[2026-03-25] 4B 모델로 휴먼 레벨을 씹어먹다? 실패에서 배우는 GUI 에이전트 UI-Voyager 해부

[Paper] UI-Voyager: A Self-Evolving GUI Agent Learning via Failed Experience [ID] 2603.24533 [Date] March 2026 [Authors] UI-Voyager Team
모바일 GUI 에이전트 개발해보신 분들은 알 겁니다. 라벨링 노가다가 얼마나 사람 피 말리게 하는지요. 화면 캡처하고, 바운딩 박스 치고, ‘다음 행동은 스크롤 다운’이라고 일일이 태깅하다 보면 내가 개발자인지 데이터 라벨러인지 현타가 오거든요. 그렇다고 RL(강화학습)을 태우자니, 긴 호흡의 GUI 태스크에서는 보상 체계가 너무 희소(Sparse)해서 모델이 학습을 포기해버립니다. 15단계까지 잘 클릭하다가 마지막 결제 버튼 하나 잘못 눌러서 실패하면, 그 앞의 15번의 훌륭한 액션까지 통째로 쓰레기통에 처박히는 게 기존 파이프라인의 현실이었죠.
잠깐, 여기서 의문이 들죠. ‘그 15번의 올바른 액션과 1번의 뻘짓을 분리해서 가르칠 순 없을까?’
오늘 뜯어볼 UI-Voyager는 바로 이 지점을 파고들었습니다. 비싼 GPT-4V API 호출이나 수작업 라벨링 없이, 오직 모델 스스로 삽질하며 얻은 ‘실패한 궤적(Failed Trajectory)’을 재활용해 4B 파라미터의 작은 체급으로 AndroidWorld 벤치마크 81.0% 성공률을 찍어버렸거든요. 인간 수준을 넘어선 수치입니다. 이 녀석들이 도대체 무슨 흑마법을 부렸는지, 인프라 비용 절감에 얼마나 도움이 될지 밑바닥부터 파헤쳐 보겠습니다.
TL;DR: UI-Voyager는 버려지던 ‘실패한 궤적’에서 분기점(Fork point)을 찾아내 성공한 궤적의 액션으로 교정(GRSD)하는 4B 경량 GUI 에이전트입니다. 수작업 라벨링 없이 RFT와 자가 증류만으로 SOTA를 찍었지만, 동적인 UI 환경에서의 비전 매칭 의존도는 주의해야 합니다.
⚙️ 쓸모없는 삽질을 ‘오답 노트’로 연성하는 파이프라인 해부
기존 MLLM 기반 에이전트들은 주로 SFT(지도미세조정)에 의존했습니다. 문제는 좋은 데이터가 부족하다는 거였죠. UI-Voyager는 이 문제를 RFT(Rejection Fine-Tuning)와 GRSD(Group Relative Self-Distillation)라는 투트랙 자가 진화(Self-Evolving) 구조로 해결했습니다.
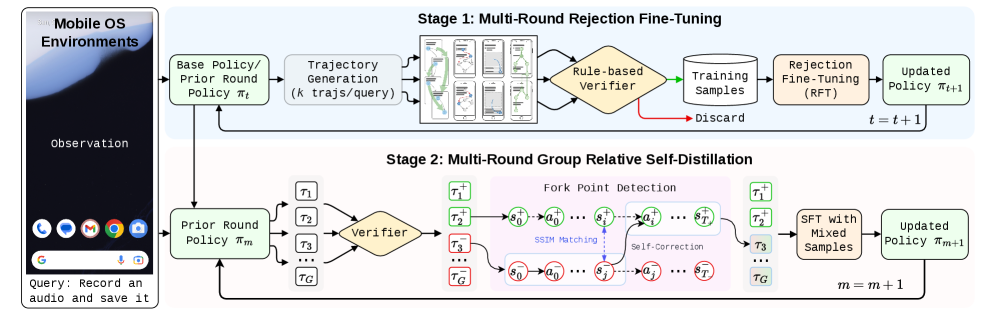
- [그림 설명] UI-Voyager의 핵심 학습 파이프라인입니다. RFT로 양질의 데이터를 모으고, GRSD로 실패한 데이터를 오답 노트처럼 활용해 정책 모델을 끝없이 깎아내는 구조죠.*
🔹 Stage 1: Rejection Fine-Tuning (RFT) 먼저 기본 정책(Base policy) 모델을 환경에 던져놓고 수많은 궤적을 생성하게 둡니다. 그리고 룰 기반 검증기(Rule-based verifier)를 통해 성공한 궤적만 필터링해서 SFT를 진행하죠. 여기까지는 꽤 익숙한 접근입니다. 하지만 진짜 마법은 두 번째 스테이지에 있습니다.
