[2026-03-23] LLM식 순차 디코딩은 틀렸다? OCR을 디퓨전으로 병렬 처리하는 MinerU-Diffusion 해부

[Metadata]
- Paper: MinerU-Diffusion: Rethinking Document OCR as Inverse Rendering via Diffusion Decoding
- Date: 2026. 03
- Category: Document AI, OCR, Diffusion Models
최근 쏟아지는 Vision-Language Model(VLM) 기반의 문서 파싱 도구들을 프로덕션에 올려본 분들이라면 다들 비슷한 고통을 겪고 계실 겁니다. 수십 페이지짜리 논문이나 빽빽한 재무제표 PDF를 집어넣으면, 모델이 토큰을 하나하나 뱉어낼 때까지 세월아 네월아 기다려야 하죠.
가장 빡치는 건 에러 전파(Error Propagation) 문제입니다. 테이블의 두 번째 열(Column)에서 모델이 헛소리(Hallucination)를 시작하면, 그 뒤에 이어지는 3~10열 데이터는 완전히 쓰레기 값이 되어버리거든요. 왜 이런 일이 발생할까요? 우리가 흔히 쓰는 모델들이 모조리 ‘이전 토큰을 기반으로 다음 토큰을 예측하는’ Autoregressive(AR) 좌우 순차 디코딩을 사용하기 때문입니다.
잠깐, 여기서 근본적인 의문이 들죠. 애초에 완성된 문서를 읽고 추출하는 OCR 작업이, 왜 소설 쓰듯이 왼쪽에서 오른쪽으로 순차적으로 이루어져야 할까요? 문서는 이미 그곳에 완성된 형태로 존재하는데 말이죠. 오늘 파헤쳐볼 MinerU-Diffusion은 바로 이 지점을 파고듭니다. 텍스트 생성이 아니라, 2D 시각 정보를 1D로 복원하는 ‘역렌더링(Inverse Rendering)’ 관점으로 패러다임을 완전히 뒤집어버렸거든요.
TL;DR: 기존 VLM의 느려터진 좌우(Left-to-Right) 순차 디코딩을 버리고, 디퓨전 모델의 병렬 디노이징을 도입해 문서 파싱 속도를 3.2배 끌어올리면서도 환각(Hallucination) 연쇄 반응을 끊어낸 OCR 프레임워크.
⚙️ 2D 문서를 1D 토큰으로 찍어내는 병렬 연성진 해부
이 페이퍼의 핵심은 텍스트 생성에 디퓨전을 도입했다는 겁니다. 이미지 생성에 쓰이던 그 디퓨전 맞습니다. 노이즈가 낀 상태에서 점진적으로 토큰의 윤곽을 잡아가며 한 방에 병렬로 텍스트를 확정 짓는 방식이죠.
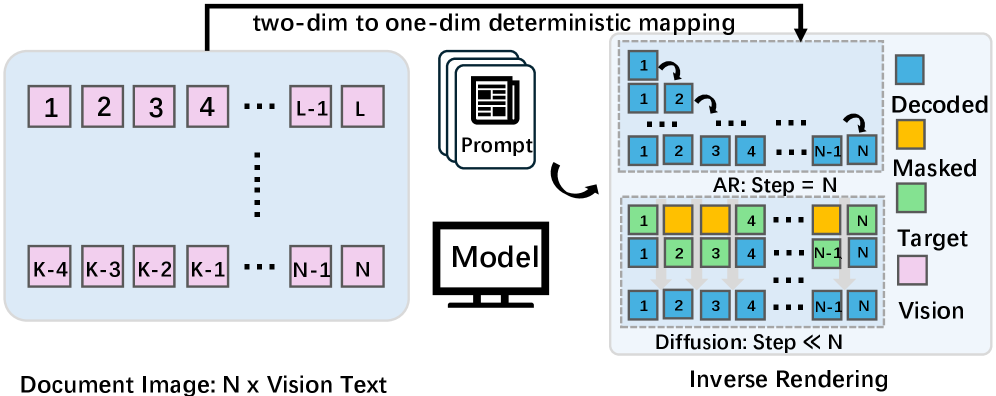
- [그림 설명] 왼쪽이 기존 AR, 오른쪽이 디퓨전 방식입니다. AR이 토큰을 꼬리에 꼬리를 물며 낳는 동안, 디퓨전은 전체 시퀀스를 한 번에 잡고 병렬로 정제해 나가는 걸 볼 수 있습니다.*
아키텍처가 어떻게 굴러가는지 내부 데이터 흐름을 뜯어볼까요?
