[2026-02-09] OneVision-Encoder: 코덱 정렬 희소성을 통한 차세대 멀티모달 지능의 패러다임 전환

OneVision-Encoder: 코덱 정렬 희소성(Codec-Aligned Sparsity)을 통한 차세대 멀티모달 지능의 패러다임 전환
1. 핵심 요약 (Executive Summary)
인공지능의 발전 과정에서 ‘효율성’과 ‘성능’은 대개 트레이드오프(Trade-off) 관계로 인식되어 왔습니다. 하지만 최근 공개된 OneVision-Encoder (OV-Encoder) 연구는 이러한 상식을 뒤집는 강력한 가설을 제시합니다. 바로 “인공 일반 지능(AGI)의 본질은 압축 문제이며, 효과적인 압축은 아키텍처가 데이터의 근본적인 구조와 공명할 때 실현된다”는 것입니다.
OneVision-Encoder는 현대 비전 아키텍처가 가진 비효율성, 즉 정적인 배경과 중복된 픽셀 정보에 막대한 연산량을 낭비하는 문제를 해결하기 위해 비디오 코덱(Video Codec)의 원리를 딥러닝 아키텍처에 직접 통합했습니다. 이 모델은 비디오 신호 내의 신호 엔트로피(Signal Entropy)가 높은 지역(전체의 약 3.1%~25%)에만 연산 자원을 집중하는 Codec Patchification 기법을 도입했습니다. 그 결과, Qwen3-ViT 및 SigLIP2와 같은 최신 모델 대비 훨씬 적은 토큰과 데이터로도 16개 이상의 벤치마크에서 압도적인 성능 향상을 기록했습니다. 특히 비디오 이해 과제에서는 평균 4.1%의 성능 향상을 달성하며, ‘희소성(Sparsity)’이 단순한 최적화 도구가 아닌 지능의 기초 원리임을 입증했습니다.
2. 연구 배경 및 문제 정의 (Introduction & Problem Statement)
현대 컴퓨터 비전의 주류인 Vision Transformer(ViT) 계열 모델들은 입력 이미지를 격자(Grid) 형태로 균일하게 분할하여 처리합니다. 이는 구현의 단순함과 확장성 측면에서 큰 이점을 가졌으나, 정보 이론(Information Theory)적 관점에서는 매우 비효율적인 방식입니다.
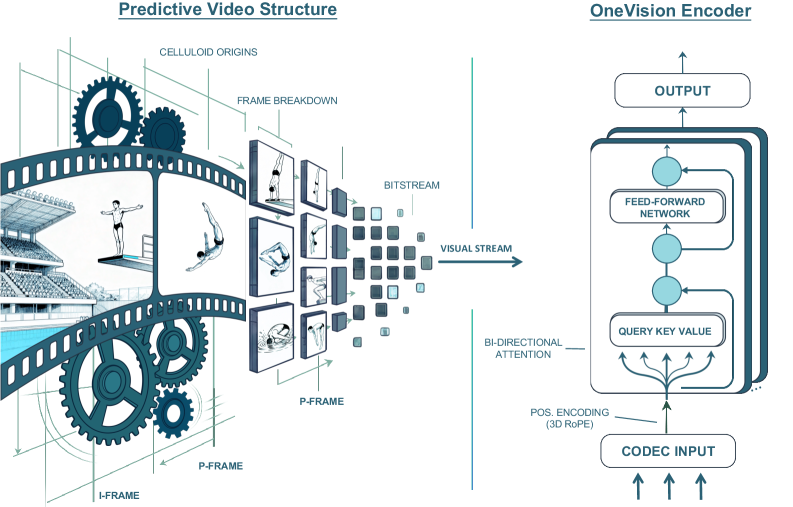 그림 1: 코덱 정렬 예측 압축으로서의 시각 지능. 비디오의 중복성을 제거하고 희소한 정보(움직임, 잔차)에 집중하는 것이 지능형 모델링의 핵심임을 보여줍니다.
그림 1: 코덱 정렬 예측 압축으로서의 시각 지능. 비디오의 중복성을 제거하고 희소한 정보(움직임, 잔차)에 집중하는 것이 지능형 모델링의 핵심임을 보여줍니다.
기존 모델의 한계: 정보의 중복성과 연산 낭비
비디오 데이터의 90% 이상은 이전 프레임과 중복되는 배경이거나 예측 가능한 정보입니다. 하지만 현재의 비전 모델들은 모든 프레임의 모든 픽셀을 동일한 가중치로 처리합니다. 이는 다음과 같은 문제를 야기합니다.
