[2026-03-23] 월드 모델 평가는 왜 다 이 모양일까? Omni-WorldBench로 까보는 4D 물리엔진의 민낯

월드 모델 평가는 왜 다 이 모양일까? Omni-WorldBench로 까보는 4D 물리엔진의 민낯
[Metadata]
- Paper ID: 2603.22212
- Title: Omni-WorldBench: Towards a Comprehensive Interaction-Centric Evaluation for World Models
- Date: March 2026 (Updated)
요즘 나오는 비디오 생성 모델들, 툭하면 ‘월드 모델(World Model)’이라고 광고하죠? 근데 막상 프로덕션에 붙여보려고 하면 한숨부터 나옵니다. 공을 벽에 던졌는데 튕겨 나오긴커녕 벽으로 스며들거나, 카메라를 조금만 돌리면 물체 뒤통수가 괴기하게 찌그러지거든요.
기존 벤치마크들은 영상이 ‘얼마나 예쁜가(Visual Fidelity)’나 ‘프롬프트랑 비슷한가’만 따졌습니다. 이건 월드 모델이 아니라 그냥 픽셀 렌더러 평가 아닌가요? 개발자 입장에선 이 모델이 4D 공간의 물리 법칙과 인과율을 진짜 이해하고 있는지, 즉 상호작용(Interaction) 에 어떻게 반응하는지가 핵심인데 말이죠.
Omni-WorldBench는 바로 이 지점을 파고듭니다. 얄팍한 픽셀 장난질과 진짜 4D 물리엔진을 구분하겠다며 칼을 빼든 거죠.
TL;DR 단순 화질 평가를 버리고, MLLM 에이전트를 도입해 비디오 모델의 ‘물리적 인과율’과 ‘상호작용 일관성’을 채점하는 새로운 프레임워크입니다. 아이디어는 훌륭하지만, 평가 파이프라인의 API 비용과 MLLM 환각 문제는 단단히 각오해야 합니다.
⚙️ 가짜 물리엔진을 걸러내는 4D 채점기 해부
이 벤치마크의 핵심은 ‘얼마나 자연스럽게 상호작용하는가’를 시스템적으로 뜯어보는 겁니다. 크게 두 가지 축으로 돌아갑니다. 첫째는 다양한 상호작용 시나리오를 쑤셔넣은 Omni-WorldSuite이고, 둘째는 이걸 평가하는 Omni-Metrics죠.
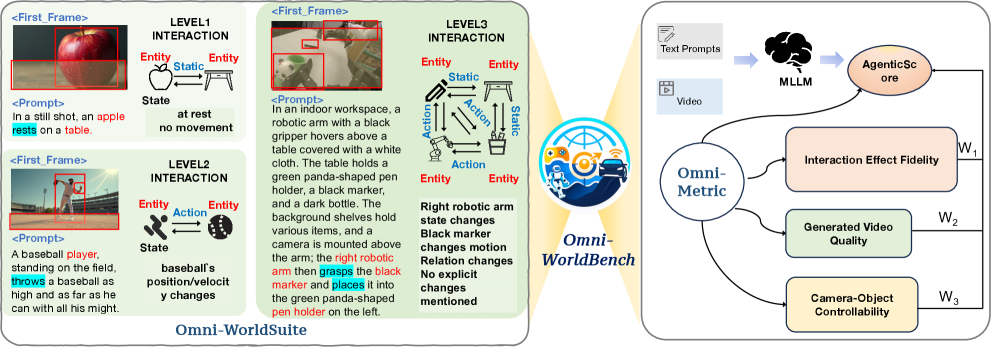
- [그림 설명] Omni-WorldBench의 전체 파이프라인. 왼쪽은 3가지 상호작용 레벨을 정의한 Suite, 오른쪽은 MLLM 에이전트를 통해 인과율과 제어력을 종합 평가하는 Metrics 구조를 보여줍니다.
