[2026-03-26] 비디오 생성 모델의 '금붕어 기억력'을 치료하다: HyDRA 아키텍처와 하이브리드 메모리 해부

Link: https://arxiv.org/abs/2603.25716 Authors: … Date: March 2026
최근 쏟아지는 비디오 생성 모델들, 겉보기엔 진짜 화려하죠. 하지만 10초 이상의 롱테이크 씬을 생성해보신 분들이라면 다들 공감하실 겁니다. 자동차가 프레임 밖으로 넘어갔다가 카메라가 다시 돌아오면 어떻게 되던가요? 자동차가 증발해 있거나, 형체를 알아볼 수 없는 슬라임 덩어리로 변해 있죠.
기존 비디오 월드 모델들은 환경을 그저 3D 캔버스에 발라놓은 ‘정적(Static) 텍스처’로만 취급하거든요. 동적인 객체가 시야 밖(Out of Sight)으로 사라지면, 모델의 어텐션 윈도우 밖으로 밀려나면서 그대로 뇌리에서도 잊혀(Out of Mind) 버리는 겁니다. 금붕어도 아니고 말이죠.
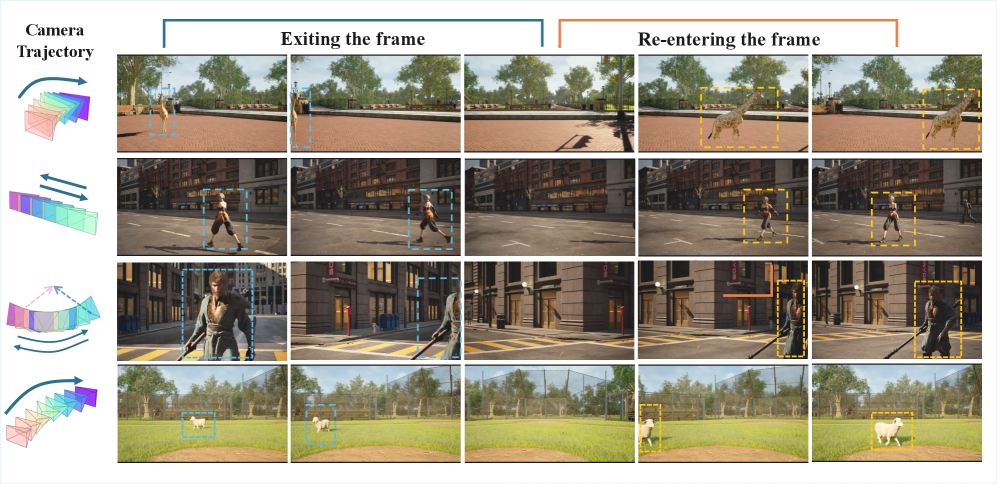 Figure 2: 객체가 시야에서 사라졌다가 다시 등장하는 (Exit-entry) 전형적인 시나리오. 기존 모델들은 이 짧은 블라인드 스팟을 견디지 못하고 객체의 형상과 모션을 붕괴시킵니다.
Figure 2: 객체가 시야에서 사라졌다가 다시 등장하는 (Exit-entry) 전형적인 시나리오. 기존 모델들은 이 짧은 블라인드 스팟을 견디지 못하고 객체의 형상과 모션을 붕괴시킵니다.
이 지긋지긋한 ‘오브젝트 영속성(Object Permanence)’ 문제를 풀기 위해 등장한 녀석이 바로 오늘 뜯어볼 HyDRA(Hybrid Memory) 아키텍처입니다.
TL;DR HyDRA는 배경과 동적 객체의 메모리를 분리하고, 무식하게 프레임을 전부 캐싱하는 대신 메모리를 토큰화(Tokenization)하여 Spatiotemporal Top-k 리트리벌을 수행합니다. 덕분에 VRAM을 터뜨리지 않으면서도 화면 밖으로 사라진 객체의 물리적 궤적을 ‘추론’해냅니다.
