[2026-03-19] 📸 사진 한 장으로 관절 꺾이는 3D 에셋을 뽑는다고? MonoArt의 미친 추론 파이프라인 파헤치기

[Metadata]
- Paper: MonoArt: Progressive Structural Reasoning for Monocular Articulated 3D Reconstruction
- Arxiv ID: 2603.19231
- Category: 3D Vision / Robotics
단일 이미지에서 관절형(Articulated) 3D 객체를 뽑아내는 건 3D 비전 씬에서 항상 끔찍한 두통거리였습니다. 단순히 겉모습을 복원하는 걸 넘어, ‘이 노트북 힌지가 어디서 어떻게 접히는지’, ‘이 서랍장이 얼만큼 튀어나오는지’를 정적 이미지 한 장으로 유추해야 하니까요.
솔직히 기존 SOTA 모델들이 이 문제를 푸는 방식은 너무 무거웠습니다. 멀티뷰(Multi-view) 이미지를 요구하거나, 아예 보조 비디오를 먼저 생성한 다음 거기서 움직임을 역추적(Tracking)하는 식이었죠. 컴퓨팅 자원 낭비의 끝판왕이자 프로덕션 레벨에서는 타임아웃 나기 딱 좋은 구조입니다. 기하학적 형태(Geometry)와 모션(Motion) 단서가 심하게 꼬여있기 때문에, 이미지에서 관절 파라미터를 다이렉트로 뽑아내는 건 Loss 값이 미쳐 날뛰는 지름길이거든요.
그런데 이번에 나온 MonoArt는 다릅니다. 이들은 무식한 비디오 생성이나 다중 뷰 꼼수 없이, 점진적 구조 추론(Progressive Structural Reasoning)이라는 정공법으로 이 엉킨 실타래를 풀어냈습니다.
TL;DR: MonoArt는 단일 이미지에서 형태, 파츠 구조, 관절 모션 파라미터를 한 번의 포워드 패스로 점진적 추론하는 단일 프레임워크입니다. 비디오 생성 모델 같은 무거운 의존성 없이, Dual-Query 기반의 모션 디코더로 빠르고 해석 가능한 3D 관절(Kinematic) 트리를 뱉어냅니다.
⚙️ 픽셀을 쪼개고 관절을 심는 ‘점진적 추론’ 파이프라인 해부
이 녀석의 핵심은 “한 번에 모든 걸 맞추려 하지 않는다”는 겁니다. 이미지 피처에서 곧바로 힌지 축을 회귀(Regression)하려 들면 모델이 수렴하지 않으니, 파이프라인을 4개의 논리적인 스텝으로 쪼갰습니다.
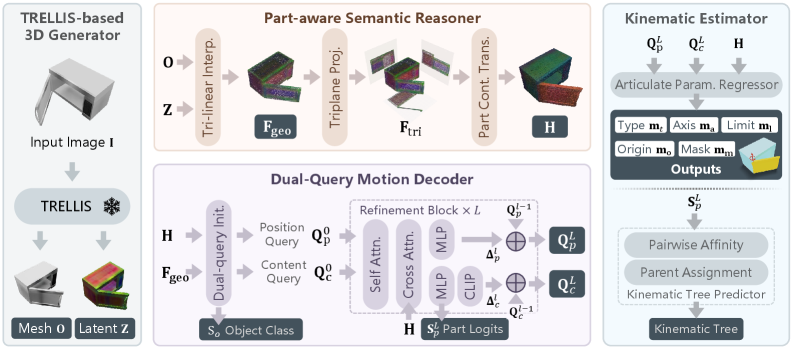
- [그림 설명] MonoArt의 전체 파이프라인. TRELLIS 3D 생성기부터 시작해, 시맨틱 추론, Dual-Query 모션 디코더, 그리고 최종 관절 파라미터 예측까지 매끄럽게 이어지는 점진적 구조를 보여줍니다.
🔹 스텝 1: TRELLIS-based 3D Generator 먼저 입력 이미지를 받아 표준 형태(Canonical Shape)의 3D 볼륨으로 만듭니다. 여기서 트라이플레인(Tri-plane) 기반의 피처를 뽑아냅니다. 아직 관절은 모릅니다. 그냥 “이게 어떻게 생겼다”만 아는 단계죠.
🔹 스텝 2: Part-Aware Semantic Reasoner 이제 이 3D 덩어리를 의미 있는 파츠(Part)로 나눕니다. “이건 모니터, 이건 키보드 하판” 식으로 쪼개서 파츠 전용 트라이플레인 임베딩을 유도합니다.
