[2026-02-12] UniT: 통합 멀티모달 모델의 사고 연쇄(CoT)와 추론 시간 스케일링의 혁신적 분석

UniT: 통합 멀티모달 모델의 사고 연쇄(CoT)와 추론 시간 스케일링의 혁신적 분석
1. 핵심 요약 (Executive Summary)
최근 대규모 언어 모델(LLM) 분야에서 가장 뜨거운 화두 중 하나는 OpenAI의 o1 모델과 같은 추론 시간 스케일링(Test-time Scaling, TTS)입니다. 이는 모델이 더 많은 추론 시간(inference compute)을 사용하여 복잡한 논리적 문제를 해결하는 방식입니다. 하지만 이러한 패러다임을 시각적 이해와 생성이 동시에 이루어지는 통합 멀티모달 모델(Unified Multimodal Models)에 적용하는 것은 매우 어려운 과제였습니다.
본 분석에서 다룰 UniT(Unified Multimodal Chain-of-Thought Test-time Scaling) 프레임워크는 멀티모달 모델이 스스로 ‘생각’하고, ‘검증’하며, ‘수정’하는 사고 연쇄(Chain-of-Thought, CoT) 과정을 통해 이 문제를 해결합니다. UniT의 핵심 기여는 다음과 같습니다:
- 에이전트 기반 데이터 합성(Agentic Data Synthesis): 모델 스스로 오류를 확인하고 수정 지침을 내리는 고품질의 멀티턴 추론 데이터를 생성합니다.
- 순차적 사고 스케일링(Sequential CoT Scaling): 단순히 여러 번 시도하는 병렬 샘플링보다, 이전의 결과를 바탕으로 점진적으로 개선하는 순차적 방식이 훨씬 더 효율적임을 입증했습니다.
- 일반화 능력: 짧은 훈련 궤적만으로도 테스트 시에 더 긴 추론 단계를 수행하며 성능을 높이는 ‘Zero-shot’ 형태의 일반화 능력을 보여줍니다.
 Figure 1: UniT 프레임워크를 통해 나타나는 창발적 인지 행동과 테스트 시간 스케일링의 효과. 순차적 CoT 스케일링이 병렬 스케일링보다 월등한 성능을 보입니다.
Figure 1: UniT 프레임워크를 통해 나타나는 창발적 인지 행동과 테스트 시간 스케일링의 효과. 순차적 CoT 스케일링이 병렬 스케일링보다 월등한 성능을 보입니다.
2. 연구 배경 및 문제 정의 (Introduction & Problem Statement)
2.1 통합 멀티모달 모델의 한계
GPT-4o, Chameleon, LLaVA와 같은 최신 통합 멀티모달 모델들은 텍스트와 이미지를 하나의 공간에서 처리할 수 있는 강력한 능력을 갖추고 있습니다. 그러나 이들은 대부분 ‘단일 통과(Single-pass)’ 구조를 따릅니다. 즉, 한 번의 추론으로 즉각적인 답이나 이미지를 내놓아야 합니다.
하지만 현실 세계의 복잡한 작업들은 한 번에 해결되기 어렵습니다. 예를 들어, “강아지가 목줄을 차고 공원에서 뛰고 있는 그림을 그려줘. 단, 목줄은 빨간색이어야 하고 배경에는 분수가 있어야 해”라는 명령이 주어졌을 때, 모델은 종종 특정 요소를 누락하거나 공간적 배치에서 실수를 저지릅니다. 기존 모델은 이러한 실수를 스스로 인지하고 수정할 기회가 없습니다.
2.2 왜 멀티모달 추론 시간 스케일링인가?
언어 모델에서는 ‘생각할 시간’을 주는 것이 성능 향상의 핵심임이 증명되었습니다. 멀티모달 영역에서도 다음과 같은 세 가지 능력이 결합된다면 비약적인 발전이 가능합니다:
- 검증(Verification): 생성된 결과가 원래 의도에 부합하는지 스스로 판단.
