[2026-02-12] LLM의 '기억력'을 10배 끌어올리는 기술: 4B 모델로 SOTA를 달성한 QRRanker의 마법

LLM의 ‘기억력’을 10배 끌어올리는 기술: 4B 모델로 SOTA를 달성한 QRRanker의 마법
📖 논문: Query-focused and Memory-aware Reranker for Long Context Processing
🖥️ 프로젝트: HuggingFace Paper Page
LLM의 컨텍스트 윈도우(Context Window)가 1M, 10M으로 늘어나면 모든 문제가 해결될까요? 현실은 그렇지 않습니다. 정보가 많아질수록 모델은 ‘중간에 위치한 정보’를 놓치는 Lost-in-the-Middle 현상을 겪으며, 추론 비용은 기하급수적으로 상승합니다.
💡 한 마디로? QRRanker는 대형 모델 대신 4B 규모의 가벼운 모델에서 특정 ‘검색 헤드(Retrieval Heads)’를 활용해, 긴 문맥 속에서 가장 정확한 정보를 찾아내는 혁신적인 Listwise Reranking 프레임워크입니다.
[1] 🎯 Executive Summary
- 고성능 & 저비용: 단 4B 파라미터 모델로 기존의 대규모 Pointwise/Listwise Reranker를 능가하는 성능을 발휘합니다.
- QR(Query-focused) Attention: LLM 내부의 특정 어텐션 헤드가 질문과 문서 간의 관련성을 포착한다는 점에 착안, 이를 직접 랭킹 점수로 변환합니다.
- Memory-aware Architecture: 단순 문서 검색을 넘어, 대화 이력이나 서사적 맥락(Narrative)을 ‘메모리’로 활용해 정확도를 극대화합니다.
- LoCoMo SOTA: 긴 대화 이해와 메모리 활용 능력을 평가하는 LoCoMo 벤치마크에서 새로운 기록을 세웠습니다.
[2] 🤔 Research Background: 왜 지금 ‘Reranker’인가?
현재의 RAG(Retrieval-Augmented Generation) 시스템은 보통 두 단계로 작동합니다.
- Retriever: 수백만 개의 문서 중 관련 있을 법한 수십 개를 빠르게 추려냅니다.
- Reranker: 추려진 문서들의 우선순위를 정밀하게 재조정합니다.
기존 Reranker들의 한계는 명확했습니다.
- Pointwise 방식: 문서 하나하나를 독립적으로 평가하여 문서 간의 관계를 무시합니다.
- Label Dependency: 고품질의 학습 데이터(Likert-scale)가 대량으로 필요합니다.
- Efficiency: 컨텍스트가 길어질수록 연산량이 폭증하여 B2B 서비스 적용 시 비용 효율성이 떨어집니다.
QRRanker는 이러한 한계를 “어텐션 스코어의 재해석”으로 돌파했습니다.
[3] 🔥 Core Methodology & Architecture
QRRanker의 핵심은 QR(Query-focused Retrieval) Head를 학습시키는 것입니다.
1. 어텐션 스코어 기반의 랭킹 (QR Score)
모델이 질문(Query)을 처리할 때, 특정 어텐션 헤드가 정답이 포함된 문서(Doc)에 강하게 반응한다는 점을 이용합니다. 별도의 복잡한 레이어 추가 없이, 기존 트랜스포머의 어텐션 메커니즘을 랭커로 탈바꿈시켰습니다.