- 연산 비용의 폭증: 고해상도 비디오를 처리할 때 토큰 수가 기하급수적으로 증가하여 추론 및 학습 비용이 감당하기 힘든 수준에 이릅니다.
- 신호 대 잡음비(SNR) 저하: 의미 있는 움직임(Surprise/Residuals)보다 정적인 배경 정보가 토큰의 대부분을 차지하여, 모델이 핵심적인 동적 변화를 포착하는 데 방해가 됩니다.
- 장기 의존성 확보의 어려움: 제한된 컨텍스트 윈도우 내에 중복된 정보가 가득 차면서 정작 중요한 시각적 사건들을 길게 추적하기 어려워집니다.
OneVision-Encoder는 이러한 문제를 해결하기 위해 “비전 모델이 왜 비디오 코덱처럼 동작하지 않는가?”라는 근본적인 질문을 던집니다. 비디오 코덱(HEVC 등)은 이미 수십 년 전부터 I-프레임(전체 구조)과 P-프레임(움직임 잔차)을 분리하여 데이터를 압축해 왔습니다. OV-Encoder는 이 메커니즘을 신경망의 패치화(Patchification) 과정에 이식했습니다.
3. 핵심 기술 및 아키텍처 심층 분석 (Core Methodology)
OneVision-Encoder의 혁신은 크게 세 가지 축으로 나뉩니다: Codec Patchification, 3D RoPE (Rotary Positional Embedding), 그리고 Cluster Discrimination Objective입니다.
3.1 Codec Patchification: 엔트로피 기반의 희소 패치 선택
모델은 모든 픽셀을 처리하는 대신, 비디오 코덱의 프레임 구조를 모방합니다.
 그림 5: HEVC에서의 I-프레임 및 P-프레임 분해 시각화. P-프레임은 정적인 배경을 제외한 움직임 잔차만을 보존하여 신호 엔트로피를 극대화합니다.
그림 5: HEVC에서의 I-프레임 및 P-프레임 분해 시각화. P-프레임은 정적인 배경을 제외한 움직임 잔차만을 보존하여 신호 엔트로피를 극대화합니다.
- I-frame (Spatial Anchor): 비디오의 공간적 맥락을 유지하기 위해 고밀도 패치화를 수행합니다.
- P-frame (Motion Residuals): 이전 프레임과의 차이점, 즉 ‘움직임’이 발생한 영역만을 선택적으로 추출합니다. 이를 통해 전체 데이터 중 3%~25%의 유의미한 토큰만을 생성합니다.
이 방식은 단순히 데이터를 줄이는 것이 아니라, 모델이 ‘무엇이 변했는가?’에 집중하게 함으로써 자연스럽게 인과 관계와 운동 역학을 학습하게 만듭니다.
3.2 통합 프레임워크와 3D-RoPE
희소한 토큰 레이아웃은 기존의 절대적 위치 임베딩을 사용할 수 없게 만듭니다. 토큰들이 격자 구조를 벗어나 불규칙하게 배치되기 때문입니다. 이를 해결하기 위해 OV-Encoder는 Unified 3D-RoPE를 도입했습니다.
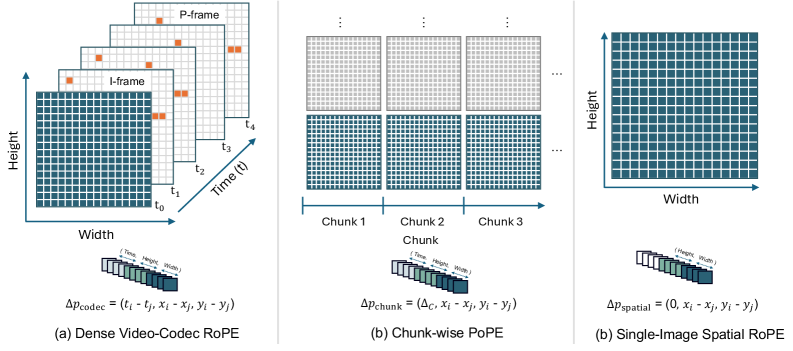 그림 4: Codec Patchification을 위한 3D-RoPE. 시공간적 오프셋을 통합하여 불규칙한 토큰 배치에서도 구조적 일관성을 유지합니다.
그림 4: Codec Patchification을 위한 3D-RoPE. 시공간적 오프셋을 통합하여 불규칙한 토큰 배치에서도 구조적 일관성을 유지합니다.
3D-RoPE는 시간($\Delta t$)과 공간($\Delta x, \Delta y$)의 상대적 거리를 계산하여 어텐션 메커니즘이 희소한 토큰들 사이에서도 물리적인 거리를 인지할 수 있도록 합니다. 이는 비디오뿐만 아니라 단일 이미지, 문서 이미지 등 다양한 입력 형태를 하나의 공통된 좌표계로 통합하는 역할을 합니다.
