[2026-02-25] 이제 AI도 '멀티'가 됩니다: 마인크래프트로 구현한 최초의 멀티플레이어 월드 모델, Solaris

최근 구글의 GameNGen(둠 게임 시뮬레이션)이나 OpenAI의 Sora 같은 비디오 생성 모델들이 핫했죠. 그런데 이 모델들의 공통적인 한계가 뭔지 아시나요? 바로 ‘혼자 노는 AI’라는 겁니다.
현실 세계나 우리가 즐기는 대부분의 게임(MMORPG, FPS)은 다수의 에이전트가 상호작용하는 멀티플레이 환경입니다. 내가 당신을 때리면, 당신의 화면에서도 맞는 장면이 나와야 하죠. 이걸 ‘View Consistency(시점 일관성)’라고 하는데, 지금까지의 모델들은 이걸 제대로 다루지 못했습니다.
오늘 소개할 Solaris는 바로 이 난제를 마인크래프트를 통해 정면 돌파한 논문입니다. 솔직히 말해서, 단순한 비디오 생성을 넘어 ‘진정한 가상 세계 시뮬레이터’로 가는 첫 단추를 꿴 것 같아 꽤 흥분되네요.
📖 논문 정보
- 논문: Solaris: Building a Multiplayer Video World Model in Minecraft
- ID: 2602.22208
- 주제: Multi-agent Video World Model, Generative AI
💡 한 마디로? “나만 잘하면 되는 게 아니라, 너와 내가 보는 세상이 일치하도록 학습하는 최초의 멀티플레이어 비디오 월드 모델.”
1. 도대체 뭐가 다른 건데? (The Concept)
기존의 비디오 월드 모델(Video World Models)은 기본적으로 ‘1인칭 슈팅 게임’을 혼자 하는 것과 같았습니다. 입력된 행동(Action)에 따라 화면이 어떻게 변할지만 예측하면 됐죠.
하지만 Solaris는 다릅니다. 두 명 이상의 플레이어가 같은 공간에 있을 때, 각자의 행동이 서로의 화면에 어떻게 비칠지를 동시에 시뮬레이션합니다.
예를 들어 설명해 볼게요:
- 기존 모델: “내가 검을 휘두른다” -> 내 화면에 검이 나가는 게 보임. (끝)
- Solaris: “플레이어 A가 검을 휘두른다”
- -> A의 화면: 검을 휘두르는 모습 생성
- -> B의 화면: A가 나를 향해 검을 휘두르는 모습이 동시에, 정확한 타이밍에 생성
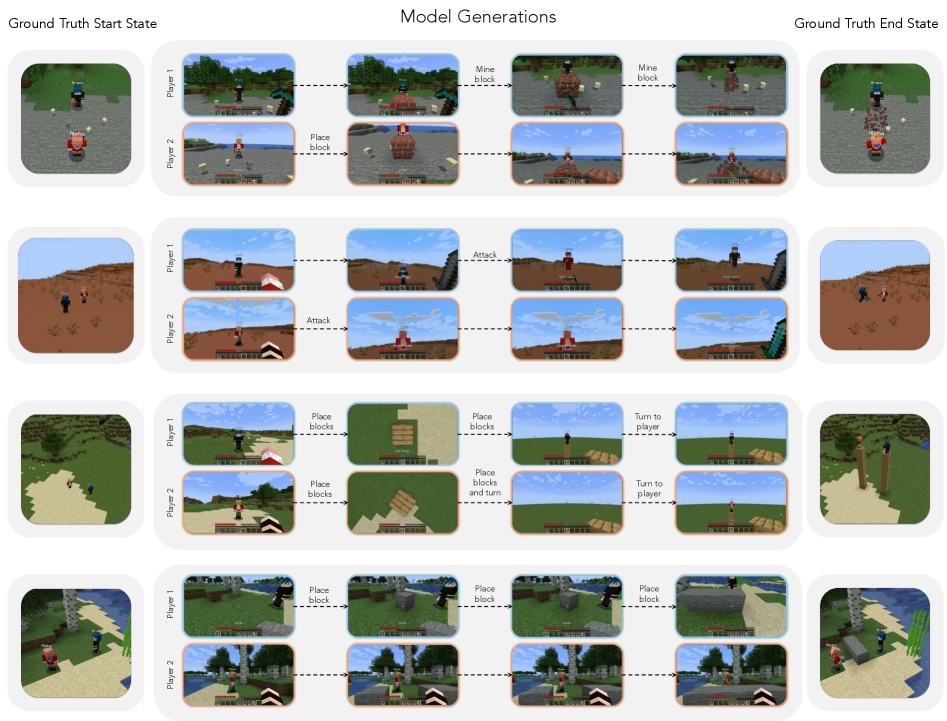 ▲ Solaris가 생성한 샘플입니다. 상단은 Player 1, 하단은 Player 2의 시점입니다. 서로 다른 위치에 있지만 같은 ‘세계’를 공유하고 있다는 게 느껴지시나요?