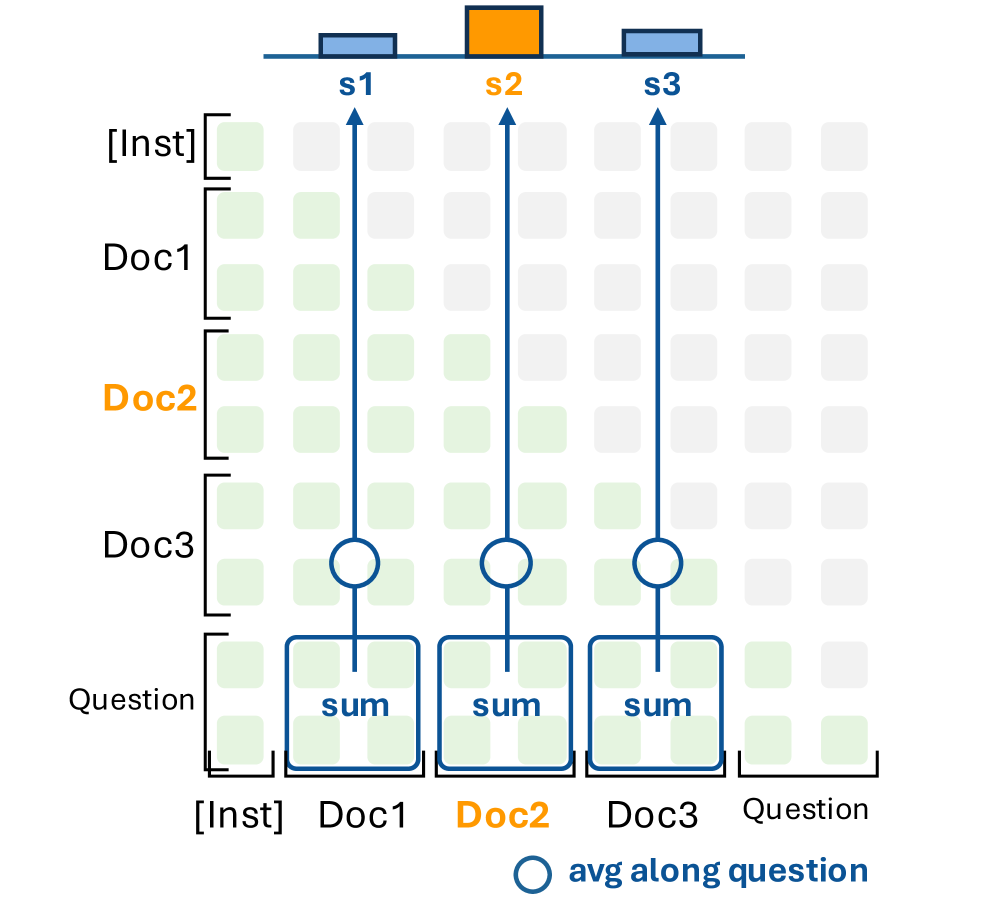 그림 1: 특정 어텐션 헤드(QR Head)가 정답 문서(Doc2)에 대해 높은 점수를 할당하는 메커니즘을 시각화한 모습입니다.
그림 1: 특정 어텐션 헤드(QR Head)가 정답 문서(Doc2)에 대해 높은 점수를 할당하는 메커니즘을 시각화한 모습입니다.
2. 메모리 강화 및 컨텍스트 확장
QRRanker는 단순한 텍스트 매칭을 넘어, 왼쪽 그림처럼 대화나 서사의 흐름을 ‘Memory’ 형태로 저장하고 이를 참조하여 현재 질문과의 연관성을 계산합니다. 이는 특히 긴 소설이나 복잡한 비즈니스 미팅 로그를 분석할 때 탁월한 성능을 보입니다.
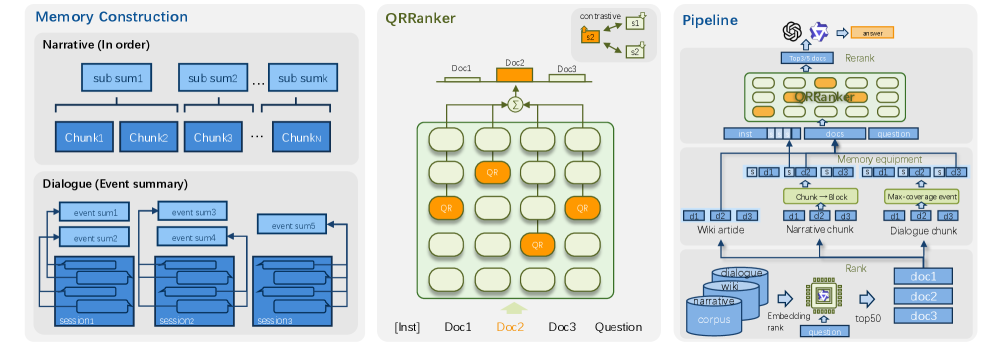 그림 2: QRRanker의 전체 구조. 왼쪽의 메모리 구성부터 중앙의 QR Head 기반 스코어링, 오른쪽의 전체 파이프라인까지를 보여줍니다.