가장 흥미로운 건 Omni-Metrics의 구조입니다. 단순한 픽셀 비교 스크립트가 아닙니다. 이 녀석들은 시공간적 인과 일관성(Spatiotemporal Causal Coherence)을 측정하기 위해 MLLM을 에이전트로 씁니다. 상태 변화의 궤적을 추적하고 원인과 결과를 분석하죠.
내부적으로 이 평가가 어떻게 돌아갈지, Omni-Metrics의 MLLM 프롬프팅 페이로드를 예상 코드로 구현해봤습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
import json
import requests
def evaluate_world_model_interaction(video_frames, prompt, initial_state):
"""
Omni-Metrics의 AgenticScore를 도출하는 핵심 로직 추론
"""
payload = {
"task": "evaluate_interaction_causality",
"inputs": {
"initial_condition": initial_state, # 예: "유리잔이 책상 끝에 있음"
"action_prompt": prompt, # 예: "로봇 팔이 유리잔을 민다"
"video_sequence": video_frames # 16프레임 텐서 데이터
},
"evaluation_criteria": [
"effect_fidelity", # 로봇 팔이 닿았을 때 물리적 반응이 즉각적인가?
"causal_coherence", # 민 방향대로 떨어지고, 깨지는가?
"camera_controllability" # 카메라 시점이 변해도 객체 위치가 유지되는가?
]
}
# MLLM(GPT-4o 등)에게 비디오 프레임과 기준을 던져주고 JSON 형태의 채점 결과를 받음
response = requests.post("https://api.mllm.endpoint/v1/score", json=payload)
# AgenticScore 파싱
score_data = response.json()
return score_data['agentic_score'], score_data['failure_reasons']
# 결국 월드 모델의 성능은 '얼마나 현실의 물리법칙을 잘 흉내내는가'로 귀결됩니다.
이 코드를 보면 알 수 있듯, 평가 로직 자체가 상당히 무겁습니다. 모델이 생성한 비디오를 단순히 해상도나 FID(Fréchet Inception Distance)로 퉁치는 게 아니라, 프레임 사이의 인과관계를 언어 모델이 직접 추론해야 하거든요.

- [그림 설명] 실내, 자율주행, 로보틱스 등 다양한 도메인에서 첫 프레임과 프롬프트를 결합해 상호작용을 유도하는 예시들입니다. 저 빨간 박스 안의 객체들이 물리적으로 어떻게 반응하는지가 채점의 핵심이죠.
⚔️ 기존 스택 vs 새로운 패러다임: 진짜 갈아탈 가치가 있나?
그럼 기존의 비디오 벤치마크(VBench, FVD 등)와 비교했을 때 이게 개발자에게 어떤 메리트를 줄까요? 지표부터 비교해봅시다.
| Feature / Benchmark | Standard VBench | Static 3D Metrics | Omni-WorldBench (New) |
|---|---|---|---|
| Core Focus | Visual Quality, Alignment | 3D Structural Accuracy | 4D Interaction & Causality |
| Evaluation Method | CLIP Score, FVD | PSNR, SSIM, LPIPS | AgenticScore (MLLM based) |
| Temporal Dynamics | 제한적 (단순 모션 스무딩) | 거의 없음 (정적 뷰 합성) | 매우 높음 (상태 전이 추적) |
| Dev Cost (Eval) | 낮음 (로컬 연산 가능) | 중간 (렌더링 오버헤드) | 매우 높음 (MLLM API 호출 폭탄) |
| Production Value | 마케팅용 데모 검증 | 3D 에셋 생성 검증 | 자율주행, 로보틱스 시뮬레이터 검증 |
표를 보면 장단점이 극명합니다. 솔직히 프로덕트가 단순한 ‘텍스트-비디오 생성기(예: 숏폼 자동 생성 서비스)’라면 이 벤치마크는 오버스펙입니다. 굳이 비싼 API 비용을 태워가며 물리법칙을 검증할 필요가 없으니까요.