⚙️ 시야에서 사라진 객체를 추적하는 ‘HyDRA’ 파이프라인 해부
단순히 이전 프레임의 피처맵을 컨텍스트에 길게 이어 붙이면 안 되냐고요? 네, 안 됩니다. O(N^2)의 어텐션 연산량 때문에 여러분의 H100 GPU 클러스터가 비명을 지르며 뻗어버릴 테니까요.
HyDRA가 영리한 점은 메모리를 압축하고 검색(Retrieval)하는 방식에 있습니다.
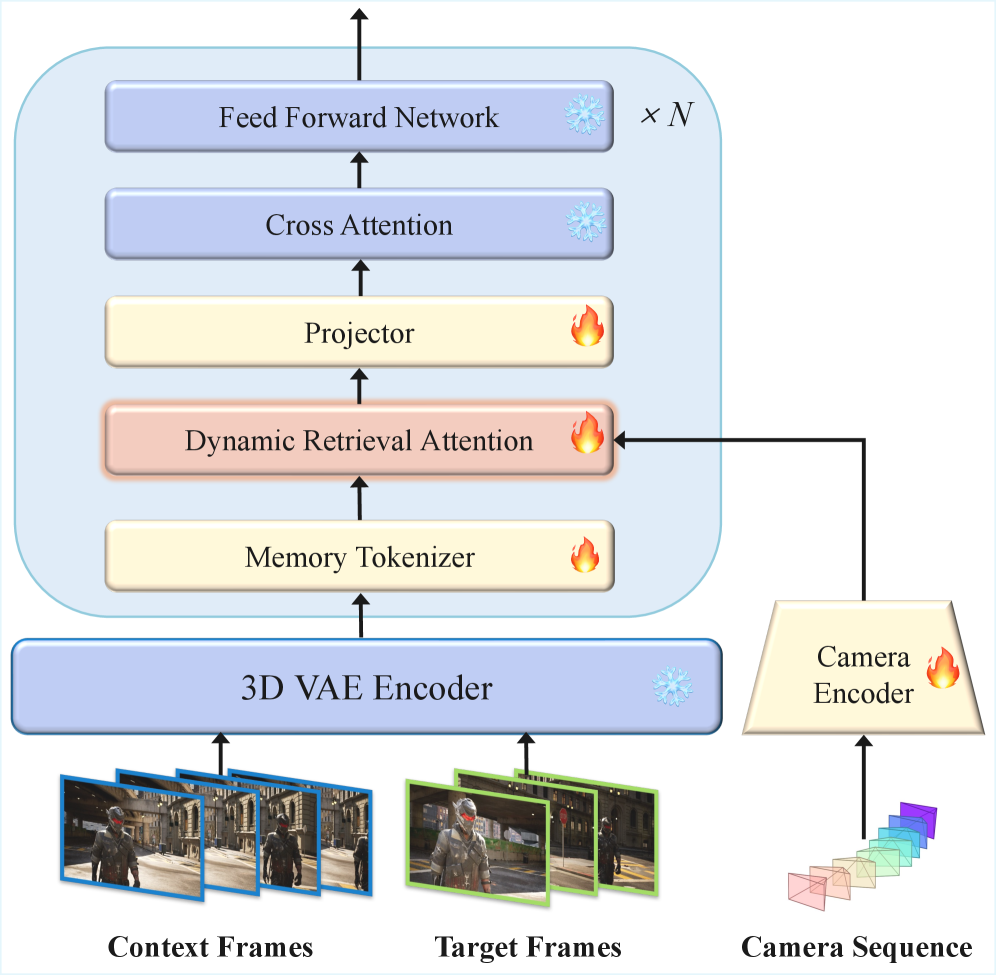 Figure 4: 모델의 전체 아키텍처. 이전 컨텍스트를 무식하게 다 때려 넣는 게 아니라, Memory Bank에 저장한 뒤 현재 쿼리와의 연관성을 계산해 필요한 모션 큐(Motion Cues)만 끌어옵니다.