그림 2: QRRanker의 전체 구조. 왼쪽의 메모리 구성부터 중앙의 QR Head 기반 스코어링, 오른쪽의 전체 파이프라인까지를 보여줍니다.
[4] 💼 Practical Application & Market Impact
이 기술이 비즈니스 현장에 가져올 변화는 파괴적입니다.
- B2B AI SaaS 비용 절감: 70B 이상의 대형 모델을 Reranker로 쓰던 기업들은 4B 모델인 QRRanker로 전환함으로써 인프라 비용을 80% 이상 절감하면서도 성능은 유지하거나 높일 수 있습니다.
- 지능형 고객 상담 에이전트: 수년 치의 고객 상담 이력을 ‘메모리’로 참조하여, 현재 상담 맥락에 가장 적합한 과거 사례를 순식간에 찾아낼 수 있습니다.
- 법률 및 의료 데이터 분석: 수백 페이지에 달하는 판례나 임상 기록에서 핵심적인 근거 문서를 순위화하여 전문가의 의사결정을 지원합니다.
| 비교 항목 | 기존 Reranker (Pointwise) | QRRanker (Listwise) |
|---|---|---|
| 컨텍스트 이해도 | 단일 문서 중심 (좁음) | 전체 후보군 동시 고려 (넓음) |
| 데이터 효율성 | 대량의 라벨링 데이터 필요 | 비지도/약지도 학습 가능 |
| 추론 속도 | 문서 수에 비례하여 증가 | 효율적인 어텐션 활용으로 빠름 |
[5] 🧑💻 Expert’s Touch: Critique & Implementation
⚡ 1-line Verdict
“거대 모델의 만능주의에서 벗어나, 트랜스포머 내부의 ‘검색 DNA’를 가장 영리하게 추출해낸 실용주의적 정점입니다.”
🚧 Technical Challenges
- Head Selection: 어떤 레이어의 어떤 헤드를 QR Head로 지정할지가 성능의 핵심입니다. 논문에서는 중간 레이어의 헤드를 학습시키는 것이 효율적이라고 제안하지만, 도메인에 따라 최적의 헤드 위치가 달라질 수 있습니다.
- Memory Overhead: 메모리 강화 시 저장되는 컨텍스트 정보의 관리(Management)와 업데이트 전략이 프로덕션 환경에서는 병목이 될 수 있습니다.
🛠️ Practical Tips for Developers
- 기존 RAG 파이프라인 교체: 현재 Pinecone이나 Milvus를 사용하는 팀이라면, 상위 100개의 결과를 뽑은 뒤 QRRanker를 적용해 보세요. 전체 LLM 호출 횟수를 줄이면서 정답률(Hit Rate)을 획기적으로 높일 수 있습니다.
- Fine-tuning 전략: 자사 서비스만의 특수한 데이터(예: 코드 리뷰 로그)가 있다면, 해당 도메인의 문서를 이용해 특정 어텐션 헤드만 미세 조정하는 것만으로도 강력한 도메인 특화 랭커를 구축할 수 있습니다.
AI의 성능은 이제 파라미터 숫자가 아니라, 데이터를 얼마나 영리하게 읽어내느냐에 달려 있습니다. QRRanker는 그 새로운 이정표를 제시하고 있습니다. 🚀