하지만 여러분이 로봇 팔 제어 시뮬레이터나 자율주행 코너 케이스 생성기를 만들고 있다면 이야기가 다릅니다. 이 영역에선 앞차와 부딪혔을 때 차가 찌그러지지 않고 통과해버리면(Ghosting) 모델 전체가 쓰레기통행이죠. Omni-WorldBench는 이런 치명적인 결함을 배포 전에 잡아낼 수 있는 유일한 대안입니다.

- [그림 설명] 동일한 프롬프트로 여러 모델을 테스트한 결과 비교. 공을 던지는 행위에서 물리적 궤적과 객체의 형태 유지가 모델마다 얼마나 천차만별인지 적나라하게 보여줍니다.
🚀 내일 당장 프로덕션에 도입한다면?
이 논문의 접근법을 실무에 당장 써먹을 수 있는 시나리오 두 가지를 생각해봤습니다.
1. Embodied AI (로보틱스) 파운데이션 모델 검증 파이프라인 사내에서 로봇 조작용 비디오 모델을 파인튜닝 중이라고 가정해보죠. 기존에는 모델이 뱉은 영상을 엔지니어들이 일일이 눈으로 보며 “음, 컵을 제대로 잡았군” 하고 평가해야 했습니다. 이젠 CI/CD 파이프라인에 Omni-Metrics를 태워서, 물체 간 충돌(Collision)이나 형태 변형(Deformation)이 물리법칙에 어긋나면 자동으로 빌드를 멈출 수 있습니다.
2. 게임 엔진용 동적 에셋 생성기 필터링 유저의 프롬프트에 따라 실시간으로 상호작용 가능한 게임 환경을 생성하는 서비스가 있다고 칩시다. 유저가 문을 여는 상호작용을 요청했는데, 모델이 문이 열리는 게 아니라 문이 통째로 녹아내리는 영상을 생성하면 안 되겠죠? MLLM 기반의 인과율 채점을 통해 이런 불량 생성을 서빙 전에 필터링하는 데 활용할 수 있습니다.
🚨 하지만 병목(Bottlenecks)을 주의하세요! 가장 큰 문제는 평가 파이프라인의 레이턴시와 비용입니다. 비디오 프레임 단위로 MLLM을 호출해 AgenticScore를 계산해야 하므로, 모델 체크포인트 하나를 전체 Suite로 평가할 때마다 수백 달러의 API 비용과 몇 시간의 대기 시간이 발생할 수 있습니다. 로컬에 경량화된 VLM(예: LLaVA)을 띄워서 비용을 줄이는 아키텍처 최적화가 필수적입니다.
🧐 Tech Lead’s Honest Verdict
👍 Pros: 비디오 생성 모델을 향한 “예쁜 쓰레기”라는 비판을 정확히 타격했습니다. 단순히 픽셀을 예측하는 것을 넘어, 객체의 영속성(Object Permanence)과 물리적 인과관계를 측정하려고 시도한 점은 박수받아 마땅합니다. 데이터셋(Omni-WorldSuite)의 엣지 케이스 분류도 상당히 실무적입니다.
👎 Cons: 평가를 MLLM에 의존한다는 건 양날의 검입니다. MLLM 자체가 환각(Hallucination)을 일으키면 평가 결과 전체가 오염되거든요. 게다가 카메라 모션이나 물리 법칙을 오직 ‘시각적 결과물’로만 역추산하기 때문에, 렌더링 퀄리티가 조금만 떨어져도 점수가 박살 나는 편향성이 존재합니다.
🛠️ Final Verdict: “코어 AI 팀이라면 즉시 클론, 앱 개발자라면 일단 관망” 당신이 자율주행이나 로보틱스, 3D 물리 엔진에 들어갈 모델을 깎고 있다면 이 벤치마크는 내일 당장 파이프라인에 이식해야 합니다. 하지만 단순히 광고 영상이나 숏폼을 만드는 모델을 쓴다면 굳이 이 비싼 채점기를 돌릴 이유는 없습니다. v2에서 평가 경량화가 이루어지길 기대해봅니다.