Figure 4: 모델의 전체 아키텍처. 이전 컨텍스트를 무식하게 다 때려 넣는 게 아니라, Memory Bank에 저장한 뒤 현재 쿼리와의 연관성을 계산해 필요한 모션 큐(Motion Cues)만 끌어옵니다.
이 녀석의 파이프라인은 크게 1) 메모리 토큰화(Tokenization)와 2) 동적 리트리벌 어텐션(Dynamic Retrieval Attention)으로 나뉩니다.
일단 과거의 프레임 피처들을 시공간 축을 따라 풀링(Pooling)하여 고밀도 토큰으로 압축합니다. 이렇게 만들어진 토큰들은 ‘Memory Bank’에 차곡차곡 쌓이죠. 그리고 현재 프레임을 생성할 때, 전체 메모리 뱅크를 순회하는 게 아니라 현재의 타겟 쿼리(Query)와 가장 연관성이 높은 Top-K 개의 토큰만 리트리벌합니다.
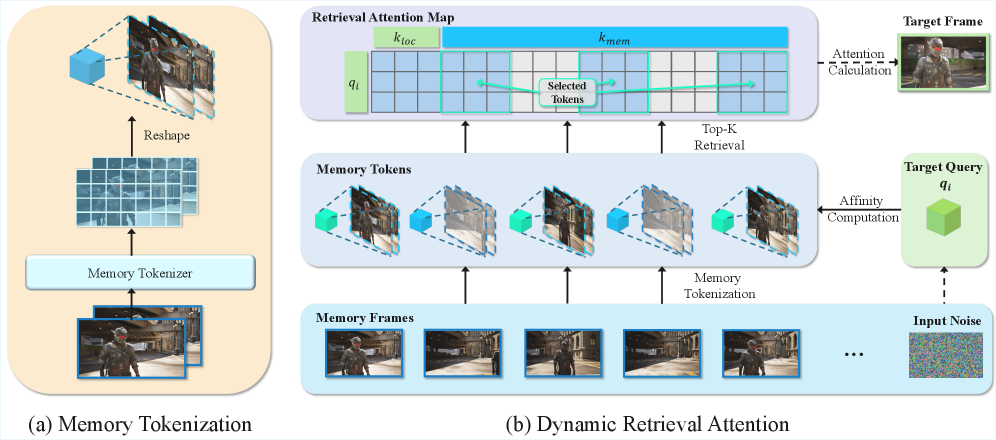 Figure 5: HyDRA의 심장, 리트리벌 어텐션 모듈. 쿼리(Q)가 메모리 뱅크(K, V)와 상호작용할 때 Relevance 스코어를 계산하여 상위 토큰만 선택적으로 참조합니다.
Figure 5: HyDRA의 심장, 리트리벌 어텐션 모듈. 쿼리(Q)가 메모리 뱅크(K, V)와 상호작용할 때 Relevance 스코어를 계산하여 상위 토큰만 선택적으로 참조합니다.
이해를 돕기 위해 제가 파이토치(PyTorch) 스타일로 이 로직의 핵심을 가볍게 목업(Mock-up) 해봤습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
import torch
import torch.nn as nn
import torch.nn.functional as F
class DynamicRetrievalAttention(nn.Module):
def __init__(self, d_model, top_k=64):
super().__init__()
self.top_k = top_k
self.q_proj = nn.Linear(d_model, d_model)
self.k_proj = nn.Linear(d_model, d_model)
self.v_proj = nn.Linear(d_model, d_model)
def forward(self, current_latent, memory_bank):
# current_latent: [B, N, D], memory_bank: [B, M, D]
Q = self.q_proj(current_latent)
K = self.k_proj(memory_bank)
V = self.v_proj(memory_bank)
# 1. Spatiotemporal Relevance Score 계산
scores = torch.matmul(Q, K.transpose(-2, -1)) / (K.size(-1) ** 0.5) # [B, N, M]