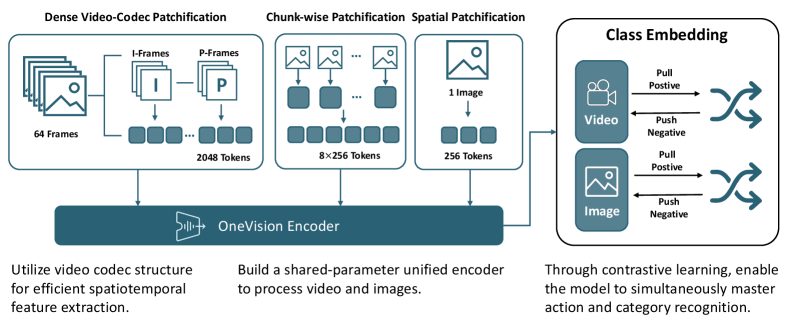 그림 2: OneVision-Encoder 프레임워크 개요. 다양한 패치화 전략이 하나의 공유 인코더를 통해 처리되며, 클러스터 판별 목적 함수를 통해 학습됩니다.
그림 2: OneVision-Encoder 프레임워크 개요. 다양한 패치화 전략이 하나의 공유 인코더를 통해 처리되며, 클러스터 판별 목적 함수를 통해 학습됩니다.
3.3 대규모 클러스터 판별 학습 (Cluster Discrimination)
전형적인 대조 학습(Contrastive Learning)은 배치(Batch) 내의 샘플들을 서로 비교하지만, 이는 임베딩 공간의 구조를 제한적으로 보게 만듭니다. OV-Encoder는 백만 개 이상의 시맨틱 개념을 포함하는 글로벌 클러스터 센터(Global Cluster Centers)를 구축하고, 각 토큰이 어떤 클러스터에 속하는지를 판별하는 Cluster Discrimination Objective를 사용합니다.
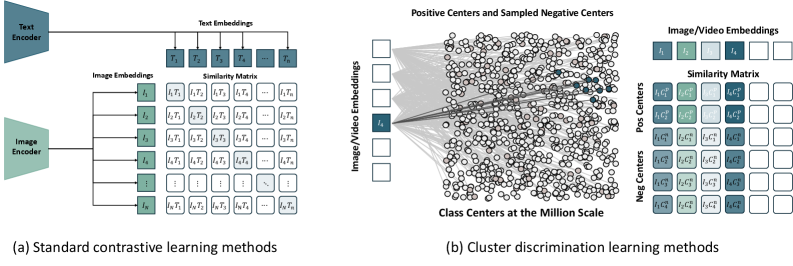 그림 3: 대조 학습과 클러스터 판별의 비교. 글로벌 개념 뱅크를 사용함으로써 훨씬 더 정교하고 구조적으로 분리된 표현력을 얻을 수 있습니다.
그림 3: 대조 학습과 클러스터 판별의 비교. 글로벌 개념 뱅크를 사용함으로써 훨씬 더 정교하고 구조적으로 분리된 표현력을 얻을 수 있습니다.
4. 구현 및 실험 환경 (Implementation Details)
- 데이터셋: 100만 개 이상의 시맨틱 개념을 포함하는 대규모 멀티모달 데이터셋을 사용하여 사전 학습을 진행했습니다.
- 아키텍처: Transformer 기반의 공유 파라미터 인코더를 사용하며, 입력에 따라 패치화 전략을 유연하게 변경합니다 (Dense, Chunk-wise, Sparse).
- 평가 지표: Image understanding (VQAv2, OK-VQA 등), Video understanding (ActivityNet, MSVD 등), Document/OCR 이해도를 포함한 16개 벤치마크.
- 효율성: 기존 고밀도(Dense) 모델 대비 시각 토큰 수를 최대 80%까지 절감하면서도 성능을 유지하거나 향상시켰습니다.
5. 성능 평가 및 비교 (Comparative Analysis)
OneVision-Encoder의 성능 결과는 매우 고무적입니다. 특히 비디오 이해 분야에서의 도약이 두드러집니다.
- 비디오 벤치마크 압승: Qwen3-ViT 대비 평균 4.1%의 정확도 향상을 보였습니다. 이는 P-프레임 잔차 정보를 활용하여 모델이 객체의 움직임과 인과 관계를 더 명확히 파악했음을 시사합니다.
