[2026-02-22] JavisDiT++ 분석: Veo3 잡는 오픈소스 비디오 AI? 완벽한 A/V 싱크의 비밀

[Metadata Block]
- 📖 논문: arXiv:2602.19163
- 🖥️ Github/Project: JavisVerse
- 📅 발표일: 2026년 2월 (arXiv 기준)
- ✍️ 저자/기관: JavisVerse Team
[Introduction: The Hook] 요즘 Sora니 Veo3니, 상용 비디오 생성 AI들의 발전 속도가 정말 무섭죠? 하지만 오픈소스 진영의 반격도 만만치 않습니다. 지금까지 오픈소스 오디오-비디오 동시 생성(JAVG) 모델들은 항상 “소리와 영상이 묘하게 엇박자를 타는” 고질적인 싱크 문제와 퀄리티 저하에 시달렸습니다. 솔직히 실무 프로덕션에 당장 쓰기엔 무리가 있었죠. 그런데 이번에 등장한 JavisDiT++는 다릅니다. 고작 100만 개의 데이터만 학습하고도, 시각과 청각을 완벽하게 동기화해내는 놀라운 퍼포먼스를 보여주네요. 상용 모델과의 격차를 어떻게 이렇게 좁혔을까요?
💡 한 마디로? 텍스트 한 줄로 완벽하게 싱크가 맞는 고화질 영상과 고음질 사운드를 동시에 뽑아내는, 가성비 미친 오픈소스 생태계의 게임 체인저.
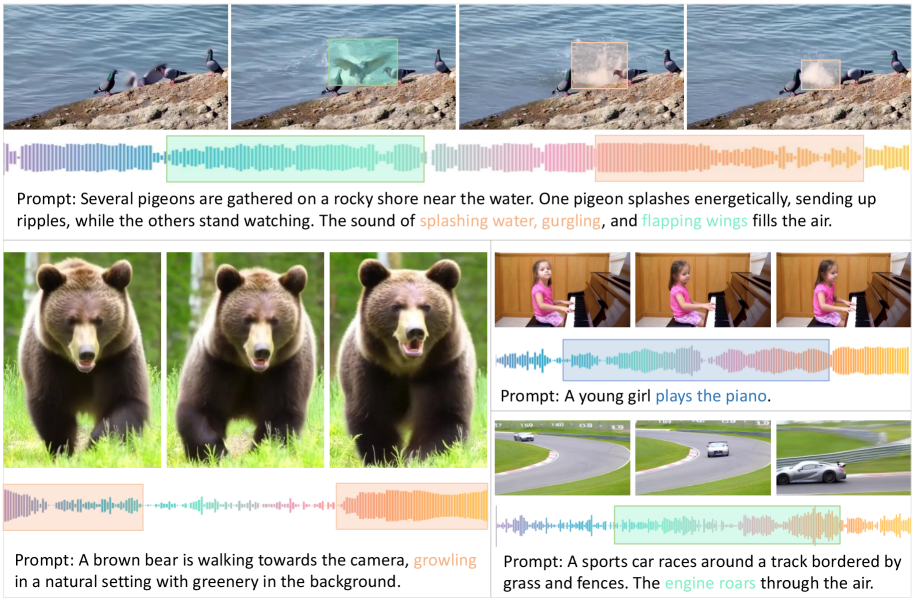 영상과 소리가 따로 놀던 엉성한 오픈소스의 시대는 이제 끝을 향해 가는 것 같습니다.
영상과 소리가 따로 놀던 엉성한 오픈소스의 시대는 이제 끝을 향해 가는 것 같습니다.
[Body Section 1: 도대체 무엇이 다른가요?] 기존의 오디오-비디오 생성 모델들은 마치 영상 감독과 음향 감독이 서로 다른 방에서 일하는 것과 같았습니다. 영상 따로, 소리 따로 만들고 나중에 편집실에서 억지로 합치려니 어색할 수밖에 없었죠. JavisDiT++는 이 둘을 한 방에 몰아넣고, 동일한 뇌를 공유하게 만들었습니다.
이 녀석의 핵심 무기는 크게 세 가지입니다: 🔹 모달리티 특화 전문가(MS-MoE): 뇌(Attention)는 공유해서 전체적인 흐름을 맞추되, 손발(FFN)은 각자의 전문 영역(오디오/비디오)에 맞게 독립적으로 움직입니다. 🔹 시간 동기화(TA-RoPE): 비디오 프레임과 오디오 파형이 1:1로 정확하게 톱니바퀴처럼 맞물리도록 설계되었습니다. 입 모양과 목소리가 어긋나지 않게요. 🔹 인간 선호도 정렬(AV-DPO): LLM에서 쓰던 DPO(직접 선호도 최적화)를 멀티모달에 가져왔습니다. 기계의 기준이 아닌, 인간의 눈과 귀에 자연스러운 결과물을 만듭니다.