- 하위 목표 분해(Subgoal Decomposition): 복잡한 명령을 단계별로 나누어 해결.
- 내용 기억(Content Memory): 여러 번의 수정을 거치면서도 핵심 객체의 정체성(Identity)을 유지.
UniT는 바로 이 지점을 공략하여, 이미지 생성과 이해를 넘나드는 반복적 프로세스를 모델 내부에 이식하고자 합니다.
3. 핵심 기술 및 아키텍처 심층 분석 (Core Methodology)
UniT의 정수는 ‘어떻게 스스로 학습할 데이터를 만들고, 이를 어떻게 효율적으로 추론에 적용하는가’에 있습니다.
3.1 에이전트 기반 데이터 합성 (Agentic Data Synthesis)
학습을 위한 고품질의 ‘수정 데이터’는 현실적으로 매우 희귀합니다. 연구진은 이를 해결하기 위해 세 가지 모델의 상호작용을 이용한 에이전틱 루프를 구축했습니다.
- Actor (Generator): 초기 이미지를 생성합니다.
- Verifier (VLM): 이미지와 프롬프트를 비교하여 누락된 요소나 오류를 찾아냅니다.
- Planner (Reasoning Model): 오류를 해결하기 위한 구체적인 수정 지침(Thinking Tokens)을 생성합니다.
이 루프를 반복하면서 생성된 [생각 -> 행동 -> 검증]의 궤적(Trajectory)이 UniT 모델의 학습 데이터가 됩니다.
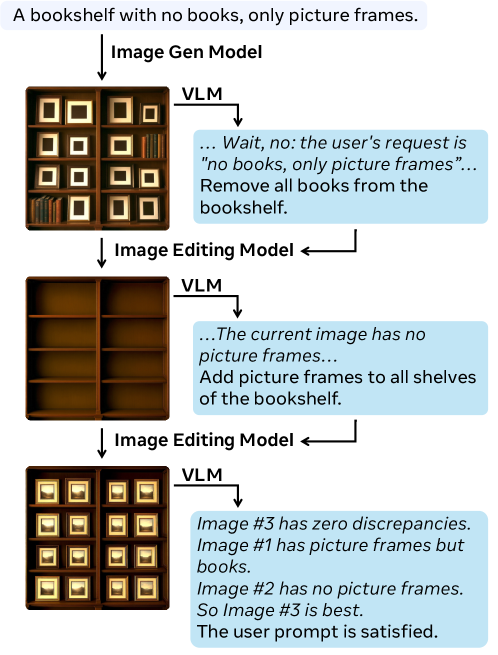 Figure 2: 데이터 합성을 위한 에이전트 프레임워크. VLM이 검증자가 되어 이미지 생성 모델의 오류를 지적하고, 단계별 수정 계획을 수립하는 과정을 보여줍니다.
Figure 2: 데이터 합성을 위한 에이전트 프레임워크. VLM이 검증자가 되어 이미지 생성 모델의 오류를 지적하고, 단계별 수정 계획을 수립하는 과정을 보여줍니다.
3.2 사고 연쇄(CoT)의 통합: Thinking Tokens
UniT는 단순히 이미지만 생성하는 것이 아니라, 이미지를 생성하기 전에 <thought> 태그 내에 자신의 계획을 텍스트로 서술합니다. 예를 들어, “목줄이 빠졌으니, 다음 단계에서는 강아지의 목 부분에 빨간색 끈을 추가하겠다”라는 식의 논리 전개를 학습합니다. 이는 모델이 복잡한 공간적 관계를 더 잘 이해하도록 돕습니다.
3.3 추론 시간 스케일링 전략: Sequential vs Parallel
일반적인 스케일링 방식인 ‘Best-of-N’(N개를 병렬로 뽑아 가장 좋은 것을 선택)과 달리, UniT는 순차적 개선(Sequential Refinement) 방식을 채택합니다. 실험 결과, 똑같은 연산량을 소모하더라도 이전 단계의 결과물을 바탕으로 수정해 나가는 방식이 복합적인 제약 조건을 만족시키는 데 훨씬 유리함이 드러났습니다.