- 토큰 효율성: 동일 성능을 내는 데 필요한 토큰 수가 SigLIP2의 절반 이하 수준입니다. 이는 추론 속도(Throughput)의 비약적인 상승으로 이어집니다.
- 확장성 (Scalability): 데이터 양과 모델 파라미터가 증가함에 따라 성능이 선형적으로 향상되는 ‘Scaling Law’가 희소 모델에서도 그대로 적용됨을 확인했습니다.
Chief Scientist Insight: “이 실험 결과가 시사하는 바는 명확합니다. 비전 모델에서 ‘모든 픽셀을 보는 것’은 학습에 도움이 되기보다 노이즈를 주입하는 것에 가깝습니다. 코덱 기반의 희소성은 정보의 순도를 높이는 필터 역할을 합니다.”
6. 실제 적용 분야 및 글로벌 파급력 (Real-World Application)
OneVision-Encoder의 기술은 단순히 벤치마크 점수를 높이는 데 그치지 않고, 산업 전반에 막대한 영향을 미칠 것입니다.
1) 실시간 지능형 관제 및 보안 (Surveillance)
수천 대의 CCTV 카메라를 동시에 모니터링해야 하는 환경에서 모든 프레임을 딥러닝으로 분석하는 것은 불가능에 가깝습니다. OV-Encoder의 코덱 정렬 희소성을 적용하면, 움직임이 발생한 영역만 인코딩하여 서버 부하를 1/10 수준으로 줄이면서도 이상 행동 탐지 정확도를 높일 수 있습니다.
2) 자율주행 및 모빌리티 (Autonomous Driving)
자율주행 자동차는 초당 수십 프레임의 고해상도 영상을 처리해야 합니다. OV-Encoder를 활용하면 고정된 도로 배경보다는 갑자기 튀어나오는 보행자나 주변 차량의 미세한 움직임(P-frame residuals)에 연산 자원을 집중할 수 있어, 반응 속도와 안전성을 획기적으로 개선할 수 있습니다.
3) 온디바이스 AI (On-device AI)
모바일 기기나 웨어러블 장치에서 비디오 이해 모델을 돌리는 가장 큰 장벽은 배터리와 발열입니다. 토큰 수를 혁신적으로 줄인 OV-Encoder는 스마트폰에서도 실시간 영상 편집, 제스처 인식, AR/VR 객체 추적 등을 가능하게 하는 핵심 엔진이 될 것입니다.
7. 기술적 비평 및 한계점 (Discussion & Critical Critique)
본 연구는 매우 훌륭하지만, 실제 도입을 위해 고려해야 할 몇 가지 비판적 지점이 있습니다.
- 외부 코덱 의존성: 이 모델의 성능은 비디오 코덱이 얼마나 효율적으로 잔차를 계산하느냐에 의존합니다. 만약 입력 비디오의 인코딩 품질이 낮거나 노이즈가 심할 경우, 잘못된 희소 패치가 선택되어 모델 성능이 급격히 저하될 위험(Garbage In, Garbage Out)이 있습니다.
- 전처리 오버헤드: 딥러닝 연산량은 줄어들지만, 코덱 수준의 패치 분리 및 3D-RoPE 좌표 계산 등 CPU/GPU 기반의 전처리 과정이 복잡해질 수 있습니다. 전체 파이프라인의 Latency 관점에서 진정한 이득이 얼마나 되는지 추가 검증이 필요합니다.
- 범용성 문제: 텍스트나 정적 이미지가 주된 도메인에서는 이 ‘코덱 기반’ 접근법이 큰 효과를 거두기 어렵습니다. 물론 연구팀은 단일 이미지에 대해서도 처리가 가능하도록 설계했지만, 본질적인 이점은 ‘시간적 변화’가 있는 데이터에서 나옵니다.
8. 결론 (Conclusion)
OneVision-Encoder는 비전 인코더 설계의 오랜 관습이었던 ‘고밀도 균일 격자’ 방식에 정면으로 도전했습니다. 비디오 코덱의 원리를 빌려와 신호 엔트로피가 높은 곳에 지능을 집중시킨 이 방식은, AGI로 가는 길이 단순히 연산량을 늘리는 것이 아니라 데이터의 본질에 맞게 구조를 최적화하는 것에 있음을 다시 한번 상기시켜 줍니다.
효율적인 연산과 뛰어난 정확도를 동시에 달성한 OV-Encoder는 향후 비전 언어 모델(VLM)의 표준 백본으로 자리 잡을 가능성이 큽니다. 시각적 중복성을 제거하고 본질적인 ‘변화’를 읽어내는 능력이 바로 우리가 기대하는 차세대 AI의 모습이기 때문입니다.