[Body Section 2: 핵심 기능 및 성능 비교] 솔직히 이 논문을 읽으면서 가장 놀랐던 부분은 바로 ‘효율성’입니다. Wan2.1-1.3B-T2V를 베이스로 단 100만 개의 공개 데이터만 사용했는데도 오픈소스 기준 압도적인 SOTA(State-of-the-Art)를 찍었습니다.
| 구분 | JavisDiT++ (본 논문) | 기존 오픈소스 JAVG 모델 | 상용 모델 (Veo3 등) |
|---|---|---|---|
| A/V 동기화 (Sync) | 매우 우수 (TA-RoPE 적용) | 낮음 (어긋남 잦음) | 압도적 우수 |
| 학습 데이터 비용 | 초고효율 (~1M 데이터) | 방대한 데이터 필요 | 천문학적 비공개 데이터 |
| 생성 퀄리티 (선호도) | 우수 (AV-DPO 적용) | 보통 ~ 낮음 | 최고 수준 |
| 접근성 | 완전 오픈소스 (코드/데이터 공개) | 일부만 공개 | 완전 비공개 (API 형태) |
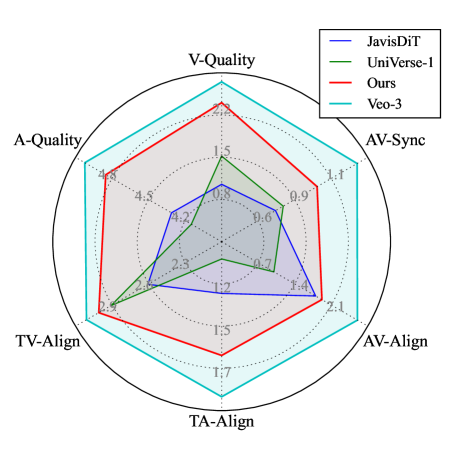 성능 지표를 보면 확실히 기존 오픈소스 모델들을 질적, 양적으로 모두 압도합니다. 데이터 대비 가성비가 미쳤네요.
성능 지표를 보면 확실히 기존 오픈소스 모델들을 질적, 양적으로 모두 압도합니다. 데이터 대비 가성비가 미쳤네요.
이 결과가 실무에서 중요한 이유는 명확합니다. 수백만 달러의 GPU 비용 없이도, 이제 스타트업이나 개인 리서처가 인간의 선호도에 맞게 미세 조정된 고품질 멀티모달 모델을 직접 튜닝하고 서비스에 올릴 수 있다는 뜻이니까요.
[Body Section 3: 기술적 톺아보기 (조금 더 깊게)] 엔지니어라면 이들이 어떻게 이런 효율을 냈는지 아키텍처가 궁금하실 겁니다. 가볍게 핵심만 짚어보죠.
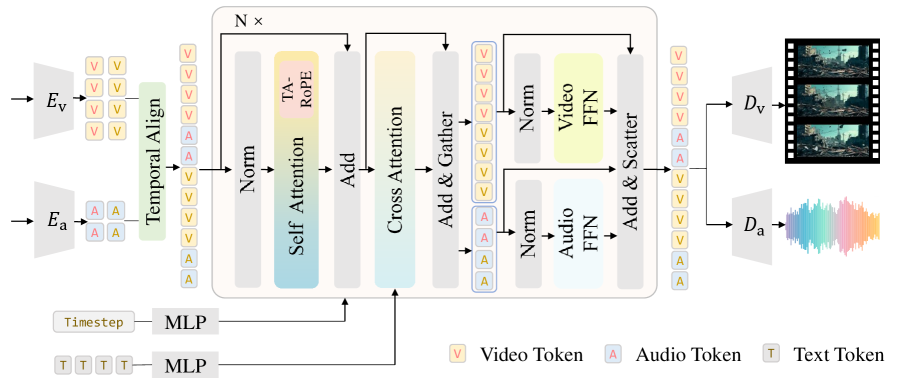 공유 어텐션으로 서로의 정보를 교환하고, 독립적인 FFN 구조로 각 모달리티의 퀄리티 손실을 막는 발상이 아주 인상적입니다.
공유 어텐션으로 서로의 정보를 교환하고, 독립적인 FFN 구조로 각 모달리티의 퀄리티 손실을 막는 발상이 아주 인상적입니다.
가장 눈여겨볼 부분은 TA-RoPE(Temporal-Aligned RoPE)입니다. 오디오와 비디오는 본질적으로 샘플링 주기가 다르기 때문에 시간 축을 맞추기 굉장히 까다롭습니다. JavisDiT++는 이를 토큰 레벨에서 명시적으로 동기화했습니다.
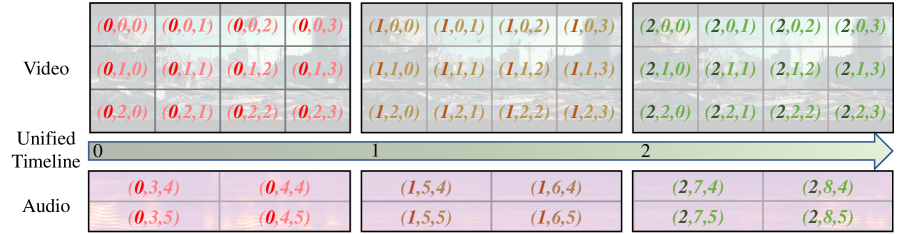 토큰 수준에서 시간 축을 억지로 꿰맞추는 게 아니라, 회전 위치 인코딩(RoPE)을 통해 자연스럽게 동기화하는 영리한 접근이죠.