▲ Solaris가 생성한 샘플입니다. 상단은 Player 1, 하단은 Player 2의 시점입니다. 서로 다른 위치에 있지만 같은 ‘세계’를 공유하고 있다는 게 느껴지시나요?
이게 말은 쉬워 보이는데, 기술적으로는 ‘인과관계의 악몽’입니다. A의 행동이 B의 관측에 즉각적인 영향을 줘야 하니까요.
2. 핵심 기능 및 비교 (Deep Dive)
이 논문이 재미있는 점은 단순히 모델만 만든 게 아니라, ‘데이터를 어떻게 모을 것인가?’에 엄청난 공을 들였다는 겁니다. 연구진은 SolarisEngine이라는 시스템을 만들어 Docker 컨테이너 기반으로 마인크래프트 봇들을 돌리며 1,200만 프레임(12.64M)을 수집했습니다.
🛠️ 기존 모델 vs Solaris 비교
사실상 이 분야의 첫 시도라 직접적인 경쟁작은 없지만, 기존 싱글 에이전트 모델(Single-Agent World Model)과 비교하면 차이가 명확합니다.
| 비교 항목 | 기존 싱글 에이전트 모델 (예: GameNGen) | Solaris (본 논문) |
|---|---|---|
| 에이전트 수 | 1명 (Single Player) | N명 (Multi Player) |
| 시점 일관성 | 불필요 (나만 보면 됨) | 필수 (서로의 화면이 논리적으로 맞아야 함) |
| 상호작용 | 환경 vs 나 | 나 vs 너 vs 환경 |
| 아키텍처 | 독립적인 비디오 생성 | Interleaved Attention (정보 교환) |
| 데이터 난이도 | 낮음 (그냥 녹화하면 됨) | 매우 높음 (모든 클라이언트 동기화 필수) |
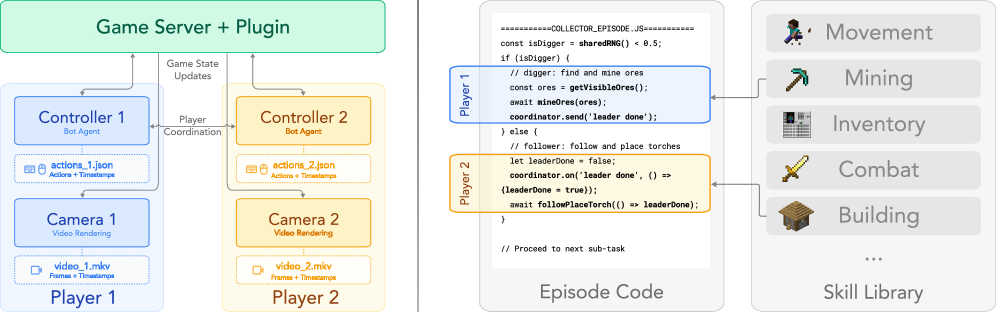 ▲ 연구진이 갈아 넣은 엔지니어링의 결정체, SolarisEngine입니다. 단순히 화면만 캡처하는 게 아니라, 서버 상태와 봇의 액션을 완벽하게 동기화했습니다. 노가다의 승리네요. 👏
▲ 연구진이 갈아 넣은 엔지니어링의 결정체, SolarisEngine입니다. 단순히 화면만 캡처하는 게 아니라, 서버 상태와 봇의 액션을 완벽하게 동기화했습니다. 노가다의 승리네요. 👏
이 시스템 덕분에 ‘전투(Combat)’, ‘건축(Building)’, ‘이동(Movement)’ 등 다양한 시나리오에서 멀티플레이 데이터를 확보할 수 있었습니다. 특히 마인크래프트는 블록 기반이라 3D 정합성을 검증하기 딱 좋은 환경이죠.