🔹 Stage 2: GRSD (Group Relative Self-Distillation) 강화학습에서 PPO 같은 알고리즘이 긴 GUI 태스크에서 죽을 쑨 이유는 ‘신용 할당(Credit Assignment)’의 모호함 때문입니다. 전체 과정 중 어디서 망했는지 모델이 알 길이 없었거든요. GRSD는 이 문제를 해결하기 위해 ‘분기점(Fork Point)’이라는 개념을 도입합니다. 성공한 궤적과 실패한 궤적을 나란히 놓고 비교하다가, 화면 상태(Screen State)는 같은데 액션이 갈라지는 정확한 시점을 찾아내는 겁니다.
글로만 보면 감이 안 오실 테니, 실제로 이 녀석들이 내부적으로 데이터를 어떻게 라우팅하고 처리하는지 파이썬 의사 코드(Mock-up)로 재구성해 보겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import cv2
from skimage.metrics import structural_similarity as ssim
def detect_fork_point(traj_success, traj_failed, ssim_threshold=0.95):
# 성공한 궤적과 실패한 궤적의 각 스텝을 순회합니다.
for step_s, obs_s, act_s in traj_success:
for step_f, obs_f, act_f in traj_failed:
# 1. 두 화면의 시각적 유사도(SSIM)를 계산합니다.
similarity = ssim(obs_s['image'], obs_f['image'])
if similarity > ssim_threshold:
# 2. 화면 상태는 동일한데, 취한 행동(Action)이 다르다면?
if act_s != act_f:
print(f"[!] Fork Point 감지됨: 실패 궤적의 {step_f}번째 스텝")
# 3. 실패한 궤적의 해당 스텝에 성공한 액션을 덮어씌워 지도학습(Supervision) 데이터로 변환
return create_dense_supervision(step_f, correct_action=act_s)
return None
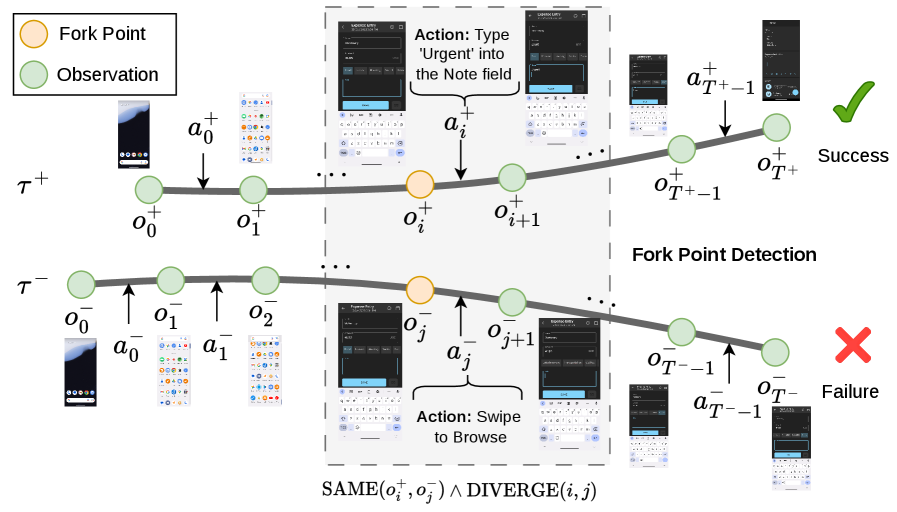
- [그림 설명] 분기점(Fork point) 탐지 전략의 개념도입니다. 화면 상태가 동일한 교차점을 찾아내고, 거기서 엇나간 실패 궤적의 액션을 성공 궤적의 정답으로 멱살 잡고 끌고 오는 방식입니다.*
이 로직의 천재적인 부분은 버려질 뻔한 실패 궤적(Failed Trajectory)의 앞부분을 완벽한 학습 데이터로 재활용한다는 겁니다. 15번 잘하다가 16번째에 망했다면, 망한 16번째 액션만 성공 궤적의 액션으로 교체해서 모델에게 다시 먹이는 거죠. 이게 바로 논문에서 말하는 ‘Dense step-level supervision’의 실체입니다.