🔹 시각적 조건부 병렬 디노이징 (Visual Conditioned Parallel Denoising): 모델은 텍스트를 처음부터 끝까지 순서대로 찍어내는 게 아닙니다. 초기에는 모든 텍스트 영역이 ‘[MASK]’ 토큰으로 채워진 시퀀스로 시작합니다. 여기에 원본 문서 이미지의 비주얼 피처를 조건(Condition)으로 주입하죠. 그러면 모델이 문서 전체를 스캔하면서 확신이 드는 쉬운 토큰들부터 먼저 확정(Black Token) 지어버립니다.
🔹 블록 단위 어텐션 마스킹 (Block-wise Attention): 모든 토큰이 서로를 쳐다보면 메모리가 터지겠죠? 그래서 문서를 여러 블록으로 나눕니다. 블록 내부에서는 양방향(Bidirectional)으로 텍스트 컨텍스트를 파악하고, 이전 블록에 대해서만 인과적(Causal)으로 참조합니다.
백문이 불여일견, 이 녀석들의 병렬 디코딩이 코드로 구현된다면 대략 이런 느낌일 겁니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# MinerU-Diffusion의 병렬 디코딩 추론 흐름 (Pseudo-code)
def diffusion_decode(image_features, seq_length, confidence_threshold=0.9):
# 1. 전체 시퀀스를 MASK 토큰으로 초기화
tokens = torch.full((1, seq_length), MASK_TOKEN_ID)
mask_status = torch.ones((1, seq_length), dtype=torch.bool) # True면 아직 마스킹됨
for step in range(MAX_DIFFUSION_STEPS):
if not mask_status.any():
break # 모든 토큰 확정 완료
# 시각 정보와 현재 토큰 상태를 바탕으로 로짓 예측 (병렬 처리)
logits = model.forward_parallel(tokens, image_features)
probs = F.softmax(logits, dim=-1)
max_probs, predicted_tokens = probs.max(dim=-1)
# 2. 신뢰도가 임계치를 넘는 토큰만 병렬로 확정 (Confidence Thresholding)
confident_mask = (max_probs > confidence_threshold) & mask_status
# 3. 확정된 토큰 업데이트 및 마스크 해제
tokens[confident_mask] = predicted_tokens[confident_mask]
mask_status[confident_mask] = False
# 동적 임계치 조정 (Curriculum Learning)
confidence_threshold = decay_threshold(confidence_threshold, step)
return tokens
루프를 돌 때마다 확신도(confidence_threshold)가 높은 토큰들부터 무더기로 마스크를 벗겨버립니다. 순서대로 읽는 게 아니라 눈에 띄는 제목, 굵은 글씨, 명확한 숫자부터 먼저 채워 넣고 남은 빈칸을 추론하는 방식이죠.
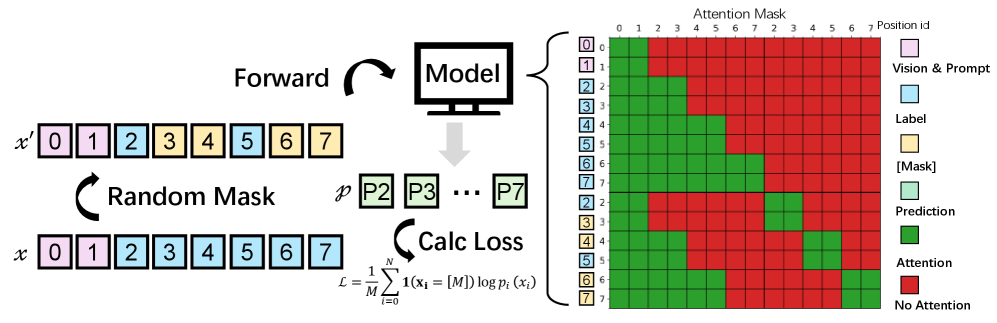
- [그림 설명] 블록 어텐션 구조입니다. 한 블록 내에서는 앞뒤 문맥을 동시에 파악(양방향)하므로 테이블 내 데이터 정렬이나 수식 구조 파악에 압도적으로 유리합니다.*
⚔️ 기존 스택 vs 새로운 패러다임: 진짜 갈아탈 가치가 있나?