🔹 스텝 3: Dual-Query Motion Decoder (여기가 핵심입니다) 단순한 트랜스포머 디코더가 아닙니다. 두 가지 쿼리가 핑퐁을 칩니다.
- Geometry Query: 파츠의 물리적 형태와 위치를 추적합니다.
- Kinematic Query: 파츠 간의 움직임 관계를 추적합니다. 이 둘을 분리해서 교차 어텐션(Cross-Attention)을 먹이니까, 형태와 모션이 엉켜서 발생하던 불안정성이 싹 사라집니다.
🔹 스텝 4: Kinematic Estimator 마지막으로 모션 임베딩을 받아 명시적인 파라미터를 뽑아냅니다. 모션 타입(Revolute/Prismatic), 원점(Origin), 회전 축(Axis), 가동 범위(Limits)를 예측하고 최종적으로 Kinematic Tree를 구성합니다.
이 과정을 코드로 상상해볼까요? 백엔드에 붙인다면 대략 이런 느낌의 파이프라인이 될 겁니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
import torch
import torch.nn as nn
class MonoArtPipeline(nn.Module):
def forward(self, image):
# 1. 단일 이미지에서 기하학적 뼈대와 Tri-plane 피처 추출
canonical_shape, triplane_feats = self.trellis_gen(image)
# 2. 파츠별 시맨틱 임베딩으로 분리
part_embeddings = self.semantic_reasoner(triplane_feats)
# 3. Dual-Query로 얽힌 형태와 모션을 분리하여 추론
# motion_embeds는 각 파츠가 '어떻게 움직여야 하는지'에 대한 컨텍스트를 가짐
motion_embeds = self.dual_query_decoder(part_embeddings)
# 4. 물리 시뮬레이터(IsaacSim 등)에 던져넣을 수 있는 파라미터와 트리 추출
# params: {'type': 'revolute', 'axis': [0, 1, 0], 'limits': [0, 1.57]}
params, kinematic_tree = self.kinematic_estimator(motion_embeds)
return build_urdf(canonical_shape, params, kinematic_tree)
이 구조의 미친 점은 외부의 모션 템플릿(Motion templates)에 의존하지 않는다는 겁니다. 파츠 간의 상호작용을 모델 자체가 내부적으로 ‘이해’하고 트리를 구성하죠.
⚔️ 기존 SOTA vs MonoArt: 내 인프라 비용을 얼마나 아껴줄까?
이론이 아무리 좋아도 속도가 느리면 프로덕션에선 쓰레기입니다. 기존 방법론들(Articulate-Anything, PhysX-Anything)과 비교해볼까요?

- [그림 설명] (우측 그래프 주목) PartNet-Mobility 벤치마크에서의 추론 시간 대비 F-Score 비교입니다. MonoArt가 압도적으로 좌측 상단(빠르고 정확함)에 위치해 있는 것을 볼 수 있습니다.
| 비교 지표 | Articulate-Anything | PhysX-Anything | MonoArt (New) |
|---|---|---|---|
| 핵심 메커니즘 | 보조 비디오 생성 + 트래킹 | 멀티뷰 확산 모델 + 최적화 | 단일 프레임워크 점진적 추론 |
| 추론 속도(상대적) | 매우 느림 (비디오 생성 병목) | 느림 (멀티뷰 생성 병목) | 매우 빠름 (End-to-End) |
| 추가 의존성 | Video Diffusion Model | Multi-view Generator | 없음 |
| 아웃풋 형태 | 불안정한 모션 필드 | 파이프라인별 조각난 데이터 | 깔끔한 Kinematic Tree (URDF 직결) |
표를 보면 답이 나옵니다. Articulate-Anything 같은 모델은 움직임을 알기 위해 비디오를 먼저 만들어야 합니다. 인프라 비용? 말할 것도 없이 박살나죠. 반면 MonoArt는 단일 아키텍처 내에서 피처 변환만으로 관절을 추론합니다. GPU VRAM 점유율과 추론 시간 측면에서 이건 백엔드 개발자들에게 축복이나 다름없습니다.
🚀 내일 당장 프로덕션에 도입한다면?
이 파이프라인이 실무에서 어떻게 쓰일 수 있을지 2가지 시나리오로 쪼개보겠습니다.