3. 기술적으로 어떻게 풀었나? (The Tech)
이 부분이 핵심입니다. 어떻게 두 개의 영상을 동시에 생성하면서 서로 내용을 일치시킬까요? 연구진은 DiT (Diffusion Transformer) 구조를 비틀었습니다.
🧩 Visual Interleaving (시각적 끼워넣기)
보통 배치(Batch) 처리를 하면 A와 B의 영상은 서로 독립적으로 계산됩니다. 하지만 Solaris는 시퀀스 차원에서 이 토큰들을 인터리빙(Interleaving) 해버립니다.
1
2
3
4
5
6
7
# 개념적 의사 코드 (Conceptual Code)
# 기존: [Batch_A, Tokens], [Batch_B, Tokens] -> 서로 모름
# Solaris:
sequence = [Token_A_t1, Token_B_t1, Token_A_t2, Token_B_t2, ...]
# 이렇게 섞어놓고 Self-Attention을 돌리면?
# A의 토큰이 B의 토큰을 '참조(Attend)'할 수 있게 됩니다!
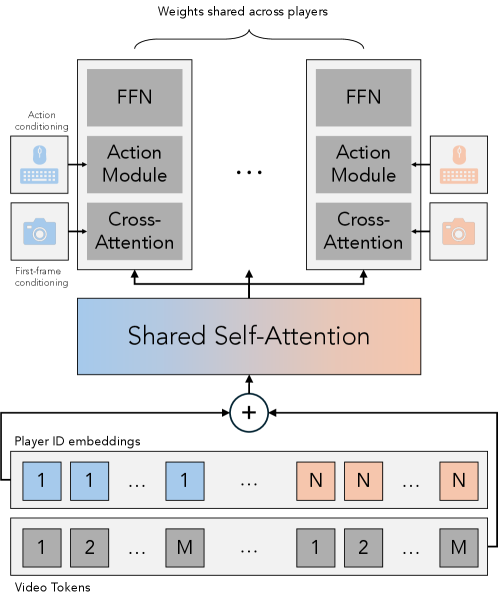 ▲ 아키텍처 다이어그램입니다. 플레이어 N명의 토큰을 시퀀스 차원에서 섞어서(Interleaving), 하나의 거대한 Transformer가 모든 뷰를 동시에 처리하게 만들었습니다. 심플하지만 강력한 아이디어죠.
▲ 아키텍처 다이어그램입니다. 플레이어 N명의 토큰을 시퀀스 차원에서 섞어서(Interleaving), 하나의 거대한 Transformer가 모든 뷰를 동시에 처리하게 만들었습니다. 심플하지만 강력한 아이디어죠.
또한, 학습 과정에서 ‘Checkpointed Self Forcing’이라는 기법을 도입했습니다. 긴 호라이즌(Long-horizon)을 학습하려면 메모리가 터져나가는데, 체크포인팅을 통해 메모리 효율을 챙기면서도 Teacher Forcing 효과를 유지했습니다. 덕분에 VRAM 부족에 시달리는 연구자들에게 희소식이 될 만한 테크닉을 보여줍니다.