솔직히 이런 새로운 아키텍처 논문을 볼 때 우리가 제일 궁금한 건 하나죠. “그래서 지금 내 인프라에 돌아가는 vLLM + LLaMA 구조를 들어내고 바꿀 만한 스펙인가?” 냉정하게 비교해봅시다.
| 비교 지표 | 기존 VLM OCR (AR 방식) | MinerU-Diffusion | 프로덕션 관점의 의미 |
|---|---|---|---|
| 디코딩 시간 복잡도 | $O(N)$ (토큰 수에 비례) | $O(T)$ (디퓨전 스텝 수, $T \ll N$) | GPU 점유 시간이 획기적으로 줄어들어 처리량(TPS) 극대화 |
| 에러 전파력 | 치명적 (앞에서 틀리면 뒤에도 망함) | 독립적 (병렬 추론으로 연쇄 오류 차단) | 재무제표나 복잡한 수식 파싱 시 데이터 신뢰도 급상승 |
| 의존성 (Priors) | 언어 모델의 편향에 강하게 의존 | 시각적 근거(Visual Grounding) 에 집중 | Semantic Shuffle(랜덤 텍스트 배열)에서도 성능 방어 압도적 |
| 메모리 (VRAM) | 막대한 KV Cache 누적 | KV Cache 부담 감소, 단 Attention 연산 피크 존재 | 컨텍스트 윈도우가 긴 대형 문서 처리 시 OOM 방어에 유리 |
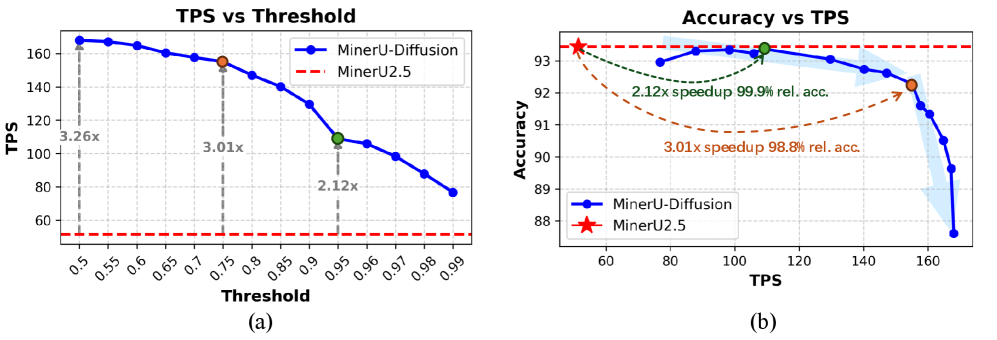
- [그림 설명] 확신도 임계치(Threshold) 조절에 따른 속도 향상. 노란색 토큰(Masked)에서 점진적으로 검은색(Confirmed)으로 수렴하는 과정을 보면, 구조적 일관성을 유지하면서도 AR 대비 3.2배 빠릅니다.*
가장 주목할 점은 속도입니다. 단순한 텍스트 덩어리가 아니라 표와 수식이 난무하는 논문 단위의 문서를 파싱할 때 3.2배의 디코딩 속도 향상은 인프라 비용과 직결됩니다. AWS g5.2xlarge를 하루 종일 띄워놓고 돌려야 했던 배치 작업이 퇴근 전에 끝난다는 뜻이니까요.
🚀 내일 당장 프로덕션에 도입한다면?
이 녀석을 실제 파이프라인에 꽂아본다면 어떤 시나리오가 가장 맛있을까요?
1. 대규모 금융 데이터 기반 RAG 전처리 파이프라인 수백 페이지짜리 기업 사업보고서나 분기 실적 발표 자료(PDF)를 파싱할 때 최고입니다. 기존 AR 모델은 테이블의 특정 셀 값을 잘못 읽으면 그 뒤의 행(Row) 데이터를 통째로 밀려서 파싱하는 대참사가 자주 일어납니다. 반면, MinerU-Diffusion은 2D 비주얼 힌트를 통해 테이블 구조를 먼저 틀어잡고 병렬로 빈칸을 채우기 때문에 구조적 붕괴가 발생하지 않습니다.
2. 수학/물리학 논문의 마크다운(Markdown) 자동 변환 수식($LaTeX$)이 빼곡한 문서는 AR 모델에게 쥐약입니다. 수식 기호 하나만 삐끗해도 전체 렌더링이 깨지거든요. 디퓨전 기반의 블록 어텐션은 양방향 문맥을 참고하여 수식의 열림/닫힘 괄호 짝을 훨씬 안정적으로 맞춰냅니다.