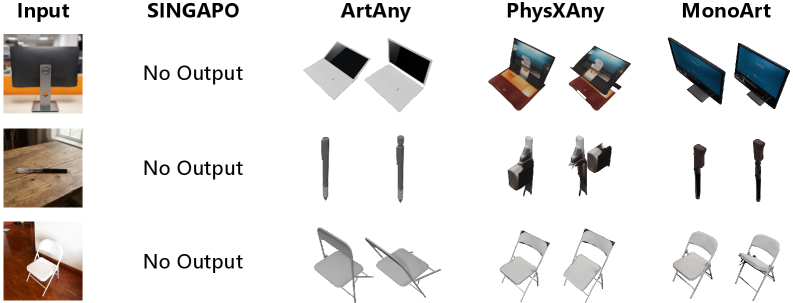
- [그림 설명] PartNet-Mobility 데이터셋에서의 정성적 결과. 기존 SOTA 모델들보다 파츠의 분리와 관절의 축(Axis)이 훨씬 정확하게 떨어지는 것을 볼 수 있습니다.
시나리오 1: 로보틱스 시뮬레이터 (Isaac Sim) 에셋 자동화 가장 폭발적인 유즈케이스입니다. 로봇 팔이 냉장고 문을 여는 학습을 시키려면 수만 개의 관절형 3D 냉장고 에셋이 필요합니다. MonoArt의 결과물은 곧바로 Kinematic Tree(URDF 등)로 매핑 가능하므로, 크롤링한 이미지들을 모델에 밀어넣기만 하면 Isaac Sim에서 상호작용 가능한 물리 에셋이 쏟아져 나옵니다.

- [그림 설명] MonoArt로 생성한 3D 객체를 IsaacSim에 바로 올려 로봇 조작(Manipulation) 시뮬레이션에 활용하는 모습입니다. 파이프라인의 실용성을 증명하는 최고의 샷이죠.
시나리오 2: 이커머스 AR/VR 3D 카탈로그 구축 가구 쇼핑몰에서 사용자가 찍은 서랍장 사진 한 장으로 AR에서 서랍을 열어볼 수 있는 에셋을 만든다고 가정해보죠. 기존 방식이라면 서랍장 뒤쪽이나 안쪽(가려진 부분)의 다중 뷰를 생성하다가 텍스처가 깨지기 일쑤입니다. MonoArt는 ‘In-the-wild’ 이미지에서도 강건한 성능을 보여줍니다.
- [그림 설명] 통제되지 않은 야생(In-the-wild) 이미지에서의 결과. 스마트폰으로 대충 찍은 듯한 사진에서도 서랍의 슬라이딩 모션과 문의 힌지 구조를 훌륭하게 유추해냅니다.
⚠️ 예상되는 병목 (Bottlenecks) 하지만 마법은 없습니다. 단일 이미지의 한계상 심한 가려짐(Severe Occlusion)이 있는 뒷면의 복잡한 관절 구조는 추론에 한계가 있을 수밖에 없습니다. 또한 TRELLIS 백본이 무겁기 때문에, 대규모 배치를 처리할 때 VRAM OOM(Out of Memory)을 피하려면 Gradient Checkpointing이나 양자화(Quantization) 같은 최적화 튜닝이 필수적일 겁니다.
🧐 Tech Lead’s Honest Verdict
👍 Pros (진짜 좋은 점)
- 미친 속도와 효율성: 비디오 생성이나 멀티뷰 파이프라인을 걷어낸 것만으로도 이 모델은 프로덕션에 올릴 가치가 있습니다.
- 명시적이고 깔끔한 아웃풋: 딥러닝 블랙박스에서 뭉뚱그려진 모션 필드가 나오는 게 아니라, 정확한 모션 타입, 축, 원점, 한계값이 담긴 Kinematic Tree가 나옵니다. 엔지니어링하기 너무 편하죠.
- Dual-Query 구조의 우수성: 형태와 움직임을 억지로 엮지 않고 분리해서 쿼리하는 어텐션 설계는 아주 우아합니다.
👎 Cons (아쉬운 점)
- 결국 TRELLIS 모델에 종속적입니다. 기하학적 복원이 초기 단계에서 실패하면, 뒤의 파트 추론과 관절 추론은 도미노처럼 무너질 수밖에 없습니다.
- Single-view의 태생적 한계 때문에 ‘보이지 않는 쪽의 조인트’를 완벽히 예측하는 것은 여전히 물리 법칙의 영역을 넘어서는 일입니다. Hallucination이 발생할 여지가 있죠.
🔥 최종 판정: “내부 툴체인 및 시뮬레이터 에셋 파이프라인으로 당장 Clone 할 것” 만약 여러분의 팀이 로보틱스 데이터 합성이나 3D 관절 에셋 자동화에 시간과 돈을 쏟고 있다면, 이 레포지토리는 당장 클론(Clone)해서 테스트해볼 가치가 차고 넘칩니다. 복잡하게 꼬인 파이프라인들을 다 걷어내고 MonoArt 하나로 퉁칠 수 있는 가능성이 열렸으니까요.