Additional Figures
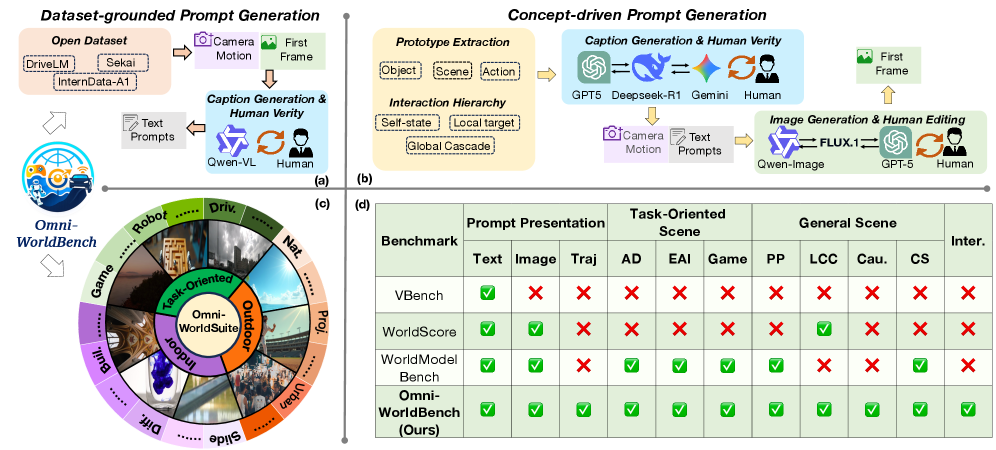 Figure 2:Omni-WorldSuite Construction Pipeline and Analysis.(a)Dataset-grounded prompt generation. Prompts are generated from open-source data using first-frame and camera-motion cues, refined through VLM captioning, and finally verified by human annotators.(b)Concept-driven prompt generation. Prompts are derived from interaction prototypes using LLM/VLM-based generation and human curation, together with generated or edited first frames.(c)Suite taxonomy across indoor scenes, including diffusion (Diff.), sliding, and building-related (Buil.) scenarios; outdoor scenes, including natural, projectile motion (Proj.), and urban scenarios (Urban); and task-oriented settings, including robotics (Robot), autonomous driving (Driv.), and gaming (Game).(d)Coverage comparison by prompt modality and capability axes. Abbr.:Traj(camera trajectory);AD(autonomous driving),EAI(embodied AI);PP(physical principles);LCC(loop-closure consistency);Cau.(causality);CS(common sense);Inter.(Interaction).
Figure 2:Omni-WorldSuite Construction Pipeline and Analysis.(a)Dataset-grounded prompt generation. Prompts are generated from open-source data using first-frame and camera-motion cues, refined through VLM captioning, and finally verified by human annotators.(b)Concept-driven prompt generation. Prompts are derived from interaction prototypes using LLM/VLM-based generation and human curation, together with generated or edited first frames.(c)Suite taxonomy across indoor scenes, including diffusion (Diff.), sliding, and building-related (Buil.) scenarios; outdoor scenes, including natural, projectile motion (Proj.), and urban scenarios (Urban); and task-oriented settings, including robotics (Robot), autonomous driving (Driv.), and gaming (Game).(d)Coverage comparison by prompt modality and capability axes. Abbr.:Traj(camera trajectory);AD(autonomous driving),EAI(embodied AI);PP(physical principles);LCC(loop-closure consistency);Cau.(causality);CS(common sense);Inter.(Interaction).