⚠️ 하지만 주의할 병목(Bottleneck)도 명확합니다. 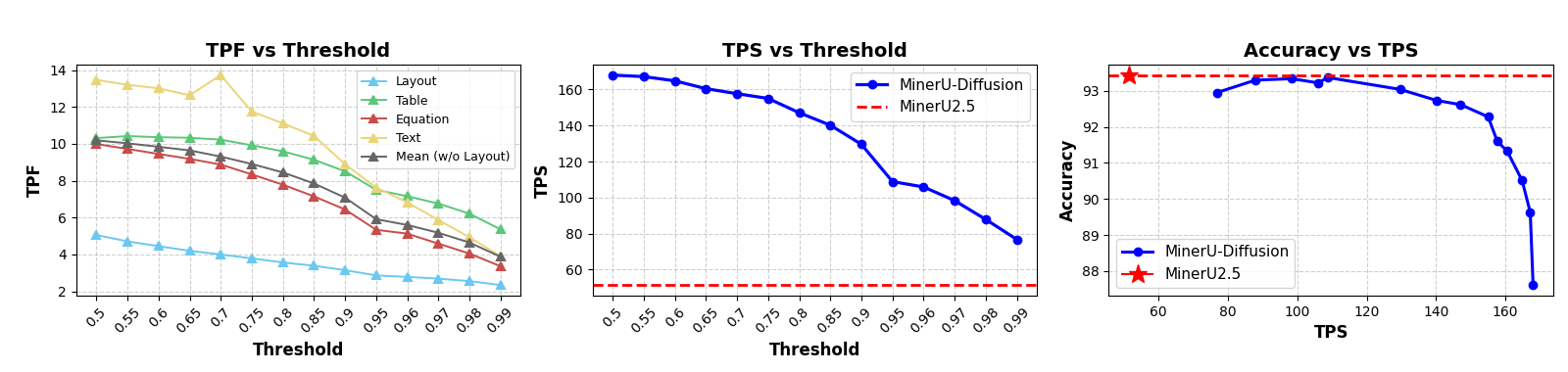
- [그림 설명] 임계치(Threshold)에 따른 Throughput(TPS)과 정확도 변화 곡선. 임계치가 낮아지면 속도는 미친 듯이 오르지만 정확도가 급감하는 교차점이 존재합니다.*
디퓨전 모델 특성상 하이퍼파라미터인 Threshold 세팅이 전부입니다. 문서의 도메인(일반 텍스트 위주인지, 테이블 위주인지)에 따라 최적의 임계치와 디퓨전 스텝 수를 튜닝해야 합니다. 만약 다양한 포맷의 문서가 마구잡이로 들어오는 환경이라면, 이 임계치를 동적으로 조절하는 로직 없이는 퀄리티 컨트롤이 꽤 까다로울 수 있습니다.
🧐 Tech Lead’s Honest Verdict
장점 (Pros):
- 개념의 승리: OCR을 시퀀스 모델링이 아닌 2D->1D 역렌더링으로 해석한 시각 자체가 훌륭합니다.
- 속도와 비용: 속도 3배 향상? 대규모 문서 데이터셋 구축 프로젝트에서는 이것 하나만으로도 도입 명분이 충분합니다.
- 환각 억제력: 언어적 꼼수(Language Priors)가 아니라 눈에 보이는 시각 정보(Visual)에 집중하므로 데이터 추출의 신뢰도가 높습니다.
단점 (Cons):
- 여전히 복잡한 튜닝: AR 모델은 빔서치(Beam Search)나 Temperature 정도만 만지면 되지만, 이건 블록 사이즈, 디퓨전 스텝, 신뢰도 임계치 등 파이프라인 단에서 튜닝할 변수가 많습니다.
- 연산 스파이크: 순차적으로 연산량을 분산하는 AR과 달리, 한 스텝에서 전체 토큰의 어텐션을 계산할 때 일시적인 VRAM 스파이크가 발생할 수 있습니다.