# 2. Top-K Retrieval (핵심 포인트!)
# 전체 M개의 메모리 중 현재 쿼리와 가장 연관된 상위 top_k개만 추출
topk_scores, topk_indices = torch.topk(scores, self.top_k, dim=-1)
# 3. Softmax 및 Attention 연산
attn_weights = F.softmax(topk_scores, dim=-1)
# Gather selected Values
topk_indices_expanded = topk_indices.unsqueeze(-1).expand(-1, -1, -1, V.size(-1))
topk_V = torch.gather(V.unsqueeze(1).expand(-1, Q.size(1), -1, -1), 2, topk_indices_expanded)
# 4. 최종 출력 합성
out = torch.matmul(attn_weights.unsqueeze(-2), topk_V).squeeze(-2)
return out
코드에서 보시듯, 핵심은 torch.topk입니다. 객체가 화면 밖으로 나갔더라도, 메모리 뱅크 안에는 그 객체의 이전 모션 벡터와 외형 정보가 토큰화되어 남아있습니다. 모델이 카메라 패닝에 맞춰 “어? 이 위치는 아까 그 자동차가 지나가던 궤적인데?”라고 판단하는 순간, Relevance Score가 치솟으며 해당 객체의 메모리를 다시 화면으로 끄집어내는 원리죠.
⚔️ 기존 스택 vs 새로운 패러다임: 진짜 갈아탈 가치가 있나?
“그래서, 기존 롱컨텍스트(Long-Context) 어텐션 때려 박는 거랑 뭐가 다른데?”라고 물으실 수 있습니다. 표로 한 번 정리해 보죠.
| 비교 지표 | Vanilla Long-Context (기존 방식) | HyDRA (Hybrid Memory) |
|---|---|---|
| 메모리 연산 복잡도 | O(N²) (프레임 길어지면 VRAM 폭발) | O(N × K) (K는 고정된 Top-K, 선형 증가) |
| 객체 영속성 (Exit-Entry) | 프레임 밖으로 나가면 서서히 증발/변형됨 | 화면 밖 궤적을 유지하여 재등장 시 형태 유지 |
| VRAM 사용량 | 씬이 길어질수록 기하급수적으로 증가 | 토큰 압축 + K개 참조로 VRAM 최적화 |
| 구현 난이도 & 오버헤드 | 단순 Attention Window 확장으로 쉬움 | 토큰 압축 및 Retrieval 인덱싱 오버헤드 존재 |
기존 방식은 VRAM을 돈으로 때워야만 했습니다. 하지만 돈으로 때운다 한들 모델의 어텐션 집중도가 분산되면서 결국 객체의 디테일이 뭉개졌죠.
 Figure 6: 기존 SOTA 모델들과의 생성 결과 비교. 빨간 박스를 보세요. 기존 모델들은 객체가 뷰 밖으로 나갔다 돌아오면 배경에 녹아내리거나 아예 다른 객체로 변형되지만, HyDRA(초록 박스)는 원래의 정체성과 형태를 완벽히 유지합니다.
Figure 6: 기존 SOTA 모델들과의 생성 결과 비교. 빨간 박스를 보세요. 기존 모델들은 객체가 뷰 밖으로 나갔다 돌아오면 배경에 녹아내리거나 아예 다른 객체로 변형되지만, HyDRA(초록 박스)는 원래의 정체성과 형태를 완벽히 유지합니다.
HyDRA는 필요한 모션 큐만 딱 집어서 가져오기 때문에 정보의 노이즈가 적습니다. 덕분에 동적 객체의 일관성(Dynamic Subject Consistency)과 전체 생성 품질을 동시에 잡아냈습니다.
🚀 내일 당장 프로덕션에 도입한다면?
이 논문이 재미있는 점은 하이브리드 메모리 연구를 위해 아예 HM-World라는 대규모 데이터셋을 구축했다는 겁니다. 언리얼 엔진 5(UE5)를 써서 카메라 궤적과 객체의 궤적을 완전히 분리(Decoupled)한 59,000개의 클립을 만들었죠.
 Figure 3: 언리얼 엔진 5를 활용한 HM-World 데이터셋 구축 파이프라인. 카메라 무빙과 객체의 움직임을 독립적으로 제어하여, 완벽하게 통제된 ‘시야 이탈/재진입(Exit-entry)’ 데이터를 찍어냈습니다.