4. 구현 및 실험 환경 (Implementation Details)
- 모델 아키텍처: UniT는 대규모 비전-언어 백본을 기반으로 하며, 생성과 이해를 동시에 수행할 수 있는 디코더 기반 구조를 사용합니다.
- 학습 데이터: 합성된 궤적 데이터와 기존의 멀티모달 벤치마크 데이터를 혼합하여 학습합니다. 특히 모델이 스스로 멈출 시점(EOS for reasoning)을 학습하는 것이 중요합니다.
- 학습 효율성: 흥미롭게도 연구진은 평균 3.6라운드의 수정 궤적으로 학습시켰음에도 불구하고, 실제 테스트에서는 그보다 긴 4.7라운드 이상의 복잡한 수정 과정도 성공적으로 수행함을 확인했습니다.
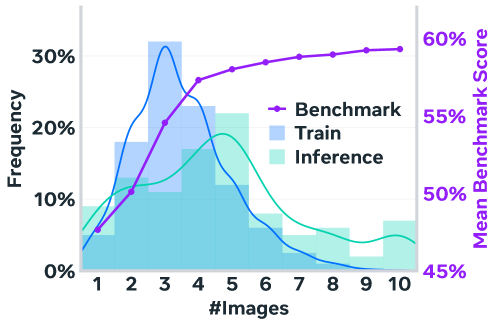 Figure 5: 훈련 단계와 추론 단계의 라운드 분포 비교. 훈련된 범위를 넘어서는 추론 단계에서도 모델이 성능을 발휘하는 ‘일반화 성능’을 확인할 수 있습니다.
Figure 5: 훈련 단계와 추론 단계의 라운드 분포 비교. 훈련된 범위를 넘어서는 추론 단계에서도 모델이 성능을 발휘하는 ‘일반화 성능’을 확인할 수 있습니다.
5. 성능 평가 및 비교 (Comparative Analysis)
5.1 시각적 구성력 (Compositional Generation)
UniT는 기존의 단일 통과 모델들이 자주 실패하는 ‘객체 간의 관계’ 및 ‘속성 부여’ 문제에서 압도적인 성능을 보입니다.
 Figure 3: 오류 수정, 하위 목표 분해 및 품질 유지 사례. UniT는 라운드가 진행될수록 대상의 정체성을 유지하며 디테일을 정교화합니다.
Figure 3: 오류 수정, 하위 목표 분해 및 품질 유지 사례. UniT는 라운드가 진행될수록 대상의 정체성을 유지하며 디테일을 정교화합니다.
실험 결과 분석:
- 에러 수정: Bagel 모델 등이 실패한 목줄 위치 선정 등을 정확히 교정합니다.
- 일관성 유지: 여러 라운드를 거쳐도 곰이나 스케이트보드 같은 주요 객체의 형태와 스타일이 무너지지 않습니다.
- 품질 보존: 반복적인 편집이 발생하면 화질이 저하되기 마련인데, UniT는 오히려 아티팩트를 제거하고 세부 묘사를 강화합니다.
5.2 정성적 결과 분석
다양한 계산 예산(Compute Budget)에 따른 결과 변화를 보면, 더 많은 라운드를 할당할수록 이미지가 사용자 요구사항에 완벽하게 수렴하는 양상을 보입니다.
 Figure 4: 추론 시간에 따른 단계별 개선 예시. 모델이 명시적인 CoT를 통해 어떻게 점진적으로 완성도를 높이는지 보여줍니다.
Figure 4: 추론 시간에 따른 단계별 개선 예시. 모델이 명시적인 CoT를 통해 어떻게 점진적으로 완성도를 높이는지 보여줍니다.
6. 실제 적용 분야 및 글로벌 파급력 (Real-World Application & Impact)
UniT의 기술은 단순한 연구를 넘어 산업계 전반에 큰 변화를 불러올 수 있습니다.