🔥 최종 판정 (Final Verdict): [내부 R&D 데이터 구축용으로 당장 클론해볼 것] 당장 사용자 엔드포인트에 꽂기에는 튜닝의 여지가 좀 남아있지만, 사내에 쌓여있는 수만 장의 PDF를 Markdown이나 JSON으로 변환해 RAG용 벡터 DB에 밀어 넣어야 하는 팀이라면 당장 테스트해 볼 가치가 차고 넘칩니다. LLM이 모든 걸 해결할 거란 환상에서 벗어나, Task의 본질(역렌더링)에 집중한 아키텍처의 아름다움을 맛보시길 바랍니다.
Additional Figures
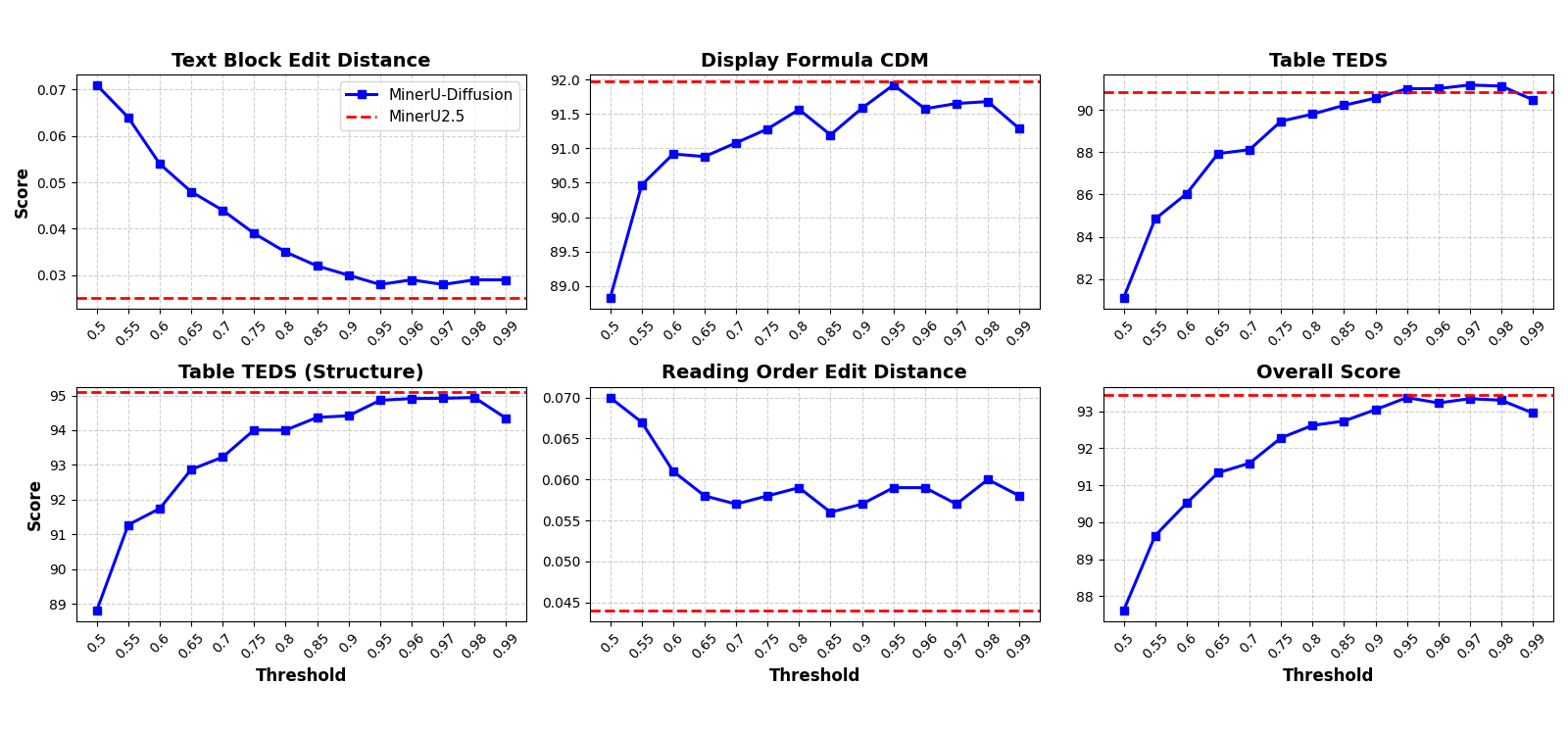 Figure 5:Visualizing the accuracy-throughput trade-off of different models across different OCR tasks under thew/ GT Layoutsetting.
Figure 5:Visualizing the accuracy-throughput trade-off of different models across different OCR tasks under thew/ GT Layoutsetting.