토큰 수준에서 시간 축을 억지로 꿰맞추는 게 아니라, 회전 위치 인코딩(RoPE)을 통해 자연스럽게 동기화하는 영리한 접근이죠.
개념적으로 코드로 표현하자면 이런 느낌일 겁니다:
1
2
3
4
5
6
7
8
9
10
11
# TA-RoPE Pseudo-code concept
def apply_ta_rope(video_tokens, audio_tokens, time_steps):
# 비디오와 오디오의 시간 축 엠베딩을 공통된 프레임 타임라인에 맞춤
aligned_t_emb = get_temporal_alignment(time_steps)
# 각 모달리티별 RoPE 적용 전, 시간축 동기화를 하드코딩된 규칙이 아닌
# 구조적으로 강제(Align)함
video_rope = apply_rotary_emb(video_tokens, aligned_t_emb)
audio_rope = apply_rotary_emb(audio_tokens, aligned_t_emb)
return video_rope, audio_rope
여기에 방점을 찍는 것이 AV-DPO입니다. 모델이 생성한 여러 샘플 중, 사람이 보기에 품질, 일관성, 동기화가 더 뛰어난 것을 직접 골라 최적화합니다.
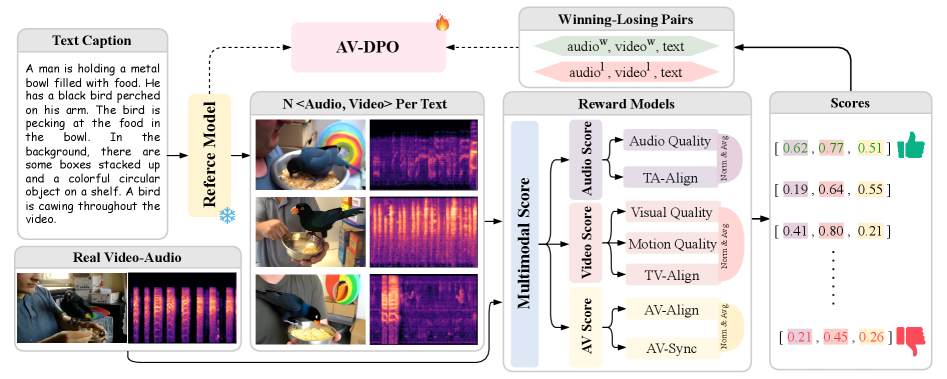 단순 품질뿐만 아니라 시청각의 ‘일관성’과 ‘동기화’까지 평가 항목으로 분리해서 넣은 파이프라인. LLM의 RLHF가 비디오 모델로 완벽히 이식되었네요.
단순 품질뿐만 아니라 시청각의 ‘일관성’과 ‘동기화’까지 평가 항목으로 분리해서 넣은 파이프라인. LLM의 RLHF가 비디오 모델로 완벽히 이식되었네요.
[Conclusion: 🔥 에디터의 생각 (Editor’s Verdict)]
👍 장점 (Pros)
- 미친 가성비: 단 100만 개의 데이터셋으로 이 정도의 SOTA를 달성했습니다. 자원이 부족한 연구실이나 스타트업에게는 한 줄기 빛이네요.
- 완벽에 가까운 싱크: 영상과 소리가 엇나갈 때 느껴지는 불쾌한 골짜기를 TA-RoPE와 DPO의 결합으로 영리하게 극복했습니다.
- 착한 오픈소스: 모델 가중치뿐만 아니라 코드, 데이터셋(가장 구하기 힘든!)까지 모두 공개했습니다.
👎 아쉬운 점/한계 (Cons)
- 베이스 모델의 체급 한계: Wan2.1-1.3B라는 비교적 작은 모델을 베이스로 하다 보니, Veo3 같은 수백B 파라미터의 초대형 모델이 뿜어내는 ‘압도적인 물리법칙 이해도’나 극강의 해상도까지 기대하기엔 아직 2% 부족해 보입니다.
- 복잡한 씬에서의 검증: 폭발음, 대사, 배경음악이 마구 섞이는 매우 복잡한 환경에서도 이 동기화가 완벽하게 유지될지는 실무 프로덕션 환경에서 스트레스 테스트가 필요합니다.
💡 최종 평가 (Verdict) “오픈소스 비디오 AI 생태계에도 본격적인 DPO 시대가 열렸습니다. 당장 클론받아서 로컬에서 돌려보세요!” 단순히 신기한 장난감을 넘어, 인간의 선호도를 맞추기 위해 AV-DPO를 적용하고 모달리티 간의 싱크를 아키텍처 레벨에서 풀었다는 점이 가장 큰 수확입니다. 멀티모달 AI 엔지니어나 크리에이티브 테크 스타트업 창업자라면, 이들의 코드와 데이터셋 파이프라인은 반드시 뜯어봐야 할 훌륭한 교과서입니다.