⚔️ 기존 스택 vs 새로운 패러다임: 진짜 갈아탈 가치가 있나?
그럼 이게 우리 지갑 사정과 퇴근 시간에 얼마나 도움이 될까요? 기존 강화학습(PPO) 기반 에이전트나 GPT-4V를 호출하는 무식한 방법과 비교해 봅시다.
| Metric | 기존 RL 기반 (PPO 등) | 거대 상용 MLLM (GPT-4V 등) | UI-Voyager (4B) |
|---|---|---|---|
| 학습 효율성 | 매우 낮음 (희소 보상 병목) | API 비용 폭발 ($$$) | 매우 높음 (오답 노트 자가 증류) |
| 인프라 요구사항 | A100 클러스터 필요 | 클라우드 종속 (데이터 프라이버시 X) | 로컬 엣지 디바이스 또는 RTX 4090 1대 |
| 실패 데이터 처리 | 통째로 버림 (Reward 0) | 프롬프트 엔지니어링으로 똥꼬쇼 | GRSD로 100% 재활용 |
| 성공률 (Pass@1) | 40~50% 대 | 70% 초반 | 81.0% (휴먼 레벨 초월) |
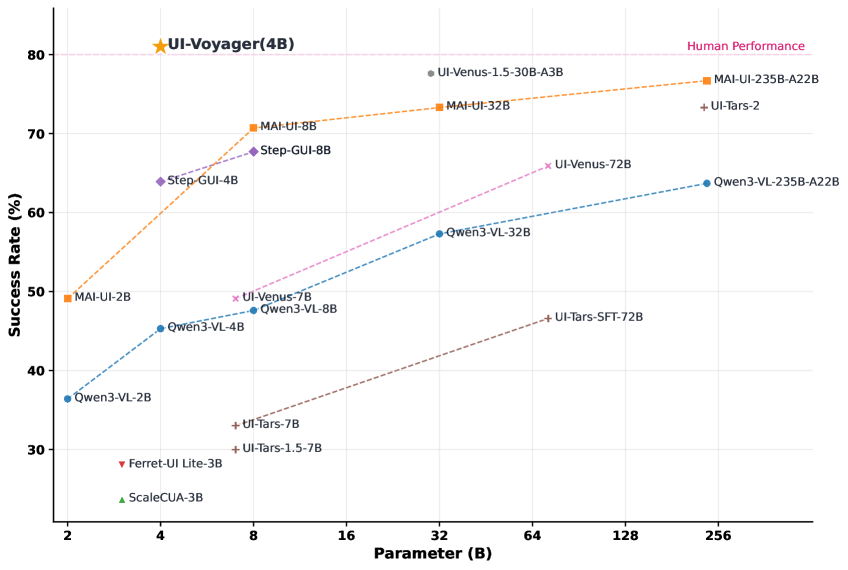
- [그림 설명] AndroidWorld 벤치마크 결과입니다. 4B라는 깃털 같은 파라미터로 상용 거대 모델들은 물론, 사람의 평균 성공률마저 아득히 뛰어넘은 걸 볼 수 있습니다.*
표를 보시면 아시겠지만, 핵심은 ‘가성비’와 ‘자가 진화’입니다. GPT-4V로 GUI 에이전트를 구성하면 클릭 한 번에 몇 백 원씩 API 비용이 타들어갑니다. 게다가 회사 내부 인트라넷 화면을 OpenAI 서버로 보낼 수도 없죠. 반면 UI-Voyager는 4B 모델입니다. VRAM 8GB짜리 로컬 GPU에서도 양자화 없이 쌩쌩 돌아가는 체급이란 뜻입니다. 내 로컬 환경에서 실패 데이터를 먹으며 스스로 진화하는 에이전트를 띄울 수 있다는 건 엄청난 메리트죠.