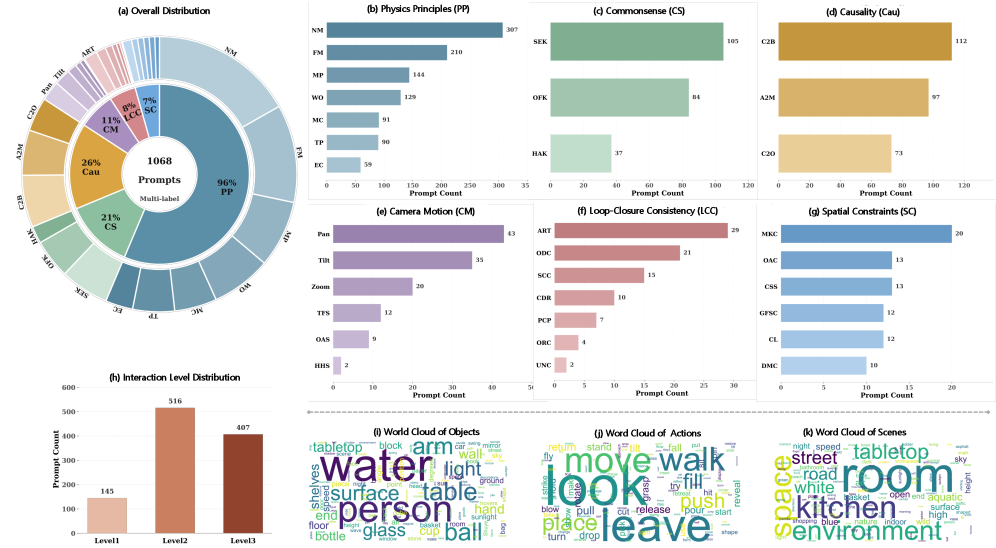 Figure 4:Statistics of Omni-WorldSuite.(a)Overall Distributions;(b–g)Distributions of core principles;(h)prompt counts by interaction level;(i–k)word clouds of objects, actions, and scenes. NM (Newtonian Mechanics), FM (Fluid Mechanics), MP (Material Properties), WO (Waves and Optics), MC (Momentum and Collision), TP (Thermodynamics and Phase Transition), EC (Energy Conversion and Conservation); SEK (Scene/Event Knowledge), OFK (Object Function Knowledge), HAK (Human Action Knowledge); C2B (Condition-to-Behavior), A2M (Action-to-Motion), C2O (Collision-to-Outcome); TFS (Tracking / Follow Shot), OAS (Orbit / Arc Shot), HHS (Handheld / Shaky); ART (Axial Round-Trip Motion), ODC (Optical / Dynamic Consistency Closure), SCC (Spiral / Composite Closure), CDR (Curved / Diagonal Return Motion), PCP (Planar Closed-Path Motion), ORC (Orbital / Rotational Closure), UNC (Uncategorized); MKC (Mechanical / Kinematic Constraints), CSS (Contact & Support Stability), OAC (Occlusion & Accessibility Constraints), CL (Containment & Leakage), GFSC (Geometric Fit & Size Compatibility), DMC (Deformation & Material Constraints).
Figure 4:Statistics of Omni-WorldSuite.(a)Overall Distributions;(b–g)Distributions of core principles;(h)prompt counts by interaction level;(i–k)word clouds of objects, actions, and scenes. NM (Newtonian Mechanics), FM (Fluid Mechanics), MP (Material Properties), WO (Waves and Optics), MC (Momentum and Collision), TP (Thermodynamics and Phase Transition), EC (Energy Conversion and Conservation); SEK (Scene/Event Knowledge), OFK (Object Function Knowledge), HAK (Human Action Knowledge); C2B (Condition-to-Behavior), A2M (Action-to-Motion), C2O (Collision-to-Outcome); TFS (Tracking / Follow Shot), OAS (Orbit / Arc Shot), HHS (Handheld / Shaky); ART (Axial Round-Trip Motion), ODC (Optical / Dynamic Consistency Closure), SCC (Spiral / Composite Closure), CDR (Curved / Diagonal Return Motion), PCP (Planar Closed-Path Motion), ORC (Orbital / Rotational Closure), UNC (Uncategorized); MKC (Mechanical / Kinematic Constraints), CSS (Contact & Support Stability), OAC (Occlusion & Accessibility Constraints), CL (Containment & Leakage), GFSC (Geometric Fit & Size Compatibility), DMC (Deformation & Material Constraints).
