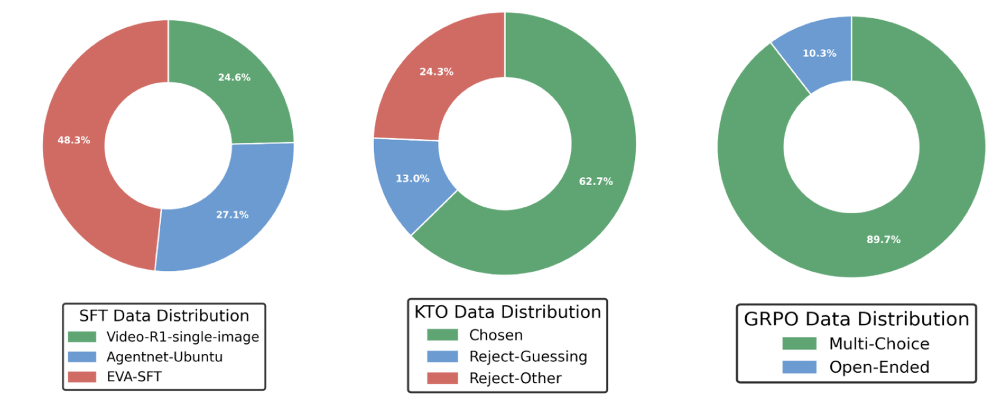 Figure 3:Distribution of the Training Dataset
Figure 3:Distribution of the Training Dataset
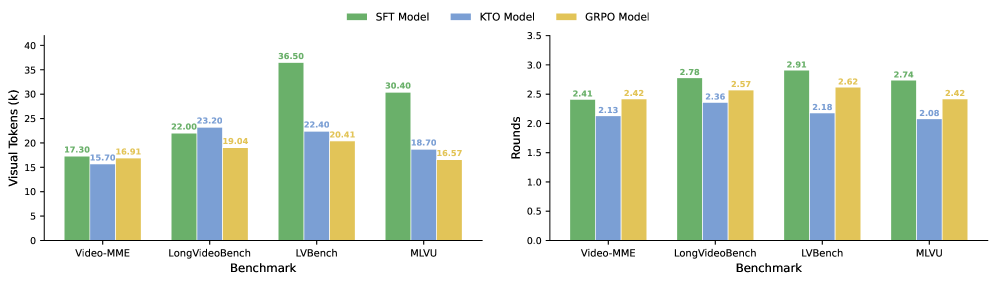 Figure 4:Distribution of Rounds and Visual Token cross Models and Benchmarks
Figure 4:Distribution of Rounds and Visual Token cross Models and Benchmarks
 (a)
(a)