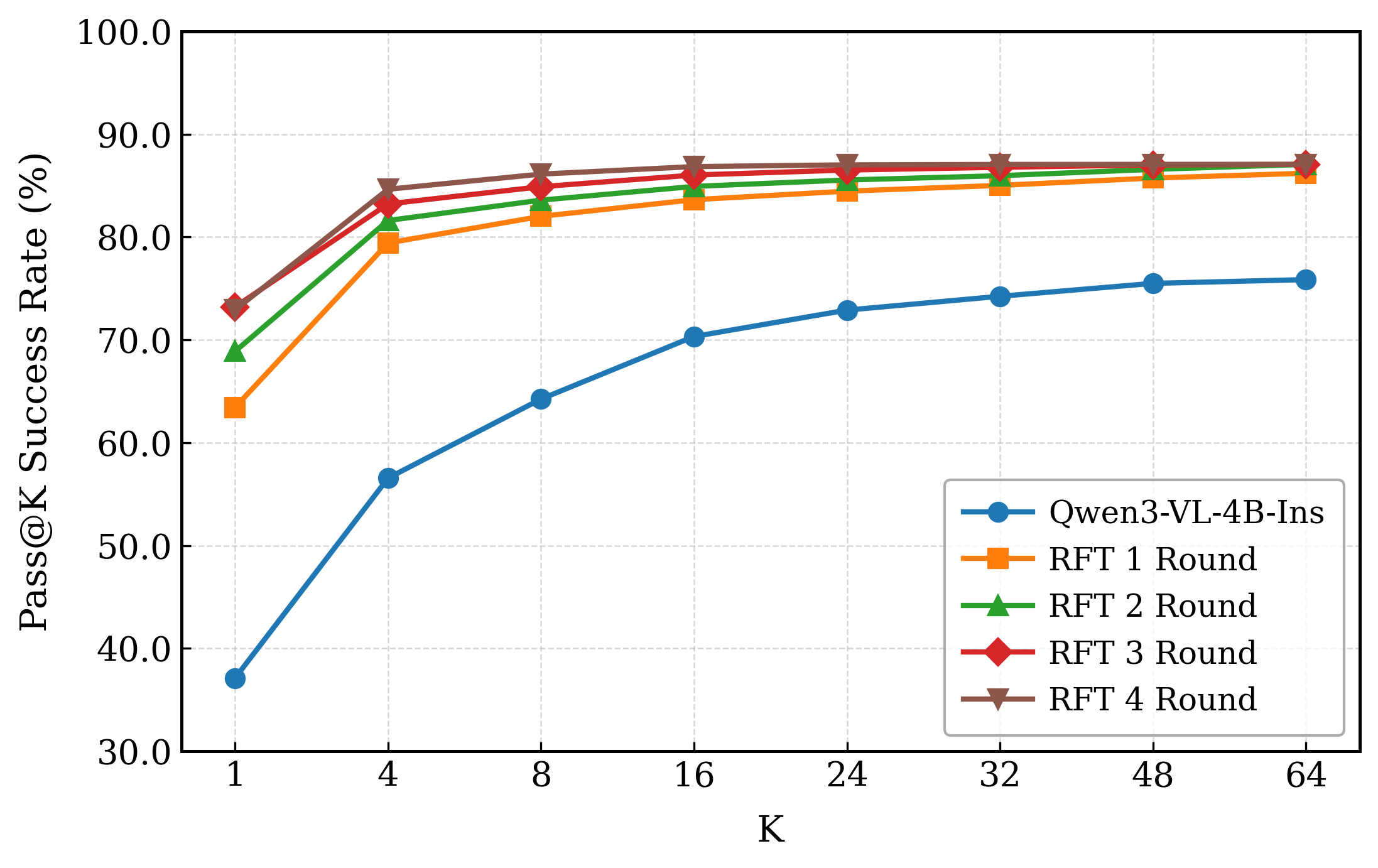
- [그림 설명] RFT를 반복할수록 성능이 수직 상승하는 모습(좌측)과, 억지로 RL(PPO/GRPO)을 태웠을 때 학습이 지지부진한 모습(우측)의 뚜렷한 대비를 보여줍니다.*
🚀 내일 당장 프로덕션에 도입한다면?
이론은 훌륭합니다. 그럼 당장 우리 팀 프로젝트에 이걸 어떻게 써먹을 수 있을까요? 두 가지 실전 시나리오를 구상해 봤습니다.
1. 이커머스 앱 QA 자동화 봇 우리 앱은 매주 업데이트됩니다. 결제 플로우가 깨지지 않았는지 확인하려면 QA 팀이 하루 종일 폰을 붙잡고 있어야 하죠. UI-Voyager 기반 봇을 스테이징 환경에 붙여놓고 밤새 ‘항공권 예약 후 결제’ 태스크를 던져줍니다. 처음엔 버튼 위치를 못 찾아 실패하겠지만, 한두 번 우연히 성공하는 궤적이 나오면 GRSD가 발동합니다. 실패했던 궤적들을 즉시 ‘오답 노트’로 만들어 밤새 모델을 SFT 시켜버립니다. 다음 날 아침이면 완벽하게 결제 플로우를 테스트하는 4B짜리 맞춤형 QA 봇이 탄생하는 겁니다.