🔥 에디터의 생각 (Editor’s Verdict)
이 논문은 단순히 “마인크래프트 비디오를 만들었다”가 아닙니다. AGI가 가상 세계를 이해하려면 결국 ‘타인(Other Agents)’의 존재를 인지해야 한다는 철학이 깔려 있습니다.
👍 장점 (Pros)
- 최초의 멀티플레이어 월드 모델: 이 분야를 개척했다는 점만으로도 가치가 높습니다.
- 데이터셋 공개: 1,200만 프레임의 멀티플레이 데이터셋(
Solaris-Data)은 추후 연구에 엄청난 자산이 될 겁니다. - 현실적인 엔지니어링: 단순히 이론에 그치지 않고, 도커 기반의 수집 파이프라인부터 메모리 최적화 학습법까지 실무적인 꿀팁이 가득합니다.
👎 아쉬운 점 / 한계 (Cons)
- 해상도와 비주얼: 마인크래프트 특유의 단순함 덕분에 가능했던 측면이 있습니다. 복잡한 실사 그래픽(Unreal Engine 5급)에서도 이 방식이 통할지는 미지수입니다.
- 확장성(Scalability): 플레이어가 2명을 넘어 10명, 100명이 되면
Interleaving방식의 연산량이 제곱으로 늘어날 텐데, 이에 대한 대책은 좀 더 고민이 필요해 보입니다.
🎯 총평: “Sora가 혼자 영화를 찍는 감독이라면, Solaris는 배우들이 서로 합을 맞추게 하는 무대 연출가입니다. 멀티 에이전트 강화학습(MARL)이나 시뮬레이션 연구자라면 필독(Must Read)을 권합니다.”
Additional Figures
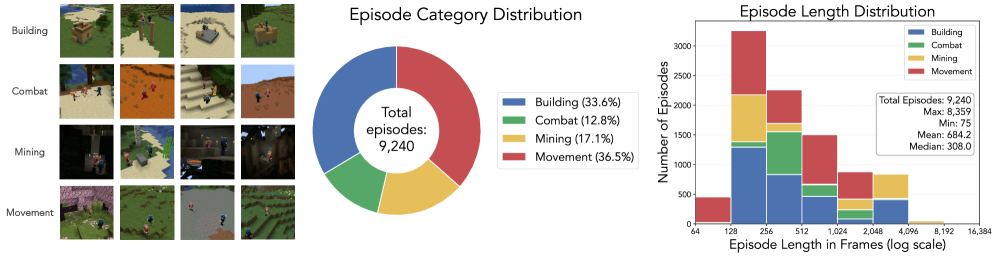 Figure 3:Dataset Statistics of our training dataset.(Left)The dataset consists of four different episode categories focusing on building, combat, movement, and mining scenarios, respectively.(Middle)It has a total of 9,240 episodes and 6.32 M frames per player, for a combined 12.64 M frames. Episode types are chosen randomly with weights that decrease with respect to the typical episode length.(Right)Most episode lengths range from 128 to 512 frames or 6.4 to 25.6 seconds (we record at 20 fps).
Figure 3:Dataset Statistics of our training dataset.(Left)The dataset consists of four different episode categories focusing on building, combat, movement, and mining scenarios, respectively.(Middle)It has a total of 9,240 episodes and 6.32 M frames per player, for a combined 12.64 M frames. Episode types are chosen randomly with weights that decrease with respect to the typical episode length.(Right)Most episode lengths range from 128 to 512 frames or 6.4 to 25.6 seconds (we record at 20 fps).
 Figure 4:Episode Demonstrations from our training dataset.We show the recorded frames from 3 different training episodes at various points in time. Note that the third-person “start state” and “end state” screenshots are for visualization only and are not part of the dataset.
Figure 4:Episode Demonstrations from our training dataset.We show the recorded frames from 3 different training episodes at various points in time. Note that the third-person “start state” and “end state” screenshots are for visualization only and are not part of the dataset.