Figure 3: 언리얼 엔진 5를 활용한 HM-World 데이터셋 구축 파이프라인. 카메라 무빙과 객체의 움직임을 독립적으로 제어하여, 완벽하게 통제된 ‘시야 이탈/재진입(Exit-entry)’ 데이터를 찍어냈습니다.
이 아키텍처를 실무에 도입한다면 어떤 시나리오가 가능할까요?
1. 자율주행 시뮬레이터용 데이터 제너레이션 현재 자율주행 진영의 가장 큰 페인포인트는 엣지 케이스 데이터 부족입니다. 교차로에서 트럭이 내 시야를 가렸을 때, 그 뒤에 있던 오토바이가 3초 뒤 어디로 튀어나올지 예측하는 시뮬레이션 영상이 필요하죠. HyDRA를 활용하면 이런 ‘가려짐(Occlusion) 후 재등장’ 시나리오를 물리 법칙에 맞게 무한대로 찍어낼 수 있습니다.
2. 게임 엔진의 실시간 NPC 스트리밍 생성 카메라가 돌아갈 때마다 NPC가 랜덤 생성되는 게 아니라, 한 번 화면에 잡혔던 NPC가 플레이어의 시야 밖에서 자신만의 동선으로 움직이다가 다시 자연스럽게 마주치는 ‘살아있는 월드’를 실시간으로 렌더링할 수 있습니다.
🚨 앗, 잠깐. 근데 병목(Bottleneck)은요? 당연히 약점은 있습니다. VRAM은 아꼈지만, 매 프레임마다 거대한 메모리 뱅크에서 Top-K 연산을 수행해야 하므로 Memory Bandwidth 병목이 발생할 수 있습니다. 실시간 생성(Real-time generation) 프로덕션에 붙이려면 FlashAttention 수준의 커스텀 CUDA 커널 최적화가 필수적일 겁니다. 게다가 화면 밖에서 객체의 상태가 변하는 경우(예: 시야 밖에서 차가 폭발함) 이를 추론할 수 있는 외부 프롬프트 주입 로직이 추가로 필요해 보입니다.
🧐 Tech Lead’s Honest Verdict
솔직히 말해서 비디오 생성 모델 논문들, 맨날 “우리 화질 좋아요~” 자랑만 하고 실제 물리 법칙은 죄다 무시하는 경우가 태반이었거든요. 그런데 이 논문은 비디오 모델이 본질적으로 가져야 할 ‘물리적 기억력’을 시스템적으로 접근했다는 점에서 굉장히 높은 점수를 주고 싶습니다.
- 장점 (Pros): 기존 모델들이 해결하지 못했던 아웃오브뷰(Out-of-view) 객체 증발 현상을 아키텍처 레벨(Retrieval)에서 우아하게 풀어냄. VRAM 효율성 면에서도 실무 적용 가능성이 엿보임.
- 단점 (Cons): 훈련 데이터셋(HM-World)이 결국 언리얼 엔진 기반의 ‘합성 데이터(Synthetic Data)’임. 현실 세계의 미친 듯이 복잡한 노이즈와 조명 변화 속에서도 이 리트리벌 어텐션이 제대로 워킹할지는 아직 미지수.
🔥 최종 판정: Clone for Domain-Specific Projects 당장 범용 비디오 서비스에 올리기엔 최적화 이슈가 있겠지만, 자율주행, 로보틱스, 게임 시나리오처럼 도메인이 명확하고 물리적 일관성이 중요한 사내 토이 프로젝트나 R&D에는 내일 당장 이 리트리벌 로직을 클론해서 테스트해 볼 가치가 충분합니다.
단순한 픽셀의 나열이 아니라, ‘시간과 공간을 이해하는 모델’로 가는 꽤나 의미 있는 마일스톤이네요. 이런 거 볼 때마다 엔지니어로서 피가 끓지 않나요? 여러분의 GPU는 당분간 쉴 틈이 없을 것 같습니다.