2. 온디바이스 RPA (Robotic Process Automation) 영업팀 직원들이 매일 아침 사내 메신저에서 특정 첨부파일을 다운받아 ERP에 올리는 반복 작업을 한다고 칩시다. 4B 모델이므로 임직원들의 랩톱에 직접 올려서 돌릴 수 있습니다. 초기 세팅만 잘 잡아주면, 직원들의 실제 조작(성공 궤적)과 에이전트의 삽질(실패 궤적)을 매칭하여 로컬에서 스스로 똑똑해지는 개인화 RPA가 가능해집니다.
⚠️ 프로덕션 스케일링의 치명적 병목 (Bottlenecks) 하지만 실전은 논문처럼 아름답지 않습니다. GRSD의 핵심은 화면 상태를 비교하는 SSIM(구조적 유사도)입니다. 픽셀 단위의 유사도를 본다는 뜻이죠. 만약 여러분의 앱에 화려한 애니메이션 로딩 바, 혹은 3초마다 바뀌는 하단 배너 광고가 있다면 어떻게 될까요? 화면 내의 돔(DOM) 요소는 완벽히 동일해도, 광고 배너의 픽셀이 바뀌었기 때문에 SSIM 수치가 떡락합니다. 결국 모델은 “어? 이거 아까 성공했을 때랑 다른 화면이네?”라고 착각하고 Fork Point 탐지를 포기해 버릴 겁니다.