- 전문가용 디자인 에이전트: 그래픽 디자이너가 AI에게 “이 부분의 조명을 좀 더 부드럽게 하고, 오른쪽의 화분은 장미로 바꿔줘”라고 말하면, AI는 전체 구도를 깨지 않으면서 해당 부분만 논리적으로 수정할 수 있습니다. 이는 기존의 ‘다시 생성하기’ 방식보다 훨씬 효율적입니다.
- 복잡한 의료 데이터 분석: 의료 영상에서 미세한 병변을 찾을 때, 모델이 “먼저 폐 전체를 스캔하고, 의심되는 구역을 확대한 뒤, 혈관과의 관계를 분석하겠다”라는 사고 과정을 거치면 진단의 정확성과 신뢰도가 크게 향상됩니다.
- 자율 주행 및 로봇 제어: 로봇이 복잡한 환경에서 임무를 수행할 때, 실시간 시각 피드백을 바탕으로 자신의 계획을 수정(Refinement)하며 행동하는 기반 기술이 될 수 있습니다.
- 전자상거래(E-commerce): 사용자가 원하는 가구 배치나 의류 코디를 반복적인 대화와 시각적 수정을 통해 완성해가는 가상 비서 서비스에 최적입니다.
7. 한계점 및 기술적 비평 (Discussion: Limitations & Critique)
최고 수준의 성과를 보였음에도 불구하고, UniT에는 몇 가지 비판적으로 바라볼 지점이 있습니다.
- 추론 비용의 폭증: 순차적 스케일링은 품질을 높이지만, 각 라운드마다 모델을 다시 구동해야 하므로 지연 시간(Latency)이 크게 증가합니다. 실시간 서비스에 적용하기 위해서는 모델 경량화나 캐싱 기법이 필수적입니다.
- 데이터 합성의 편향성: Verifier로 사용된 VLM의 수준이 합성 데이터의 질을 결정합니다. 만약 Verifier가 잘못된 판단을 내린다면, 모델은 ‘잘못된 것을 맞다고 믿는’ 혹은 ‘불필요한 수정을 반복하는’ 부정적인 패턴을 학습할 위험이 있습니다.
- 평가 지표의 주관성: 시각적 생성물의 ‘정확성’은 정량화하기 어렵습니다. 현재 사용되는 CLIP 점수나 VLM 점수는 인간의 심미적 기준이나 실제 물리적 정확성을 100% 반영하지 못합니다.
- 자기 수렴의 한계: 모델이 어느 지점에서 수정을 멈춰야 할지에 대한 명확한 기준이 부족합니다. 무한정 루프를 돌 경우 오히려 이미지가 과하게 변형될(Over-editing) 우려가 있습니다.
8. 결론 및 인사이트 (Conclusion)
UniT는 멀티모달 AI가 단순히 데이터를 매핑하는 수준을 넘어, ‘인간처럼 사고하고 교정하는 인지적 과정’을 모사할 수 있음을 증명했습니다. 특히 훈련 범위를 넘어서는 추론 시간의 확장이 성능 향상으로 이어진다는 발견은, 향후 멀티모달 모델의 발전 방향이 단순히 파라미터 수를 늘리는 것뿐만 아니라 ‘추론 연산량을 어떻게 지능적으로 배분할 것인가’에 있음을 시사합니다.
개발자와 기업 입장에서는 이제 단 한 번의 요청으로 완벽한 결과를 기대하기보다, AI와 협력하여 결과를 다듬어가는 ‘인터랙티브 멀티모달 루프’를 설계하는 것이 중요해질 것입니다. UniT는 그러한 미래를 가능케 하는 강력한 기술적 초석이 될 것입니다.
이 기술이 상용화된다면, 우리는 단순히 ‘그림 그려주는 AI’가 아니라, 우리의 의도를 끝까지 이해하고 완벽을 기하는 ‘디지털 파트너’를 만나게 될 것입니다.