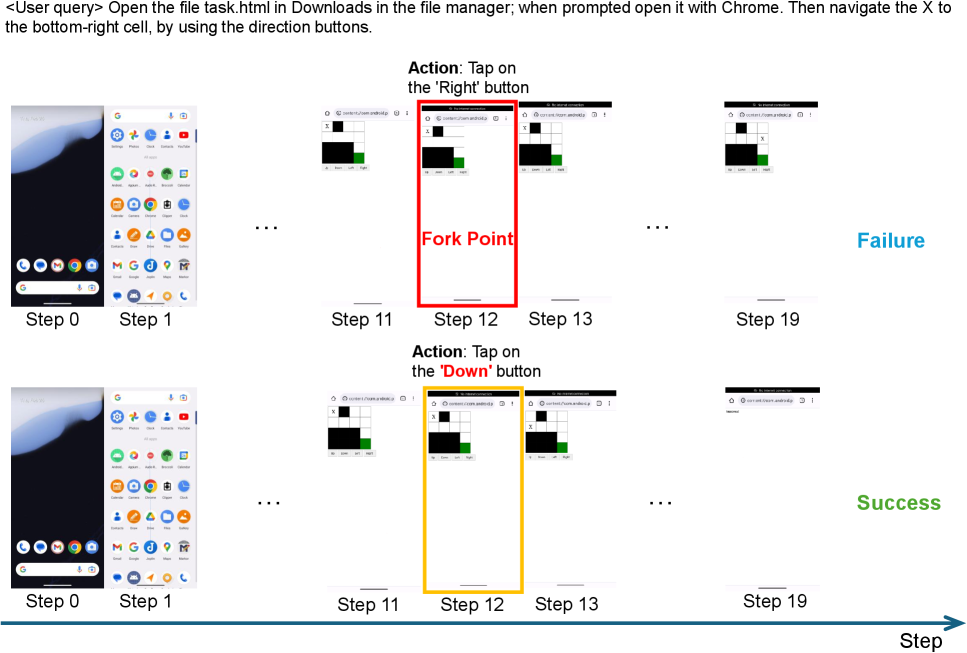
- [그림 설명] BrowserMaze 환경에서의 Fork Point 탐지 예시입니다. 12번째 스텝에서 실패 궤적(벽으로 돌진)과 성공 궤적(아래로 이동)이 정확히 갈라지는 것을 픽셀 기반으로 잡아냅니다.*
🧐 Tech Lead’s Honest Verdict
솔직히 말해, 실패 궤적을 재활용하겠다는 아이디어 자체는 새롭지 않습니다. 하지만 그걸 MLLM 기반 GUI 에이전트에, 그것도 SSIM을 이용한 Fork Point라는 직관적인 방식으로 풀어내어 ‘학습 불가능에 가깝던 긴 호흡의 태스크’를 ‘지도 학습’의 영역으로 끌어내린 건 천재적인 발상입니다.
👍 Pros:
- API 비용 0원. 인간의 라벨링 노동력 0원.
- 4B라는 극단적으로 가벼운 체급 덕분에 온디바이스 배포 쌉가능.
- 보상이 희소한 환경에서 RL 대신 RFT+GRSD(증류)를 택한 실용적인 엔지니어링.
👎 Cons:
- 비전(Pixel) 기반 매칭의 한계. 동적 UI(비디오 플레이어, 플래시 광고 등)가 많은 환경에서는 Fork Point 탐지 로직이 무용지물이 될 확률 99%.
- RFT 1단계에서 쓰이는 ‘룰 기반 검증기(Rule-based verifier)’는 결국 개발자가 태스크마다 성공 조건을 하드코딩해야 한다는 뜻. 완전한 ‘자율’이라고 부르기엔 아직 찝찝함이 남음.
🔥 Final Verdict: “사내 장난감 프로젝트나 정적인 앱의 QA 자동화 용도로 즉시 Clone 후 도입. 단, 유저를 직접 마주하는 다이내믹한 B2C 프로덕션 배포는 v2에서 비전 매칭 로직이 개선될 때까지 대기할 것.”
